00:00:15.619
Who loves getting paged at 3 AM? No one.
00:00:20.580
In responding to incidents -- whether at 3 AM or the middle of the day -- we want to feel prepared and practiced in resolving production issues. My name is Kelsey Pederson, and today I'm going to be talking about simulating incidents in production. A few months ago, I started my first on-call rotation at Stitch Fix, and of course, I got paged. I rolled out of bed, opened my computer, and immediately saw errors indicating that the application wouldn’t load. I needed to fix the issue quickly because our users rely on our software at all times.
00:00:55.410
However, at first glance, I struggled to find metrics on how many users were actually affected by this issue. After digging through logs and graphs for about ten minutes, I discovered on our custom dashboard that the problems were due to a dependent service being down. Unfortunately, that service wasn’t managed by my team, leaving me feeling helpless and uncertain about how to assist our users. Engineers often face this common problem: we're expected to support applications we don’t fully understand, and we don’t always feel prepared for these situations. We rarely have opportunities to practice our response tactics.
00:01:31.050
During on-call duty, the issues that arise can vary significantly, and we typically respond in real-time, aiming to resolve them efficiently rather than learning from them. This can leave us confused, stressed out, and feeling incompetent, which isn't ideal. Our jobs generally require us to do two main things: build new features that satisfy our business partners and maintain existing features. Unfortunately, because we often don’t feel ready or practiced in resolving these incidents efficiently, we struggle to excel in the support aspect of our roles.
00:02:07.020
Today, I will discuss how simulating incidents in production can help us improve our ability to build new features and support existing ones. As I mentioned, my name is Kelsey Pederson, and I work at Stitch Fix. Out of curiosity, how many of you in the audience have heard of Stitch Fix? Oh man, that’s amazing! It’s enjoyable to see an increasing number of people familiar with Stitch Fix.
00:02:44.620
For those who didn’t raise your hand and aren’t familiar with it, Stitch Fix is a personalized styling service for both men and women. You fill out a profile online, specifying your style, fit, and price preferences. A stylist, who curates clothing items, sends them to you. You try them on, keep what you like, and return what you don’t. My role at Stitch Fix is on our styling engineering team, where we build and support the applications that help our stylists select items for our clients.
00:03:06.980
It’s crucial for our applications to have high uptime, not only to keep the business functioning smoothly but also because our stylists rely on these applications to perform their jobs and get paid. Today’s talk will focus on two main themes: first, we will discuss injecting failure into our systems by simulating incidents in production. Second, we will explore the results of running these simulations and how to build more resilient systems as a result.
00:03:43.960
The concept of simulating incidents isn’t new. Many other professions conduct similar training and practice. For instance, firefighters go through extensive training to prepare and respond to various incidents before they are put on the job. Similarly, doctors undergo years of medical school followed by residency, where they practice procedures countless times before working with actual patients.
00:04:06.390
While engineers may not deal with life-or-death situations, we frequently practice incident response while supporting our applications on a daily basis. Today’s discussion will highlight the importance of making incident response a priority within teams, enabling us to develop more resilient systems.
00:04:107.840
Let’s take a step back and consider a few reasons why we might not already be practicing this. First, it can be unclear what benefits we actually gain from running simulations in production. Second, there’s the issue of time; we often have competing priorities, such as building new features and meeting business needs. We might experience pressure from project managers or other managers to prioritize those aspects.
00:04:47.450
Lastly, there’s often a perception that running simulations in production is complex and time-consuming. Netflix pioneered the concept of chaos engineering, which involves injecting failure into systems, exemplified by the idea of the Chaos Monkey. Some may view this as a very DevOps approach that falls outside their expertise.
00:05:06.950
Out of curiosity, how many of you have heard of the concept of chaos engineering? That’s great to see! As I mentioned earlier, chaos engineering was developed at Netflix five to seven years ago under the guidance of Bruce Wong. I’ll explain how chaos engineering works and how we implement it at Stitch Fix.
00:05:46.800
Chaos engineering involves a few key components. First is the scenario: determining what you are going to simulate in production and what failures you intend to cause. Scenarios can vary widely depending on the application, team, and company involved. Next is the team; chaos engineering requires gathering expectations, discussing what the team anticipates will happen when the simulation is run.
00:06:14.290
The third component is the game day itself, where the team runs the scenario together. Everyone involved typically joins a video call during this specified period.
00:06:32.040
Today, I will share our experience incorporating chaos engineering at Stitch Fix, a project I led with Bruce Wong's guidance and collaboration from several others. This is our first venture into chaos engineering at Stitch Fix, and I hope that by next year, our initiative can be adopted by other teams as well.
00:07:04.070
By the end of this presentation, I aim to walk you through nine different steps needed to carry out this simulation in production, equipping you with the knowledge to run a game day with your own team. First, we need to define what type of failure we want to simulate. This is often the most challenging aspect. My advice is to keep it as simple as possible, considering both the frequency and impact of potential application failures.
00:07:47.840
For example, most applications can experience some form of database failure. At Stitch Fix, we often face issues connecting to the database. Another consideration is flaky containers: how does the downtime of a single container affect users? Furthermore, we rely on third-party services like Braintree for payment processing and Zendesk for customer support—what happens if one of those services fails?
00:08:04.740
Additionally, we are transitioning to a microservices architecture, making our applications heavily dependent on internal services functioning correctly. Today, we'll specifically discuss this issue since it is particularly relevant to the styling engineering team and has implications for all engineering teams at Stitch Fix. We will define our simulation scenario as a service returning a 500 error.
00:08:56.640
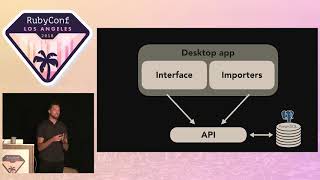
Next, we will implement code to enable our game day. There is a common misconception that chaos engineering is solely a backend or server-level task, but we can incorporate it at various application levels. Specifically, I’ll showcase how we executed this at Stitch Fix. We decided to inject failure at the middleware layer using Faraday middleware, an HTTP client library allowing us to modify the response received when requests are made.
00:09:24.300
To begin the setup, we created a new Faraday connection object. This object takes in an options hash to specify things like the URL and request options. Initially, this connection object serves a basic purpose as we move to write our custom middleware class. We called this class 'ResponseModifier,' which contains methods responsible for altering the response during the request process.
00:10:00.450
In our implementation, we override the 200 status code and replace it with a 500 error. This is a crucial part of the technical implementation that allows us to run a game day in production. Alongside this, we also needed to register our middleware.
00:10:34.470
What’s important to remember is that while we are introducing the chaos of simulating failures, we must ensure it doesn’t negatively impact all users. In Stitch Fix, we utilize feature flags to control this process. We created a feature flag called 'run_gameday' that specifies which users will participate during our game day.
00:11:08.840
We included a select group of users in this feature flag while conducting the game day, ensuring that not every user would be exposed to this simulation. The implementation method involved only modifying the response status code when the config option enabled the 'response_modifier' for those selected to participate.
00:11:50.720
Once we established our scenario and implemented the technical aspects, the next step was to gather expectations among our team. It’s critical to conduct this discussion before starting the game day to avoid biases that can arise from the actual simulation output. For our team, I utilized a simple Slack poll to facilitate expectation gathering, and we found that not everyone was aligned on what they anticipated would occur.
00:12:27.570
As we approached the game day, we emphasized the importance of huddling together as a team to discuss our expectations. In my remote team, we conducted this huddle through a video call, while teams in a shared location may choose to meet in a conference room. We also created a document to track our metrics before starting the game day.
00:13:15.890
This discussion about expectations was quite fruitful, especially in understanding the various viewpoints regarding how the application would respond. Questions arose about which pages would load, what the user experience would entail, what alerts we would receive through systems like PagerDuty, and how our metrics and dashboards would reflect the incident's impact.
00:14:00.820
Now, at step six, we are ready to run the game day. By this point, we have defined our scenario, implemented the code, gathered expectations, and discussed them thoroughly. As we looked at our timelines, we realized that we had spent nearly 40 minutes discussing various expectations and metrics before diving into the simulation.
00:14:40.390
When it was finally time to start the game day, we implemented a rake task to initiate the process, adding the relevant users to the feature flag that made the game day live. Now, the critical moment had arrived: would the application merely fail to load data, or would it crash entirely?
00:15:20.580
To the shock of everyone except for Aaron, the application completely crashed. It was a surprising moment for the team, and though distressing, we were appreciative that the test was happening behind a feature flag, allowing us to observe and learn without the incident happening in real-time production.
00:16:15.950
We encountered an error message stating, 'We are sorry, but something went wrong,' a typical Rails message. We reviewed our metrics and discovered alerts from BugSnag, confirming that our game day was functioning as intended.
00:16:49.050
As we analyzed the failed attempts through the application, we recognized that not all users had been paged, which was an interesting finding. This pointed to the need for greater frequency to ascertain a significant enough impact from the simulated incident—an area we hope to explore further in future simulations.
00:17:28.920
At this stage, we decided to conclude the game day since we had already learned valuable insights: our application is not resilient enough to handle a service returning a 500 error. We halted the game day, disengaging the users from the feature flag and ensuring the incident would not affect production.
00:18:12.510
In the remaining ten minutes of our game day debrief, we revisited our expectations, noting that Aaron was the only person to accurately predict that the application would completely fail to load. It was fascinating that this accurate forecast came from Aaron, the most junior engineer on our team. In contrast, senior engineers had different expectations, highlighting the diversity of perspectives in our team.
00:18:55.210
To enhance our future brainstorming sessions, we might consider running a private Google form poll so submissions aren't influenced by others. Our discussion encompassed what we learned from our simulations and the ways to document our findings.
00:19:39.290
In reflecting on our learning outcomes, we began to compile insights on how our expectations differed from reality and the metrics that could have been useful, but were unavailable at the time. This debriefing serves to inform our next steps, addressing what we can improve in our processes and documentation.
00:20:24.370
Another actionable item emerging from our discussion was the need to update our runbooks. I suggest using decision trees to visualize various possible outcomes. Questions like 'Did the app load?' and 'Can we view client data?' are essential to understanding our systems' resilience.
00:21:12.780
The next item to address is updating our dashboards. These enable us to gauge changes during incidents and verify whether metrics are effectively accessible to our team. We utilize DataDog for metrics but learned many team members were unfamiliar with dashboard navigation, indicating a need for greater discoverability.
00:21:55.470
To summarize, we've discussed defining simulations, implementing code to support these simulations, and gathering expectations within the team. During the game day, we should huddle and review expectations before launching the simulation.
00:22:38.770
Post-simulation, it's vital to reassess our expectations, document runbooks, and update our dashboards. Recollecting my experiences during my initial on-call rotation, I recall feeling confused and somewhat incompetent when issues arose.
00:23:03.870
During today's discussion, I've focused on the resilience of our systems from a technological perspective, but I believe it’s equally important to highlight the human element in these situations. Practicing incident response through simulations enables us to enhance not only our code but also our team's capacity to handle incidents effectively.
00:24:01.370
The core objective is to foster both technical and human resilience. Implementing these simulations will help create robust applications and more adaptable and resourceful engineers capable of managing incidents effectively.
00:24:36.470
Thank you.