00:00:25.560
All right, so my talk is about a polyglot Heroku. I'm Terrance Lee, and I am the Senior Ruby Engineer at Heroku. That basically means I run the Ruby experience on Heroku. When you push an app that is Ruby-related, the entire process related to Ruby is my responsibility. I ensure that frameworks like Rails work properly on the platform. You can find me on Twitter at @TerranceLee, GitHub at github.com/terencelee, or email me at [email protected].
00:01:07.759
One of the first things I want to talk about is that last year we announced a new stack in beta called Cedar, which brought a lot of major changes compared to Bamboo. Cedar added a lot more flexibility to the platform. One of the major updates was the new way to specify process types. Before Cedar, you were limited to this Dyno worker model, which only allowed you to run a worker that executed rake tasks and background jobs. To run something like Rescue, you had to create an alias in your Rake file. For the web process on Bamboo, you were restricted to a single Thin server that we ran for you.
00:01:52.240
On Cedar, you can now specify all the different process types you want by simply listing the process type name followed by a colon and the command that should be run. For example, if you want to run a simple Mongrel server, you would use the command 'bundle exec mongrel'. Additionally, you can specify different types of workers like Rescue workers and set up cron processes. This makes it quite easy to define multiple process types.
00:02:42.599
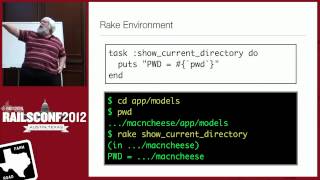
Prior to Cedar, we also faced issues with logging. One of the complaints a few years ago was that obtaining logs was difficult, as it only displayed the last hundred lines or so. We realized the need for a better way to aggregate logs, so we implemented a new logging system that is now enabled on every app. You can stream your logs by using 'heroku logs -t', and we treat logs as streams. Additionally, you can use the 'heroku ps' command to specify specific process types for which you want to see logs.
00:03:02.480
In Cedar, we also improved handling for common commands. In most Rails apps, you typically need to run 'rake db:migrate' to migrate your database. There's a special hook in place to allow you to run 'heroku rake db:migrate'. Previously, to run a Rails console, there was a middleware that was injected at compile time that allowed HTTP requests to pass through to your Dyno. This meant you could alter environments and configurations live, which was problematic. Now on Cedar, we have 'heroku run', which allows you to execute one-off processes that spin up an entirely separate Dyno isolated from your running processes. You can run a console, execute migrations, or even run a bash shell to explore your app.
00:04:36.560
One of the most noticeable changes in Cedar is that we have gone polyglot. Initially, we started supporting Node.js, followed by Java, Python, Clojure, Scala, and even Ruby. There has been some concern that supporting multiple languages fragments resources within the Ruby community, but there has been significant work done to improve the platform overall through this expansion. One outcome of this effort has been the development of buildpacks.
00:05:12.400
A buildpack is a language-specific component of the build process. Previously, we had a slug compiler, which generated a slug that was pushed to S3 and pulled down during Dyno boot. That slug contained all the necessary assets and dependencies. In the old Bamboo and Aspen days, Ruby code was integrated directly within the slug compiler. One of the first things I did was separate the Ruby components into their own buildpack. This separation made supporting additional languages, like Java, significantly easier.
00:06:06.000
The power of buildpacks allows for creative implementations. For example, I created a NES buildpack, where you simply provide a directory containing the ROM files. Create an empty Git repository, add your changes, make a commit, and then create a new Cedar app where you specify the buildpack. When you push, if we detect that buildpack URL, we fetch and execute that code instead of the standard Heroku buildpacks for Node, Java, Python, or Clojure. In this NES app case, the buildpack detects it and runs the NES application, allowing you to play games like Teenage Mutant Ninja Turtles on your browser.
00:08:15.399
Let's step back and look at a more basic buildpack I created, which is a no-op buildpack. This simple buildpack just takes your Git repository and turns it into a slug without any modification. It doesn't install dependencies or make any changes. Building a buildpack generally requires three steps. The first step is the detect phase, where we determine the name of your buildpack. In built-in Heroku buildpacks, there are mechanisms to determine if the buildpack should be used. However, for custom buildpacks, you'll need to define the name directly.
00:09:13.680
Next, during the compile phase, we don't perform any operations because we want to retain all files in the Git repository. Slug compiler handles a lot of the backend work before passing onto the buildpack, and we avoid modifying the Git history. Lastly, we have the release phase, where you specify commands to set up any add-ons, environment variables, or default process types during the initial push.
00:10:30.679
Now let's take a look at what happens during the Ruby buildpack. To determine if an app is a Ruby app, we check if there is a 'Gemfile' present. This allows us to differentiate between Ruby apps and those using other languages, such as Node or Clojure. For Rack applications, we check for the presence of 'config.ru', and in Rails 2, we look for 'config/environment.rb'. In Rails 3, we examine the application file to make sure the appropriate environment is defined.
00:13:34.639
The compile phase for Ruby is much more intricate than for the no-op buildpack. If a custom Ruby version is specified, we install that, set up the language pack environment, and configure paths to ensure everything is aligned correctly. Installing the appropriate gems is also critical, and we always install 'bundler' to ensure desired gem versions are available. Following that, we install any required dependencies and create a database configuration file if necessary.
00:14:54.000
One significant change in Cedar compared to Bamboo is that we no longer automatically install add-on plugins. Previously, we set up add-ons like New Relic automatically for new users. While this was beneficial for new developers, it posed challenges for more advanced users who wanted to customize configurations. Now we only provide environment variables and documentation, allowing developers more flexibility without unnecessary magic behind the scenes.
00:15:45.720
During the release phase, we set up the language pack environment again to ensure everything is prepared correctly. We check for Rails apps or if the PG gem is present to set up a shared database. Environmental configurations are handled here as well, including ensuring default process types are established depending on whether it's a Ruby, Rack, or Rails app. This new structure makes it easier to manage dependencies and updates.
00:17:08.320
Recent efforts at Heroku have also included significant investment in the Ruby community. Notably, we hired Matts, who is focused on improving Ruby directly. Additionally, we brought on Koichi, who contributes a wealth of experience, and Richard, our Ruby evangelist. Before these hires, there were zero full-time Ruby developers at Heroku, so now we have a dedicated team working to improve Ruby and our integration with it.
00:18:40.720
Out of this focus has come contributions to the Ruby ecosystem, such as the bundler 11 release that came out two months ago. We made a concerted effort to improve performance, particularly reducing the time it takes to install gems—previously around 18 seconds for a simple gem install. With bundler 11, we can now fetch from API endpoints, cutting that down to about three seconds.
00:19:40.679
We're not stopping at bundler 11. We're actively working on bundler 12, which includes features especially requested by developers for better local development. This includes features that allow gem developers to integrate seamlessly with local gem development, ensuring that changes can be easily deployed. One feature we're focusing on is multi-version Ruby support. Many developers want to know when they can use Ruby 3 on Heroku, and we're hoping to have this support available soon.
00:20:56.159
Alongside the development of bundler, I've also been focused on improving the Rescue library. There are misconceptions that Rescue is not actively maintained. We are indeed focused on ensuring that Rescue continues to evolve with features like New Q and multi-Q classes, plus support for threaded and forked consumers. These improvements are aimed at addressing memory usage during processing and enhancing performance for heavy I/O jobs.
00:22:50.120
This year, I've concentrated on making significant improvements in the code base to support various encoding formats, allowing different types of serialization to be implemented. This gives developers more control and flexibility over how jobs are managed in the queue. Within the implementation, we introduced features to use either a blocking pop or a non-blocking mechanism, making it easier and more efficient to retrieve jobs as they come in.
00:26:01.360
I wanted to keep this brief since it's the last session of the day. Let's open the floor for any questions about Heroku or general inquiries related to Ruby or Rails development. (audience questions and answers follow) For example, one question discussed managing signal responses with Unicorn and Nginx to ensure proper shutdown procedures for Dynos. Another audience member wanted clarification on how dynamic routing works within Heroku's infrastructure and the interaction with caching layers.