00:00:17.320
Uh, thanks for coming. I'm Eric Saxby. Today, I'm going to be talking about iterating towards Service Oriented Architecture (SOA). I may have time for questions at the end, but I may not; this might go 40 minutes, so I'm just going to get started.
00:00:24.640
If you're like me, you can't really pay attention to a talk about programming unless there are pictures of cats. So, really, we're going from this to something a little bit more like this, but working together as a family.
00:00:37.600
So, why should you care? Why should you listen to me? You may not know this, but I'm kind of a big deal. But really, I've actually not been doing this for that long. I've been doing Rails for about six years. Before that and after that, I have been using various different technologies. I've been fortunate to work with some very smart people, learn from them, and break a lot of things really quickly.
00:00:57.600
Right now, I work at Winow. I’m trying to collect all the buzzwords on my resume; I have more than just this. So, why is SOA important? We're like a social network for shopping. We have many millions of active users and databases with billions of records. We’ve gone through the pain of getting there and keeping the site running.
00:01:22.840
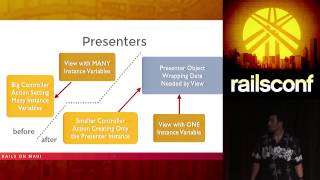
You can save any product from any store on the internet into your own collections and have your own wishlist. That’s what we do. More importantly, we've gone from having this as one main Rails application doing all of this to a central Rails application that's still fairly large but is supported by a lot of services.
00:01:46.159
We've done as much as we could to open source some of the business domain logic; it's really hard to open source, but we try as much as possible. We've done almost all of this in Ruby, including some things that people who prefer other languages say can't be done in Ruby. We've done this with a very small team and very quickly.
00:02:06.680
If you're like me, though, you’re really not that interested in the success stories; you’re interested in how we screwed up, how we broke things. Let me take you on a journey to another company that a friend of mine recently called the Anti-Pattern Gold Mine—a completely hypothetical company, not naming any names—where some of you in the audience may or may not have worked. After hearing some of the story, you might think you did.
00:02:44.599
It’s a startup, a new small team, and you come in and say, 'Wow, for a startup, you have a lot of tangled code. It’s all Rails codebase.' If you remember vendoring Rails, we did that. If you remember how vendoring Rails can go wrong, well, yeah, that was there. A lot of this might have come down to the fact that, at least early on, the success of a product or feature really was launching it as quickly as possible. No, no, no! Don't worry about that stuff; don't worry about design.
00:03:12.680
We had 30 engineers doing that as rapidly as possible—like five or six teams—all trying to get it into production, and releases were a mess. I’m sure a lot of you can relate to this. Deployments took multiple hours with all of these engineers trying to put all of this code in as quickly as possible. Inevitably, deployments went wrong.
00:04:03.959
Eventually, this got a little bit faster, going from monthly releases to weekly releases, but then we would have code freezes where, for three months, everyone was trying to cram in all the features without deploying. You can imagine where that goes—over time, things are just getting worse. We had rough estimates for how long things were going to last, and we would come back and say, 'Oh, that means you're deploying on this date—great!'
00:04:49.400
But with a deadline like that, the only real way to meet it is to make serious shortcuts. Then, as soon as a product finishes, because we’re invariably missing those deadlines, there’s the next project that is supposed to be out in a week based on the estimates you were supposed to do... The team gets dispersed to finish these new projects, and no matter how worst-case we are in our estimates, it’s just never worst case enough.
00:05:27.520
Some of you might be familiar with this story. Over the course of this journey, I think I’ve learned a lot. You know, programming is one of the most fun careers I’ve ever had, and when it’s not fun, you know something’s wrong. I kept reading about Service Oriented Architecture and many of us latch onto this, thinking this is the solution to all our problems—DevOps, that’s pretty cool over there! DevOps is the answer!
00:05:51.479
It’s going to be done; all we have to do is do some services, DevOps-y, and we’re done. Around this time, I moved into operations—not the operations team, because DevOps isn’t about just throwing things over the wall to the operations team and making it work. No, that's not the operation team at all.
00:06:34.480
A number of other people in the engineering team and I really decided that services are the only way forward. Product came to the conclusion that services were really just that thing getting in the way of us cranking out these features; new features are success.
00:07:12.560
At first, I thought you can take a firm stance, breathe deeply, and become the loudest person in the room; that really helps. Also, if there's anything I've learned from my cats, it's to throw something—you know, just throw it! It really helps in situations like this. We have a few things coming up.
00:07:34.760
These features aren't necessarily concurrent, but we have a new login feature. Login in this application is as homegrown as it could possibly be; it could go wrong. It’s a core functionality, and we were saying, 'No, no, no, no, no, that's not going in this code base. That's going to be a new application—that's going to be a service. It’s the only way we’re going to do this; otherwise, it’s going to fail!'
00:08:11.639
We also have this enterprise software, and we have a homegrown Rails application. All the data really needs to be synced between both for the company to actually work. We went through many iterations on this, but really this time, we were going to do it right. It’s going to be a data service!
00:08:56.640
We’re going to have our enterprise software and our Rails app, and that’s totally going to make this an enterprise Rails app; it’s going to be amazing! And I remember saying this a lot to many people: 'We’re going to screw this up. We know we're going to fail, but it's the only option we have to be able to succeed at some point in the future.
00:09:31.919
Okay, sidetrack—hopefully this isn't new to many of you, but there are many different ways to do Service Oriented Architecture. It can mean a lot of different things, and you get a lot of different ideas from reading blog posts. It can be synchronous, asynchronous—using a message bus. Maybe some services require actually hitting them over HTTP or TCP sockets. There are a lot of different ways of doing this.
00:10:14.360
But why would you really want to? To scale the organization, you have many teams and many engineers. Maybe you really want this team over here to have their own code base that they deploy separately. Also, perhaps you want to outsource this to a different team, and you really don’t want to give all the code to this other team. You want to isolate this and say, 'You guys over here, here's this.'
00:10:59.280
Sorry, I’m trying to avoid gendered pronouns from my vocabulary; it’s really hard—forgive me. You can also scale the codebase because the performance of this thing over here might be completely different from this other. This might actually make it easier in a service, as you can really tune the code to the workload.
00:11:38.759
You might have this complicated code that, for various reasons, needs to be. It might contain complicated functionality, but you could hide that behind a clean API. Tests are usually, but not always, associated with a smaller code base, which can lead to faster tests. If you're sitting around for hours waiting for tests to complete, it can eat into your productivity.
00:12:11.960
But it comes at a cost—all of this comes at a cost. I think one of the things I’ve been learning is that sometimes the cost of not doing this is greater than the cost of doing this. The cost of infrastructure, new servers, and how they talk together—it's really complicated, and things will go wrong. But sometimes not doing this means your productivity is just going down, and it can actually be more costly.
00:12:47.400
Okay, back to these projects. We have this data service—sometimes I think six engineers, sometimes eight. I don’t really remember the number—and nine months of work. It’s really complicated, like state transactions, and this is critical data that really needs to be done right.
00:13:34.560
At the time of deploying, there were some site data issues, but they were fixable really quickly. There were actually no major data problems, and there were some applications built on top of this data service. Depending on who you talk to, they were more or less successful.
00:13:53.520
Some people who used these applications said, 'Oh, thank you! This did exactly what I needed; it's actually helping with my workflow.' Others were just like, 'Okay.' But for engineering, we knew this was critical data, and it was really hard, totally new for us. This was a success; we did not break anything! But product was saying, 'Nine months with eight engineers—how could you possibly call that a success?'
00:14:30.760
A different application was the login flow. Depending on the timeline, we had two or four engineers plus the DevOps team over three months. Figuring out the automation systems was really tangled, and in a few weeks, we had some staging servers.
00:15:06.480
About two months later, someone came up to me and asked, 'Where are the servers going to be? Can we get those?' And I thought, 'Deep breath, deep breath; which servers?' Oh, those staging servers? But we worked it all out.
00:15:56.000
Something I learned about DevOps: everyone actually needs to be invested. It's new to people, and it was released with a feature flag. Only a small number of people were actually running through it, giving us a great time to break it in production and figure out how it was really going to run.
00:16:05.500
We launched it to all our users, and I would say it was very successful. It worked exactly as intended and was resilient to failures. We even had to do some unexpected database maintenance, but we decided just to restart the database.
00:16:35.760
We told ourselves, 'Don’t turn off the service; it’s going to recover, and maybe just one user will notice.' The company started to figure out that user metrics might be more important than release dates, and the user metrics were generally successful. Engineering said this is good!
00:17:10.400
But then Product said, 'Three months? What are you talking about? That’s not success! We had these other product features that needed to be done, and we had these four engineers sitting in the corner, unable to do these things.' So, I would say this is a really important question to ask: What is success?
00:17:53.040
If engineering says it’s a success and product says it’s a failure, who really wins? This is actually a trick question because it’s a zero-sum game; nobody wins in this interaction.
00:18:33.560
Let’s go a little deeper and ask why we needed SOA in the first place. This is really complicated; there are lots of moving parts. Some of the things I think now are because engineering didn't trust product. And what that really means is we didn’t trust we could do our jobs well, given the shortcuts we had to take to meet our metrics.
00:19:09.440
Product didn’t trust engineering either, as we couldn’t meet the promises we were given. Again, time would change this, but product was accountable for features, not for quality or how users interacted with them. This is likely a subject of much more discussion, and I would love to continue it and learn more myself, but I think a lot of this comes down to trust.
00:19:44.560
If you can't trust you can do your job successfully, how can you actually do your job successfully? If product and different parts of the company don’t trust each other to do their jobs well, how can they actually do their jobs well?
00:20:12.320
So, what did we learn? Next time, it should be SOA from the beginning. Before we even do Rails, we’re going to implement RabbitMQ. It’s going to be amazing, right? No—no, no, that’s not the right answer. Thankfully, I worked with very humble, empathetic people who are also quite convincing.
00:20:58.480
So, what I’ve really taken from all this is that agile isn't just one sprint after the next; it’s like four miles. It’s great to break it up into 100 meter increments. What's really important is iterating, deploying small things quickly, using the data from that to figure out what to do next.
00:21:46.440
Refactoring is really important. You might be able to do a small task quickly with some shortcuts, not really needing to know how it needs to be designed, but when you see a pattern, you have to fix it. SOA isn't going to solve larger organizational problems; it’s not going to fix your code. What it is is another tool at our disposal to solve our pain points.
00:22:39.480
How we do that is through iteration—small changes deployed quickly using feature flags. This allows you to get code into production as soon as possible, knowing it’s off and will not affect users, prioritizing this when it’s necessary.
00:23:17.760
So when might it be necessary? I would say performance drives a lot of our work—code complexity might be less in a service than it would be outside of one. If you have these two things and getting it over to a service makes it easier to deal with than trying to put it all in a tangled mess.
00:24:15.199
Also, if you have a new feature that is completely unrelated to everything else you’ve already done, it might be best to trust that when it becomes a problem, you will be empowered to fix it.
00:24:55.800
As I mentioned, performance is driving many of our discussions. We’re experiencing slowdowns, running into problems, discovering that the databases are becoming I/O bound on disk, which is a really bad place to be. User growth is increasing dramatically, and we observe exponential tendencies in our graphs.
00:25:27.760
When you see exponential tendencies in your user graphs, it’s kind of like giving a talk to hundreds of people—it's scary! One table is really outstripping the others and causing issues. We discovered through our data and graphs that this table is really hurting the performance of everything else.
00:26:12.920
We’re in the cloud, so we have all those buzzwords, but there’s a maximum size of a host we can get. There’s really an upper limit to how much we can actually solve this with one database, even after read-write splitting.
00:26:35.839
Soon, we realized the site was going to break if we didn’t do something; we wouldn't have a company anymore. But we have really active, committed users joining us, and this is not the time to stop feature development—now is the time to learn from our users, double down on what they’re doing, tweak our features, and find out what’s going to drive our business.
00:27:12.440
We only had ten engineers at this point, so we didn't have that many resources to work with. Our first step of iteration was realizing that this is one problem and asking how we can solve it. This is possibly going to become a service and how do we get to that point?
00:27:55.680
The first step is isolating the data. Active Record gives you associations like 'has many' and 'has one' which make joins between tables easier, but when you have a service, you don’t have joins. Those will have to go away, but it's easy to remove them. For instance, a product has saves. You can just take that where clause that Active Record was going to do with a join and pull it out.
00:28:33.760
Active Record also gives us ways of talking to a different database, but we can actually use this to pretend it’s in a different database. Establishing a connection allows you to have this model live in a database and all your stuff live in the main database.
00:29:07.760
One key thing is that each step of this, each slight change is deployable and testable. You can deploy it to staging, click around to see what your test coverage is, maybe figuring out where it’s missing and where things could potentially break.
00:29:53.199
You should know you might be doubling your database connections at this point; when your database hits the max connections, just everything stops—it just stops working. We learned this lesson the hard way. But now we have code deployed that pretends it’s in a different database; we can indeed make it a different database without much work.
00:30:56.000
Using Postgres, we love Postgres. We have a master database and spin up a replica; we put the site into maintenance mode. If you have more critical interactions with your company, that maintenance mode might not be possible. A service like BrainTree has good blogs and talks about this, but for us, the overhead of making this without site downtime was not worth it.
00:31:48.560
So we just decided to take the site down, push a new database YAML file saying now this connection is talking to this new database, promote that to master, restart everything, and bring the site back up. That gave us approximately five minutes of downtime— not that bad.
00:32:40.560
Afterward, you can clean up and truncate redundant tables carefully. Interestingly, at this point, you might not need a service, and your site may just be working. For us, we knew how things were going that we would have to horizontally shard this data; now it's in a different database, and we'd have to manage many databases as a result.
00:33:27.360
We want to hide that complexity; our main application can't contain that code. We know we will have a service, so we need to isolate the interface—by that, I mean how are you actually accessing this data and what is your long-term plan?
00:34:03.360
Ours is charting, as the product saves. Anytime we are saving, we access it either by product (a product has these saves) or by user (a user has saved these things). This is actually quite helpful for planning out how your DSL or API will look.
00:34:40.560
We know that we will eventually need to change Active Record into something that doesn't exist, and instead, a save has a byproduct method.
00:35:16.639
One thing I will say is that it’s really helpful to remove redundancy. If you have different ways of accessing the same data, do you really need that? You can change the product to mean you don’t have as many of these finders as you have, and very soon things are going to break.
00:35:59.480
If you don’t have tests, this is a great point to add them. So, now we have a small Ruby DSL. How do we actually pull that out? I’d say it doesn't need to be a service at this point; what you need is a client. How do you build out that client? This is where adapters come in.
00:36:49.599
We add a module—this could be a base class. Some of the reasons we thought we needed a module, maybe we didn’t need that; maybe we could have done it as a base class. But now, a save is a save client, and that save client is where your finders go as class methods.
00:37:38.560
One point I will make is that the finder calls through to an adapter (a database adapter) which is hiding all of your database calls from your application. One of the core principles here is that your database adapter is your feature flag—it’s also deployable in place.
00:38:15.440
You can have this in your lib folder, start a gem, and just deploy it. Your main application is still talking to this other database, but you are building out the client and later, when you have a service, you can replace it with a different adapter.
00:38:52.160
The adapter returns data when you call, for example, saved by product, and that returns a relation. So, when you call `by product`, you are getting back a relation instance, which is really important because Active Record does this for very good reasons.
00:39:29.360
If you ask for a specific type of data and you save it away to a variable, then call some other method to order it by, for example, and it changes state, you might do something unexpected later on that variable. Anytime you make a change, you really want to get back a new instance with a new state.
00:40:07.840
The key thing we learned is that relation is sharable between all of your adapters, so the actual work to get the data is done in your adapter. Your database adapter should be utilizing Active Record, if you choose to go that route. If you have another favorite database adapter, great!
00:40:51.360
So, when you call Save by product, you’re getting an adapter. The call to the adapter will return a relation, and calling `all` involves the adapter calling Active Record to get your data, takes out the attributes, and gives you back an instance of your core class.
00:41:36.960
You want to hide Active Record; you don’t want to get back an Active Record class. It's critical to deploy at this step because by this time, I guarantee you’ve made mistakes, and the cost of fixing them is really low.
00:42:22.240
Investing a lot of time trying to design your server and how it will interact, only to find out you made the wrong choice in the client, could mean you have to throw all that work away.
00:43:05.440
Now you have a client; now you need a server. At this point, whatever you want is fine—the cost of writing this is low because the server is the simplest part, and if you did it wrong or chose the wrong transport mechanism, you just build a new adapter.
00:43:42.960
Let’s reiterate why we should deploy by now: it’s because the client is much more complicated than the server. Your bugs lie within the client, not the server. The server will be dictated by the choices you’ve made in the client, so if you’ve made wrong choices and then build the server, you’ve built the wrong server.
00:44:34.000
We use Sinatra and OJ because it’s awesome; it just works and is small but useful. We thought we needed to move away from HTTP, but we’ve grown, and it hasn’t been necessary.
00:45:10.000
So, we use the service now, and that’s really a feature flag. You just write a new adapter that talks to the service instead of the database.
00:45:50.400
Now when you call 'by product', you get an HTTP call that goes through to the HTTP adapter, retrieving the JSON and pulling the attributes out, eventually giving you back your save class.
00:46:33.760
So, in retrospect, we've isolated the data, isolated the interface, started to build our DSL, and we've pulled that DSL out into a gem. Now that we understand better what this gem needs to do, we can launch the service and just build a new adapter.
00:47:16.840
If we had realized this was the order we needed to do things, we would have done it in two weeks. The first part was a day’s worth of work; the second part was around three hours' worth of work and deployed immediately.
00:48:13.320
The more challenging part was realizing we needed an adapter. At this point in time, not many people were talking about hexagonal architecture, but it’s actually quite useful. We use Sunspot for some of our Solar things, and we’re already accustomed to spinning up a Solar instance using a gem.
00:49:13.599
This can also be done for your integration tests, but for unit tests, we have tests around everything coming through this to make sure it behaves correctly. Having tests around a fake adapter could be helpful, as it allows it to save data in memory within your application.
00:50:10.520
Redundant tests are crucial; you might ask, 'Do I really need this test?' Yes, because one day, you can delete your redundant tests, but you want to be very confident that when you do switch over, it’s going to work.
00:50:56.640
Using Foreman and Subcontractor is very useful for managing such scenarios. Subcontractor is a gem that can help you switch directories and run commands in a completely isolated bundler environment. You don’t want to mix dependencies and the versions between your server dependencies and your main application dependencies.
00:51:54.160
What about a new app? If you’re spinning up something completely new, not just extracting an existing function, how do you iterate on something that doesn’t exist yet? One of the lessons we've learned from both this and our product development is to iterate.
00:52:34.880
Find a way to get to the smallest deployable version as quickly as possible. Whatever tool you use for deployment, you have to organize your code to enable easy changes and understand how each piece is different.
00:53:24.320
Feature flags are still important—do customers see this or not? You could also hammer your service with requests using Sidekick to siphon jobs of every request, ensuring you break it before releasing it to your users.
00:54:16.560
There are many ways to approach this with a small group of users to see how interactions feel. It’s useful to go through an entire process without worrying too much about edge cases or errors. Once you see how the interaction feels, use that to guide your design.
00:55:07.280
Let the feature drive your design; figure out patterns for how you need to organize your code. Do not just whiteboard everything thinking it will be perfect; production will inevitably destroy designs.
00:55:51.600
If something appears clever, it is often bad; complexity will come to you, so don’t seek it out—it’s evil.
00:56:26.720
In terms of takeaways, hexagonal architecture is really cool, but you don’t have to design it from the start. As long as everyone in your organization trusts that everyone can do their jobs, then you will work together to build an awesome product.
00:56:59.440
You can fix this later, and your product's needs ultimately determine where the boundaries are. Thank you! I actually have a few minutes for questions!
00:58:00.330
Questions?