00:00:00.000
Oh God, the music faded. I guess that means I have to entertain you now. Hold on, I need a photo. Everyone say thank you, okay?
00:00:14.969
So, every time I give a presentation, I get extremely nervous. When I get nervous, I keep adding slides to my deck, so I'm up to 217 slides. That gives me about 11 seconds per slide, which means I think I’m actually over time right now.
00:00:31.500
First off, I want to tell you that I am right, and I will tell you how I know that I am right. It's because I have the microphone, and you do not. So there is an easy way for you to tell whether or not you're right.
00:00:55.170
This talk is about implementing a compacting garbage collector for MRI. I wanted to keep in theme with the keynote talks. So, this talk is about a rather morbid subject. Actually, it’s not. What I really want to say is that we need a lettuce emoji. The reason we need a lettuce emoji is so I can type ‘lettuce pair program.’ Now I have to type ‘salad pair program,’ and people just say that doesn’t make any sense.
00:01:21.520
Anyway, I really love pairing; I think I go particularly well with a nice Merlot. Today, we're going to talk about exploring memory in Ruby and building a compacting garbage collector.
00:01:45.610
My name is Aaron Patterson, but I go by the name of Tender Love on the Internet. You may not recognize me in person; you might actually recognize my icon. I'm on the Ruby core team and the Rails core team, and I like to talk about Ruby and Rails stuff. So if you want to discuss those topics, please come and say hi.
00:02:21.430
I work for a small startup called GitHub, which is an online code hosting website. Our mission is to make collaboration easier. I really enjoy using Git.
00:02:34.870
But I do not want to force push that on you. Yes, I am still on 11 seconds per slide. I wanted to mention that we are hiring. Usually, I don’t like to put up hiring slides because we are always hiring. If we’re always hiring, does that mean we actually are hiring? Yes, we are!
00:02:57.220
But the important thing about this position is that it is extremely special. This position is to be my boss. I am NOT joking.
00:03:16.019
This is not a joke. Please write down that URL or type it into your computer. I was going to pause longer and have you fill out the application now.
00:03:35.190
So, I have two cats who help me write code. This is Gorbachev Puff-Puff Thunderhorse, and this is my other cat, SeaTac Airport facebook YouTube Instagram Snapchat. Please come say hello to me.
00:03:49.859
I also have stickers of my cat. If you don't know what to say to me, just ask for a sticker of my cat. I will give you one. Thank you for being here. I couldn't be here without you, and I sincerely mean that.
00:04:07.290
I mean that in two senses: first, I’m glad that you came to my talk. Second, I don’t think Ruby could exist without you. I don’t mean this in a vague way like ‘Oh, we’re all Ruby programmers.’ I mean this in a much more concrete way.
00:04:31.560
I want to call out some of the hidden sponsors of Ruby development. These companies don’t get enough praise or publicity in our community. I want to contrast them with non-hidden sponsors of Ruby development.
00:04:50.550
For example, all these companies support me: GitHub sponsors, Kuroko's, and other core team members. These companies are directly sponsoring developers working on Ruby or Rails, and they are the ones we think about when we talk about developer sponsorship.
00:05:10.770
I feel that the large sponsors of open-source development make us feel guilty because we think, ‘What am I doing for Ruby? What is my company doing for Ruby?’ This guilty feeling can be dangerous because it leads to a cycle of feeling bad about ourselves.
00:05:42.990
I want to introduce the hidden sponsors of Ruby so that you don’t feel bad about yourselves. The way I want to demonstrate this is by describing Ruby Central. Ruby Central controls rubygems.org and pays for all its hosting costs. This is how all of your gems are funded.
00:06:09.380
Now, how does Ruby Central get funding? They put on conferences like RubyConf and RailsConf. These conferences gain money from attendees like you, who pay to come. So I want to do something Matsuda-san does at RubyKaya, which is asking how many of you are here on your company's dime? Raise your hands.
00:06:39.910
That is a lot of you! Because your company is sponsoring Ruby development and infrastructure directly by attending this conference. So give yourselves a round of applause!
00:07:14.480
You should thank your boss. Tweet about it online and get some sponsorship going for your company! So if you’re ever wondering how to help Ruby, the easiest way is to be here, to be present, and to spread the word.
00:07:37.490
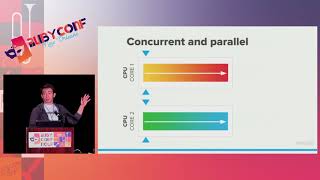
Let’s talk about some technical stuff. I want to discuss a mark-and-compact garbage collector. I’ve been working on GC at GitHub for a while and want to focus on improving copy-on-write performance with Ruby itself.
00:08:03.600
We’ll look at memory and Ruby and I hope to get through all these slides because I have a nice treat for you at the end—a lightning talk that I could not give at the lightning talks yesterday.
00:08:29.780
I want to cover three different topics today: copy-on-write, building a compacting garbage collector in MRI, and memory inspection tools. This is a pretty low-level talk, and I realize that there are many new people in the audience today, so I want to call out specific things for new people to learn.
00:08:56.420
New people, focus on understanding what copy-on-write is and what compaction is. You don’t need to know exactly how these things work, but keep them in the back of your head.
00:09:07.920
One day, when you hear these terms or you encounter related problems, you can remember them and know the keywords to Google later. Any of you attendees can understand what’s in my presentation; it may just take some googling.
00:09:31.470
Experienced people, if you already know these terms, I want you to focus on the algorithms and implementation details.
00:09:40.390
First, let’s talk about copy-on-write optimizations, or as we shorten it to COW. I always think about a cow when we talk about this. Copy-on-write means we don’t copy something until we write to it. Here’s an example using Ruby's strings.
00:10:11.930
We first allocate an initial string, and if we look at the size of that string, it’s slightly over 9,000. If we duplicate the string and look at the size, however, it’s actually 40, because the memory was not actually copied. But after we write to the string, you can see that the size of the second string is now over 9,000.
00:10:47.288
So we copied that string on write. We can do the same thing with arrays, though, unfortunately, we don’t do this with hashes. I’m not sure why it’s implemented this way, but that's how it works today.
00:11:06.640
Why can we get away with this particular optimization? When we duplicate something, if we copy it, there’s no observable difference between the copy and the original. Since there’s no difference, we don’t need to copy it until something changes.
00:11:32.639
This optimization isn’t just limited to Ruby; it’s used in many places, one being your operating system. The operating system takes advantage of this when you create multiple processes using the fork system call.
00:11:44.809
In Ruby, when we allocate a very large string and then create a new child process by calling the fork method, the fork method copies the current process to the child process. However, since nothing has changed between the parent and child processes, it doesn’t actually copy anything.
00:12:14.550
When we write to the string, the operating system copies the memory that changed to that child process, implementing copy-on-write.
00:12:37.550
If we imagine this string laid out in the operating system’s memory, the parent process contains this large string across many pages.
00:12:57.690
Typically, each page is about 4k, depending on your operating system. After the program forks, the child process will create pages that point back to the parent’s process.
00:13:23.480
When the child process writes to a part of the memory, only that page being written to is actually copied, rather than copying the entire memory.
00:13:59.460
When this happens, it’s called a copy-on-write page fault. We can use operating system instrumentation to find and measure these faults. To improve copy-on-write performance, we want to decrease the number of page faults.
00:14:19.720
Why is copy-on-write important to us? At GitHub, we use a forking web server, which means it creates a parent process with many children. The parent process handles multiple web requests.
00:14:49.790
If each child process loads a copy of Rails, we end up with three copies of Rails in memory. This uses a lot of memory and means that we spend time loading Rails into each child process.
00:15:23.100
If we load Rails in the parent process and then have all the children fork after that, all the child processes will point back to the parent’s copy of Rails.
00:15:43.540
This actually reduces our boot time because we only load Rails once and decreases memory usage since we have only one copy in memory.
00:15:59.360
This is how it works today if you’re using Unicorn in production, but this isn’t the type of optimization I’m interested in. I'm focused on reducing page faults, which happen when something writes to a shared memory page.
00:16:22.220
And, what mutates shared memory? The garbage collector. The collector changes shared memory, and during the mark phase, it would go through and cause your entire program to be copied to the child.
00:16:43.780
For example, if we have a parent process with objects in memory and a child process pointing at these objects, during the mark phase, the garbage collector goes through and writes a flag on each object.
00:17:17.370
Once the flag is written, the object could be copied to the child process, resulting in all objects being duplicated.
00:17:42.880
This was worsened when the operating system copied an entire page. This was solved with a technique called bitmap marking.
00:18:01.180
With bitmap marking, instead of storing that mark bit on each object, it actually stores those bits in a table off to the side. This table does get copied between processes, but it’s much smaller than all objects in memory.
00:18:23.560
Another unhandy element is object generation. Ruby has a generational garbage collector, meaning as objects get older, they age. We keep track of the generation, increasing the age each time an object survives a collection.
00:18:51.280
The oldest an object can get is three GCs old if I remember correctly, and this age is stored on the object itself. This results in a similar problem to the mark bit. Every time we do a garbage collection, if we increase an object's age, it’s written to and copied to the child process.
00:19:17.670
A workaround for this is a gem called Nakayoshi Fork. If you're using a forking web server in production like we do, check out this gem. It works on the principle that generations are bounded: when an object reaches age three, it does not go over.
00:19:41.410
Another principle is that objects created before calling fork are likely to get old. The solution is to run the garbage collector a few times before forking.
00:20:06.550
If you check the source of Nakayoshi Fork, that's essentially what happens: we run GC a few times and then call fork.
00:20:33.060
The garbage collector also writes to memory during object allocation. Allocating an object can cause memory to be copied from one process to another.
00:20:54.730
For example, if we have a parent and child process, the child allocates a new object. However, a Ruby object is smaller than a system page. Since we write to that page, the operating system copies the entire page.
00:21:22.370
To fix this problem, we can reduce the space used, which can be done through garbage collector compaction. Suppose we have a process with two pages; if we fork the process, both pages can potentially be copied.
00:21:45.440
If we move some of those objects around, only one of those pages with free space will be copied to the child process.
00:22:04.840
So, GC compaction simplifies the task of moving objects around until there is no empty space left. All space should be grouped in one area, and we aim for the program to work after moving these objects.
00:22:25.290
One reason for compacting is to reduce memory usage and another is that someone told me this was impossible last year at RubyConf.
00:22:49.180
I presented a garbage collection technique last year, emphasizing that moving objects was impossible. Koichi approached me afterward and inquired why I said that. I hadn’t tried it yet.
00:23:16.670
So, I had to try it, and it turns out that it is not impossible to move objects.
00:23:37.050
Let’s discuss a compaction algorithm called two-finger compaction. This algorithm has some disadvantages; it’s slow and moves objects to random places throughout memory.
00:23:58.500
However, it has one significant advantage: it’s easy to understand and to implement. The general idea of garbage compaction algorithms is to move objects and then update all the references.
00:24:18.870
Moving looks something like this: we have a heap layout with objects sprinkled with free spaces. Two-finger compaction uses two pointers called fingers.
00:24:39.490
The free pointer moves right until it finds free space, while the scan pointer moves left until it finds a filled space. When they find a matching pair, they swap them.
00:24:56.540
In this case, neither pointer needs to move as they’re already at a matching location. We then leave a forwarding address in the place where the object used to reside.
00:25:13.600
We continue this process until the two fingers meet. This part marks the end of the compaction process.
00:25:31.910
After compaction, the heap might look like this, with the string and symbol moved to different locations. We may need to update the references.
00:25:55.390
We start at the beginning of the heap, checking if objects have references. If they do, we find and update them. Once all references have been updated, we change the forwarding addresses back to free spaces and finish compacting.
00:26:14.090
All this code is open source; you can find it at this fork on GitHub. This fork introduces a new method, GC.compact, allowing you to manually compact your heap.
00:26:31.520
In the pseudocode, we load all of Rails and its dependencies. Then, we compact all that’s in memory and fork off our child processes.
00:26:53.240
I had to make several key changes to Ruby in order to implement this in GC. I introduced a function called GC.move that swaps two locations, and another type called T_MOVED_OBJECT for marking forwarding addresses.
00:27:19.370
I also created a function called GC.update_object_references, which updates multiple references. This function is the most complicated part of the implementation.
00:27:38.580
It has to consider the update of references for every type of object within the system, hence it works as a giant switch statement.
00:27:58.930
Now, not every object in the system can move. I introduced a table called a pin bits table. This was a crucial addition.
00:28:16.130
Until now, we stated that every object can move. However, when finding references to objects, we have to ensure that we can actually find and update them.
00:28:29.950
If we have Ruby and C objects involved, we must mark them properly to prevent move-related crashes.
00:28:51.160
The way we handle that is by implementing a function where a C object calls a Ruby object to mark it. This ensures we know the reference cannot move.
00:29:13.330
Now, we also need to reference global variables properly. The GC does not know how to update global variables in C when they reference Ruby objects.
00:29:34.520
In this case, we started applying heuristics to pin these objects as they were generated using certain Ruby functions.
00:29:55.920
Now, we have a situation where string literals also cannot move. Ruby compiles code into instruction sequences, turning literals into objects.
00:30:18.220
If the literal moves, the byte code needs to update its reference as well. This makes the situation difficult, as updating byte code is a complex task.
00:30:41.380
As such, apart from the objects marked with our BGC mark, hash keys, dual references, objects created with RB_define_class, and string literals, most objects can indeed move.
00:31:00.920
However, there is good news! Most of these cases can be corrected, except for the RB_GC mark case. In a Rails application, 46% of objects in memory can indeed move.
00:31:15.440
Before compaction, this represents a heap where red indicates unmovable objects, green indicates movable objects, and white is free space.
00:31:44.250
After compaction, the heap shows how the potentially movable objects were grouped together.
00:32:01.350
Now, let’s talk about inspecting memory. I’ll go through this quickly because I really want to show you my lightning talk at the end.
00:32:27.420
One favorite way to inspect memory is using object_space.dump. This dumps all your memory, is the easiest way, and the fastest way to understand how your Ruby program uses memory.
00:32:54.920
You can use this function to dump your heap into a JSON file, measuring things such as Rails boot time. The output will consist of one line per object with a JSON hash representation.
00:33:21.390
This format allows you to view the memory address of each object, their referenced addresses, and their size. This information is crucial for GC developers to understand the object’s memory locations.
00:33:45.540
Understanding this layout can help generate a graph of what objects look like in memory. Dumping the heap allows you to depict how it appears before and after compaction.
00:34:03.100
You can find this on GitHub as well, and there’s code you can use to create these graphs.
00:34:20.870
In the proc file system, you can find a lot of useful information, such as address ranges that calculate RSS and PSS of your program.
00:34:40.350
TL;DR; use PSS instead of RSS when we're using forking programs like Unicorn.
00:35:05.600
Let’s look at the GC compaction savings. After performing this analysis, we saw only about 150k bytes of savings, but that's on a small program.
00:35:25.750
Our testing needs to include much larger applications to give us accurate figures.
00:35:44.430
In conclusion, Ruby needs compaction for several reasons, one being that I previously believed it impossible. As Ruby developers, we must question the limitations and assumptions of what we can achieve.
00:36:15.520
Most things are possible if we try hard enough—specifically, if I try harder.
00:36:34.870
Thank you all for being here, and let’s give it up for Ruby!
00:37:06.520
Okay, I have two more minutes for my lightning talk! Let me share how I became extremely famous in Japan for one day...
00:37:28.040
I made a tweet with one character that received fifty-three thousand retweets and eighty-three thousand likes. I want to share how this unfolded.
00:37:54.990
My love for studying Japanese began because, back then, Ruby blogs were mostly in Japanese. I wanted to understand those contents.
00:38:21.250
Ten years later, I learned how to read those posts and share that experience. Japanese consists of three writing systems: kanji, hiragana, and katakana, plus romaji.
00:38:47.360
Interestingly, katakana is typically used for borrowed words, while the go-to phonetic sounds consist of 46 characters. Sounds can be ambiguous, as illustrated with characters in pronunciation.
00:39:16.130
Japanese sounds closely resemble English, making it easier for English speakers to pronounce them compared to German.
00:39:43.570
The unique point of the language is the evolution of its characters from pictographs to more defined scripts.
00:40:09.600
So, about my tweet: It refers to something simple—'to laugh,' translated as ‘w’ for laughter. It quickly escalated to fifty-three thousand retweets, blowing up unexpectedly.
00:40:30.660
While in Tokyo, my friend even asked the bartender if she had seen my tweet, which she actually had!
00:40:57.570
I humorously recommend people to avoid using this simplistic expression to improve their Japanese.
00:41:17.020
Moreover, this expression amusingly corresponds to an offensive term in Chinese culture.
00:41:32.960
Look up ‘grass mud horse’ on Wikipedia, and you will discover more about it.
00:41:51.970
In summary, learning foreign languages provides exceptional insights. If you want to start studying, I recommend Japanese.
00:42:06.780
Thank you for this engaging talk!