00:00:24.960
Welcome everyone! My name is Josh Kalderimis. If you care to try to give it a whirl, you can find me on Twitter and, of course, on GitHub. I contribute to Rails and look after a bunch of gems. I come from Wellington, New Zealand, which is known for its beautiful scenery, fantastic coffee, and amazing wind. I have been on one of those planes before while it was landing, and it’s very funny because as you're coming down, you can see the runway, the hills, and everything below. I now live in beautiful Amsterdam, which is known for our amazing use of bikes, fantastic architecture, nightlife, and recreational activities.
00:00:54.400
I work on a project called Travis CI, along with my cohorts, Finn, who started this, and Constantine. We normally talk about rainbows, unicorns, and love on the beach, but today it’s just me. Before I get started, I actually want to give a huge thanks to two people or companies. Firstly, to Site5, which is actually sitting down here at the front, for helping me get here by sponsoring my trip to RailsConf.
00:01:13.410
On top of that, if you're a Ruby developer looking for a job, shameless plug: go talk to them. Additionally, I want to thank Engine Yard for helping Constantine get here to accept his Ruby Hero award. Without the support of these companies, we wouldn’t be here today. Now, I want to talk about deconstructing Travis.
00:01:32.740
This talk is about how we started as a project, how our infrastructure has grown, and how this has affected new features. I also want to explore what the future holds for Travis CI. For those who don’t know, Travis CI is a distributed continuous integration system for the open-source community. Can I ask everyone to do me a favor? Since I don’t have a gigantic, filled room, can you all stand and put down your laptops for a second? I’m sure you can find some space. Awesome! Just after lunch, we need to get some blood pumping.
00:02:20.110
I want you to stay standing if you test your code. Don’t be afraid, there’s always one or two! Alright, everyone is perfect. Now I want you to stay standing if you work on open source. It could be a commit or a little piece of documentation. Just if you contribute to open source—okay, cool! That's an amazing number, fantastic! I want you to stay standing if you use a CI server of any form; it could be at work or for open source. That's a bit scary.
00:02:46.259
Finally, I want you to stay standing if you test your open source code on a CI server against multiple Ruby versions and it's not Travis. Very cool! Great, thank you! This is a good start, this is what Travis is all about. It's to make sure we get more people standing right at the end. So, what is Travis? Unless you've been living under a rock for the last year, we run your tests whenever you save to GitHub. It’s free, it’s open source—anyone can clone it, anyone can try to run it, anyone can contribute. Travis CI is another piece of infrastructure for the open-source community.
00:03:40.209
We are for builds what Ruby gems are for libraries. We currently have just over 10,300 open-source projects using us, and this is tremendous. This is everything from Rails to OmniAuth to Devise to every small library you can think of. We do 5,000 builds a day. In the last month, we grew by 1,900 projects and dealt with 224,000 build requests from GitHub. We've performed a total of 720,000 test runs.
00:04:53.070
If you think about Rails, when they commit, that build or that request for a build gets broken up into 5 or 15 different pieces. In total, we've had 224 requests for a build that has resulted in 720,000 test runs, which is awesome! We support 11 different languages, everything from Ruby, Go, Scala, Closure, Node, PHP, and Perl. Last month, we had 6,000 page views, 40,000 visits, 22 or 23,000 uniques, and we sent 1,300 emails daily.
00:05:16.570
If you see this beautiful little image, it's a sign that someone is testing on Travis and they’ve been smart enough to put it in their README. This all started for fun; it was meant to be instant, live, modern, and hackable. Little did we know that Travis united two people back in 2011. This beautiful blog post was written, and you might not notice it immediately because it's quite small. In February 2011, a person with an interesting mustache wrote a blog post and is sitting right at the front.
00:06:27.430
There are rumors that this mustache continues programming at night while he sleeps. Other rumors say that if you rub the mustache, you get seven years of good luck! Very good! This mustache bought me a 'Shirt,' which is what I am wearing today. It’s company policy to own one of these shirts, and now wherever we go, we have awful mustaches and shirt policy.
00:07:31.489
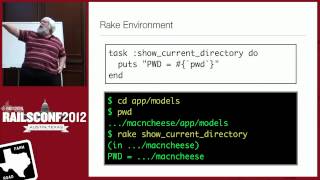
I want to talk about how we got started and what our infrastructure has grown into. How has it been for an open-source project to cope with this kind of demand—10,000 open-source projects and 720,000 test runs a year? How has that been possible? I want to tell a bit of a story. At the beginning, it was all about Travis CI. It just started with a simple Rails app with a Rake task and ran a built-in worker that used Resque.
00:08:06.230
If they both connected to a database, they could both communicate through a WebSocket, and this is kind of what the architecture looked like, with all these squiggly lines everywhere. We had a dedicated box, we had Heroku, and it just worked! However, there were two main concerns. It was both a worker and a web server serving web requests. As a project, it was growing in complexity with an ever-growing test suite and gym dependencies. Issues like SSH connections, Active Record models, and notifications were getting big rather quickly.
00:09:02.210
What we really wanted to do, as you can see here, was remove the tight coupling we had between our deployments on two different boxes of the same project. The first thing we did was separate the Travis worker, which is all about running build requests. It still used Resque, but it no longer used WebSockets or the database. It included an HTTP endpoint for communicating log updates to the website, which were then sent via WebSocket.
00:10:49.850
Now we had something like this, which was a big improvement. We had less coupling going on with a much better single responsibility. But anyone notice here? We had about two different repositories, which was a huge improvement. But I want to talk about the Travis worker specifically. Here’s the Travis worker we set up with a beautiful dedicated box, which is running hundreds of builds each day.
00:12:03.000
The first implementation of Travis worker didn’t include any sandboxing whatsoever; it was just running straight on the machine. Admittedly, artifacts were left over; we had database records and gems left over as well, along with the logs. What we really wanted was some form of virtual machine—something that we could throw away and spin back up afterwards. We needed a nice clean room environment, which wouldn't cost a fortune. We had the community sponsoring us and needed to remain lean and agile.
00:13:31.150
So we looked at the beautiful VirtualBox—this is awesome! You can run this on your home computer. There’s a great tool called Vagrant that makes it easy to spin up virtual machines. We put this in a dedicated box, and it was a huge win! We could have multiple workers in one box using VirtualBox, connecting with a one-to-one setup. While it worked perfectly, it wasn’t ideal. Then, Michael, who had been working with us via IRC for a long time, joined the team. He was brilliant and pointed us to Rabbit and AMQP.
00:14:45.350
For those who don’t know, AMQP is the Advanced Message Queuing Protocol. If you've run your builds or watched Travis, you might notice something called 'bundle install,' and each dot that appears represents a single test running. What was happening is that the worker was buffering what was being run and sending it up to the server. We realized that logging is kind of like messaging. We decided to remove the necessity for all these HTTP headers by implementing a consistent connection to a broker.
00:15:20.080
We took a risk! We decided to move to AMQP, use JRuby for the worker, and add a hub. This was a huge change. Now, we could add multiple boxes and multiple workers that ran multiple instances of VirtualBox, and they communicated with the Travis hub using RabbitMQ. The whole system listened to notifications from GitHub and sent all updates through Pusher. While the outcome was awesome, implementing everything all at once was not the smartest decision.
00:17:25.510
Going forward with those transitions was challenging because we found that smaller changes are definitely better. That process took three months of development for us. Although we obtained fantastic performance improvements from this infrastructure change, it was painful at first. However, things improved, and we started with an infrastructure based on Ruby 1.9.2 and WebSockets.
00:18:32.420
We moved to an infrastructure that uses two different Rubies—VirtualBox and RabbitMQ—and from one deploy to 23 deployable apps. But there’s room for improvement. If you look at the system architecture, you'll see that GitHub sends ping requests to Travis CI. Now, consider the scenario where Travis CI goes offline. What happens if we need to do an update, and something goes wrong? If it’s 30 seconds offline, or longer, none of those GitHub notifications can reach us.
00:21:23.660
Everything essentially comes to a standstill. Instead of the hub and worker working independently, everything relies on Travis CI. We considered this and came up with Travis Listener, a small Sinatra app with one concern: listening solely to GitHub notifications. We can now bring Travis CI offline for updates and keep Travis Listener up, which is fantastic! However, a new challenge emerged.
00:22:38.091
That challenge was that Travis Listener was still communicating with the database. If we wanted to run migrations and the database was unavailable, Travis Listener would throw errors. In fact, if we took the Listener offline during upgrades, we would miss GitHub notifications. To address this, we could just remove that connection, and Travis Listener became even simpler. It now just takes the payload from GitHub and posts it to RabbitMQ.
00:23:38.100
The hub works through that and treats it as a queue of tasks to process. This approach makes us happy again! If we take a moment to analyze that architecture, we see it resembles service-oriented architecture to some extent. For those familiar with that term, we don’t want to share resources too much—service-oriented architecture (SOA) encourages reducing sharing and coupling.
00:25:02.240
The pieces of services should communicate rather than sharing a single database. This change has resulted in increased reliability, scalability, and maintainability. It’s been a huge progression for a small project that started on GitHub under one person’s name and has now grown to about thirteen different GitHub repositories and four different deployable apps. But how can we share code effectively?
00:26:14.430
Travis CI serves the API for web requests and the Travis hub and they share a lot of common functionalities. Thus, we developed Travis Core, which encapsulates three main responsibilities: models, templates, and notification logic—things like emails and Pusher.”},{
00:27:30.130
Travis core's dependencies are simple. We rely on our Gemfile by requiring it in our applications. This flexibility now allows Travis CI and Travis Listener to use different Rubies: Ruby 1.9.2 on Heroku for CI because it’s simple and works well; meanwhile, on the hub and worker side, we can use JRuby.
00:28:44.550
Utilizing JRuby is beneficial as we leverage its garbage collection and a robust Java library, which is fantastic. With Bundler, it’s as simple as updating our Gemfile. This modular architecture ensures we’re in a good spot for adding new features. With a complex architecture now in place, we no longer have a single repo for people to easily point to.
00:29:37.220
We have various areas with different responsibilities. A recent addition is Pull Request support. Imagine you’re a Rails developer adding a fantastic new feature and submitting a pull request. On the other end, the Rails core team might hit the merge button and wait to see what happens with the tests. This leads to a complicated workflow.
00:30:49.210
The addition of Pull Request support affects almost every single part of our system, including the Travis Listener, Hub, CI, and Worker—everything needs to change. Some components can change independently, while others need to wait for modifications in other parts. For instance, on Travis CI, you need to change both the JavaScript and CSS to accommodate the new tab for pull requests. Models and notification logic also require changes in Travis Core.
00:31:55.800
Additionally, Travis Worker had to adapt to fetch the pull request from GitHub, check out the commit, and run the tests as usual. Meanwhile, Travis Listener must be configured to relay GitHub event types. It’s crucial to think before implementing changes because it prevents hastiness that can lead to problems further down the line.
00:33:16.519
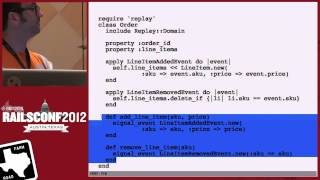
There’s so much excitement in implementing Travis Bot! This bot provides vital information on test results, which feed into the pull request timeline—comments, metrics, and status!
00:34:30.910
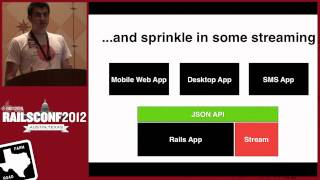
Looking to the future, Matthias, Constantine, and I have been discussing how we can scale the hub. Logs, being similar to streams, serve as a fantastic area for exploration. We’re considering the model of logs as streams rather than just messages. This transition, while enticing, brings complexities, including load balancing between multiple hubs.
00:35:12.420
In essence, the hub and worker need to operate more independently. One promising future direction is the potential move from a VirtualBox architecture towards a true VM architecture, enabling tasks like testing Rails on various operating systems. Finally, we plan to expand towards private repository support.
00:36:44.319
We've labeled this initiative Travis Pro and accepted a small number of testers. We hope to roll it out soon for everyone who has offered support. I’d like to express my sincere gratitude to all sponsors for helping Travis reach this point—every contribution matters. Finally, thank you all for your attention and support through this journey.