00:00:15.410
Hello everybody! I hope you enjoyed your lunch. I'm Andrew Louis, and I'm going to be talking about a personal project I've been working on for the last while. It's called Memex, and I'm going to explain what that is while going over the historical version and my version.
00:00:22.859
So, I'll start with some history. Usually at tech conferences, we don't cover much history, and if it is discussed, it tends to be about how the last technique from a year ago has become outdated. However, I'm going to talk about history that includes black-and-white photos, starting from the 1930s.
00:00:35.790
The character we're focusing on is Vannevar Bush. Here's a picture of him. He was an inventor and engineer at MIT, and he built some of the first analog computers. These were large mechanical devices that solved complex math problems, primarily calculus.
00:00:52.710
In the 1940s, everything shifted in American science because World War II happened. There was a reorientation of priorities as people were pressed into the war effort. On the homefront, there was also an explosion of information needed to support the war, leading to new bureaucracies and processes—rooms filled with people generating information.
00:01:12.090
Vannevar Bush faced a problem during the war. His job was to interpret scientific reports and make recommendations to the president. Every day, his desk was flooded with information that he had to read and understand. He famously expressed, "We're being buried under our own product." Technology allowed us to create more information than ever before, but we didn't have the tools to make sense of it.
00:01:30.540
When the war ended, Bush returned to engineering and published an essay proposing a device to solve these problems called "As We May Think" in 1945. He envisioned a device called the Memex.
00:01:48.420
Here's an illustration of the Memex, a simple-looking device the size of a desk, featuring screens on the top and microfilm inside. The Memex was meant to store all of an individual's books, records, and communications, all in one place.
00:02:06.420
You could search and navigate through your information using an innovative stylus for adding notes and drawings, a voice recorder for voice memos, and even a clip-on camera for adding photos. While this might seem like science fiction, it was a groundbreaking idea.
00:02:31.620
Vannevar Bush's contribution that resonates today is the idea of navigating information not through an index, but through association—like a graph. He believed that our brains navigate through memories in interconnected ways, and he theorized that machines could replicate this navigational ability.
00:02:46.050
Unfortunately, the Memex was never built. It remained a conceptual device confined to his essay. This is quite unfortunate, as it represented a visionary approach to personal information management.
00:03:03.540
A little about myself: I've always been interested in personal archiving. If there's any piece of information I've generated or seen about myself, I like to store it. This is my journal from fifth grade— I've kept track of my experiences since then. I have my old report cards, movie stubs, and even maps of my walks through the city before Google Maps. I've saved chat logs from high school, even though they aren't the deepest conversations. In this new digital era, we are inundated with personal history, and the overwhelming amount of information makes archiving it difficult.
00:03:46.420
While grappling with this issue, I considered the obvious solution might be to talk to a therapist. However, instead of doing that, I decided to use Ruby to build my own Memex. This approach allowed me to tackle the personal archiving problem.
00:04:02.440
The first step involved gathering data. This included my reading and browsing history via my RSS reader, browser, and eBook reader—records of everything I've consumed. It also includes things I like on Twitter, videos I watch, and music and podcasts. My GPS device records my location history, and my communications include emails and messages from Slack.
00:04:26.650
Along the way, I kept qualitative data such as journaling, annotations, and notes. I consolidated this large dataset into a single repository. Now, I'll conduct a live demo.
00:04:57.260
Last night, I had a nightmare that my demo wouldn't work, and everyone would walk out. So if anything goes wrong here, perhaps just check Twitter instead of leaving, and I'll get back to it eventually.
00:05:11.500
This is the basic screen. At the top, we have an active query, with the results displayed on a timeline alongside an overview of results over time on the left. Right now, the query is showcasing everything I’ve done on GitHub.
00:05:32.229
You can see a range of information— like tickets I've created. I can add another verb like 'liked,' so now it shows the repositories I’ve liked on GitHub. Now, let's visualize this. Everything's from my perspective; I'm in the center, linked to the repositories I’ve liked and the tags associated with them. For example, the 'Electron' tag is shared by multiple repositories that I have liked. I can use this graph structure to navigate my personal history. If I want to find everything related to Electron I've liked on GitHub, I can perform a traversal through the nodes.
00:06:32.090
As I execute the query, I can see all the repositories about Electron that I have liked. This technique can be applied for various queries, like my listening history—here's how I want to find songs by Aretha Franklin.
00:07:23.620
This query showcases every song I've listened to created by Aretha Franklin. Adding conditions narrows it down, showing all songs that match 'love' from Aretha Franklin that I've listened to. You can see how I navigate my history effortlessly. Another example is performing a search for 'Ruby,' which pulls up tweets, browser history, and even images where I tagged the term.
00:08:17.150
This allows me to search through my personal history by images and texts from tweets. I can also search for any messages sent or received that relate to Ruby, allowing me to go back to my early thoughts on Ruby and Ruby on Rails.
00:09:06.030
This exploration reconnects me with memories, making it feel like I am zooming back in time to experience those moments again.
00:09:50.670
In addition to personal communications, I have my bash commands and command line history. I often forget command syntax, and being able to find the last time I used a specific command provides context on what I was working on at that time.
00:10:55.140
The original intention of the Memex was about reading and gathering knowledge. Here’s a graph of my reading history over time— I've tracked the books I've read. Some people may want to analyze this data in terms of how it relates to their mood or productivity.
00:11:34.100
While I'm occasionally tempted by those aspects, the sheer power for me lies in the context— understanding how I arrived at my ideas and thoughts.
00:12:13.910
Now let's return to the slide overview.
00:12:26.060
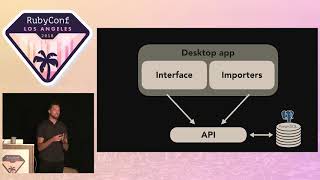
This application is built using Electron.
00:12:28.490
It combines the interface and the importers that run to collect data and communicate with an API.
00:12:38.470
There are two main API endpoints: one for reading, handling all the queries, and another for writing.
00:12:43.190
The importers have write-only access, importing personal history into a robust graph database called PostgreSQL.
00:12:55.640
The most challenging part of creating this system has been acquiring my personal data.
00:13:09.670
Often, there are no APIs available, like for Kindle where all the quotes and session data must be scraped. Even when APIs exist, they may not be user-friendly or well documented.
00:13:39.270
Take iMessages, for instance. They store data in a hard-to-decipher SQLite schema. I have to reverse-engineer this horrible structure to understand how to extract my messages.
00:14:11.920
And if it's a public API, it might not be reliable. For example, the Twitter API presents challenges, especially the favorites endpoint.
00:14:37.020
When favoriting a post, the record is sorted by published time rather than timestamped when I liked it. Therefore, if I favorited something from three years ago, pulling this data into a timeline becomes an arduous task.
00:15:47.740
Even for devices like Fitbit, they don't include timezone data, leading to inaccuracies when trying to compile activity timelines across different time zones.
00:16:34.430
Similar issues plague many service APIs. Instagram, for example, had a great API until privacy scandals made them deprecate it abruptly, leaving many developers without access.
00:17:04.180
YouTube experienced similar drama when it removed its viewing history endpoint without explanation. Despite GDPR regulations that allow users to export their data, these systems rarely offer formats that are user-friendly, forcing users to navigate overly complex data exports.
00:17:57.750
Take my Facebook messaging history. When I download an export, even the structure may change without notice, which creates chaos in how I can import that data into my system.
00:18:51.020
I often question whether I'm doing something that shouldn't be done. The tech world has not made it easy for individuals trying to collect their go personal data.
00:19:24.509
The first Memex also had its pitfalls. Back in 1945, computers were viewed as large machines, yet the proposed Memex was a desk-sized device meant for individual use.
00:19:52.930
Additionally, computers were primarily for institutions, solving significant problems— whereas the Memex was designed for personal tasks, making sense of individual information overload.
00:20:15.170
Bush argued that the Memex should function as a machine for the mind, facilitating personal insight and understanding.
00:20:35.060
This concept remains relevant today, inspiring the creation of tools that can empower individuals.
00:20:57.890
As Ruby enthusiasts, we have the potential to create applications that help individuals navigate their digital lives, expanding on the ideas that emerged fifty years ago.
00:21:36.120
I plan to continue working on this project and potentially share it as an open-source effort. Anyone interested should feel free to provide feedback.
00:22:06.489
Thank you for listening! If you have any questions, I’m happy to take them.
00:22:43.050
The question is about how the system captures what I ate. Most of it is automatically drawn from my phone and browsing history, though I manually tag specific details like who I ate with.
00:23:05.890
I use the system all the time, whether it's at events or meeting up with friends, as it enriches my experiences to refer back to this information.
00:23:32.740
This parallels keeping a journal, helping me understand how I have changed over time, and reflecting on previous thoughts.
00:24:04.440
It's an insightful tool, allowing me to identify specific habits, which in turn encourages self-improvement.
00:24:36.260
Regarding the architecture, my demo ran on a local version with an Electron app for the interface, while the API can run on Docker or a cloud instance.
00:25:04.280
More importantly, I aim to maintain individual control over the data rather than having a centralized database.
00:25:32.530
As for data growth, I record data at high frequency—tens of thousands of data points daily. I can filter and analyze this information to better understand my activities.
00:26:00.360
When it comes to security, while I've considered handling sensitive data with care, my approach remains based on the concept of trust in individual control.
00:26:41.170
Questions about privacy and potential misuse of an open-source version have crossed my mind. However, the goal is to create an environment that ensures user accountability.
00:27:21.850
To summarize: I constantly import data, running background scripts to ensure everything is recorded accurately and up-to-date.
00:27:52.970
Thank you for your patience. If you're interested, I welcome further discussions about this system, and feel free to sign up for updates.