00:00:16.160
All right, welcome! I am James Thompson, a principal software engineer at Nav. We are working to reduce the death rate of small businesses in the United States. If that sounds like something you would be interested in, please come and talk to me—we are hiring and looking for remote engineers. Today, I am here to talk to you about building for gracious failure.
00:00:38.420
How can we make failure something that doesn't ruin our days, nights, and weekends? I am not a fan of overtime; I have a personal rule that I will not work overtime unless I absolutely have to. The reality is that failure happens—it's unavoidable. We will have infrastructure go down, people delete production databases, and deploy services that they should not. So, we have to plan for failure.
00:01:04.639
We need to find ways to manage failure. That's the best we can hope for. We can never eliminate failure; none of us will ever write a perfect system. Therefore, we have to plan for our failures. We should identify techniques and processes that can help us make failure manageable. That's the goal. Now, I am going to share a few stories about failures that I have dealt with—these are from the not-so-distant past, specifically from the last year.
00:01:31.280
The first one I want to discuss is probably the most frustrating to me: the reality that we can't fix what we can't see. If we are unaware that something has gone wrong, it is incredibly challenging, if not impossible, to resolve the issue. If your users are your notification system for when something has gone down, unless you're an incredibly small startup, you're probably doing something wrong.
00:01:54.390
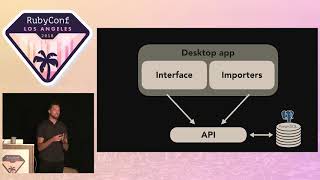
Visibility is the first step in managing failure. If we don't know that our systems are failing, we won't be prepared to respond. Instrumentation is one of the best ways to get the information we need to act on and prioritize dealing with failures. I recently changed teams at Nav and took over what is now called our data sourcing team. We are responsible for ingesting data from credit bureaus like Experian, Equifax, TransUnion, and Dun & Bradstreet.
00:02:25.220
This process can involve dealing with a lot of garbage, especially asynchronously. We have to deploy systems, jobs, and workers that can regularly update credit reports and fetch alerts from these various bureaus, compiling them in a meaningful way. We have a job processor written in-house, similar to Sidekiq, Rescue, or Delayed Job, but I noticed that our only visibility into what was happening came from logs.
00:02:46.080
We run this system in Kubernetes, so our number of production environments is not static—currently, there are about thirty instances of this application running. Collating logs from these thirty systems to pinpoint if something is going awry is not how I want to spend my time. I don't fancy the idea of sitting with a cup of coffee and scrolling through thirty services' logs, so I decided to find a better solution.
00:03:07.560
Within the first day, I chose to use Bugsnag because I didn't know how many errors we were generating. While I knew there were errors, I had no insight into whether we were facing an unusual volume or something that required more attention. By integrating Bugsnag, I transformed the overwhelming number of errors into a clearer picture of how many we had and their frequency.
00:03:38.440
However, I still didn't have a solid sense of whether these figures were typical or excessive. Thankfully, this was our staging environment, so I didn’t worry about delivering untested code to customers. However, seeing all these errors made it difficult to trust that code, and it raised concerns about deploying this service into production. Given the volume of errors I saw, that could lead to a horrible day for my entire team.
00:04:06.040
Having visibility into error occurrences is the first step in managing failure. We need to know what's happening, and tools like Bugsnag, Airbrake, or Rollbar provide that initial insight. However, I lacked sufficient information to determine whether these errors should be prioritized. I often found myself going to my product owner, trying to persuade them that an error was worth addressing, which is not an optimal position.
00:04:34.250
So, there’s another step in terms of visibility that is crucial: metrics. We recently deployed a metric tracking system that allows us to visualize the errors and their rates effectively. The graph shows that almost every job starting in our staging environment is failing. This realization meant I could no longer trust the code before deploying it into production if we couldn't even run it in staging.
00:05:00.660
Visibility is an essential aspect of managing failure. Before we can address any failures, we must visualize and track them, and logs alone do not provide enough actionable information. We need to start making errors and failures visible. This process begins by having a reliable way to discover and analyze failures so that we can determine their significance to the system.
00:05:35.560
If you are working in Ruby, you have many options for monitoring your systems; for instance, New Relic provides comprehensive visibility. Ensure that whatever systems you use, they give insights into when failures occur and whether those failures happen at an atypical rate. If you lack a suitable monitoring process, you may already be lagging behind.
00:06:09.960
The service I’m discussing is written in Go, and Go can be challenging in terms of implementing effective instrumentation, especially in concurrent systems. However, Ruby is straightforward, so please ensure your code is instrumented. Track metrics like how many jobs are starting and how many are succeeding or failing, as well as the number of HTTP requests and the different classes of error codes returned. By establishing these baselines, you can proceed to anomaly detection.
00:06:42.230
However, you need visibility and a baseline to employ anomaly detection effectively. If you leave today and implement Bugsnag, SignalFX, New Relic, or any similar solution that provides proper visibility, doing so will be a significant benefit for your team. It could save hours of firefighting when failures occur out of nowhere simply because you were not aware.
00:07:10.890
Now, I want to discuss techniques for making your systems more gracious in the face of failure—how the services we build can be more forgiving. One key aspect is getting into the habit of returning what we can rather than failing outright. I have another story regarding an unexpected error I encountered shortly after starting at Nav.
00:07:35.660
I was tasked with understanding how to build a new service called Business Profile, which keeps records of many small businesses, tracking various data points such as when they were founded, whether they are incorporated, their annual revenue, and whether they accept credit cards. The Business Profile service is responsible for maintaining a record of these fields over time.
00:08:01.860
Before I started, a prototype of this service had been deployed, but like many prototypes, it was abandoned and left in production. I had to decide whether we would maintain this service or start anew. I opted to start fresh, but a year into this decision, after migrating about nine million independent data points from the legacy system, we faced a problem.
00:08:26.170
As we transitioned services to rely on Business Profiles instead of the old prototype, we began to see 500 errors. These errors were coming because the legacy data included corrupt entries. While the migration from the legacy system had shown the data as valid, the new system was unable to parse them, resulting in errors. Fortunately, we tracked errors with Bugsnag and quickly identified the corrupt records.
00:08:51.260
The legacy system seemed to handle these strange strings well, but our new system could not. We could have returned a 500 error, but instead, I chose to add a rescue clause to capture this parsing problem. We decided that instead of failing altogether, the service should return null for the corrupt field while still providing all other valid data.
00:09:19.620
This enabled our service to return as much meaningful data as possible to its consumers. This is a crucial lesson; we must think about the values our systems can return gracefully instead of expecting all or nothing. In scenarios where variables are independent, returning whatever is available can provide substantial value. We should also consider if certain values can be optional, or better yet, if we can indicate which values are unserviceable.
00:09:46.500
Another key to graciousness in systems is allowing as much acceptance as possible. In the business profile service, we can accept updates where only some fields are provided—users can send a JSON payload with only the fields they want to update. However, we discovered cases where strings were sent instead of numbers, leading to failures on our end.
00:10:13.190
To adapt, we decided that if a user sends an input with the fields we expect and one value is erroneous, we will still store the correct values while notifying the user about the problematic field. This means we can accept whatever is valid while informing others what cannot be processed. Partial acceptance is preferable to outright rejection; we must consider which values within the data model must be correlated.
00:10:37.400
We can also think about how to enhance the resilience of our systems so they can handle unexpected changes and irrelevant data. Understanding the nature of data that we can tolerate allows us to embed better acceptability in our service design. It is essential to accept what is usable, and being flexible in how we interact with data from external services can improve our overall service quality.
00:11:05.750
Another key idea is to trust carefully. This applies to external third-party services and intra-service dependencies within your organization. Heavy reliance on other services can mean that their failures can effectively become your failures. In a recent incident, our Business Profiles service experienced problems not directly because of its faults but due to dependent services that forwarded 500 errors without attempting recovery.
00:11:29.770
When one service saw the error, it passed it along without interception or error handling. As a result, we faced an entire feature outage on our platform, highlighting how interconnected services can lead to widespread failures. It's imperative to build checks and resilience mechanisms to manage trust in these interdependent systems.
00:12:00.360
Understanding the limitations of trust in microservice architectures is necessary, as we often mistakenly assume all interacting services are reliable. This isn't always the case—prototypes can become production systems, and legacy applications can be problematic. As developers, we must assume failure is a reality, preparing to find ways to mitigate its impact effectively.
00:12:27.920
We need a mindset that not only considers infrastructure failures but also anticipates potential coding faults. We can adopt principles from chaos engineering, such as the chaos monkey, which helps us anticipate and manage failures. It's crucial to prepare for failure proactively so that we can avoid being caught off-guard.
00:12:52.470
We must help ourselves and our teams by building visibility and resilience into our systems, which allows us to pinpoint issues and causes early on. Once we identify these failures, we need to strategize on how we can make our systems more forgiving, tolerant, and effective in managing these failures.
00:13:19.410
At this point, I want to invite questions, as I've set aside time for that now. Keep in mind there is no mic circulating, so please feel free to speak up, and I will do my best to repeat your question and provide a response.
00:13:45.240
One question posed was about balancing the need for tolerance during data ingestion with the necessity to avoid letting garbage data into our systems. I believe this is really a business case. In the example I outlined with business profiles, we determined that some partial data was valuable, while we also agreed that we did not want to accept garbage data. Therefore, if we received incorrect types, we would reject that input.
00:14:07.640
The evaluation of whether to accept partial data or not must be done on a case-by-case basis, considering the demands and rules of each service. I do not recommend building systems that indiscriminately accept what is sent to them as that will lead to a proliferation of garbage data, causing issues down the line, especially for those relying on data integrity.
00:14:32.430
So, not accepting invalid data is critical. However, if individual values in a record don't have to be linked and can be treated independently, then we should accept whatever can be reasonably stored while rejecting the rest. Another audience member mentioned the concept of strong parameters in Rails for type checking, which is pertinent when discussing error handling.
00:14:55.900
In my experience, it is crucial to reject invalid data outright rather than accepting a blend of valid and invalid data. The service I'm discussing works in an environment where the values can stand alone, meaning even with partial acceptance, we can maintain the integrity of the record. Acceptability can vary but should always focus on maintaining data quality.
00:15:20.000
If we choose to return a partial response, it is essential to return a 200 status code. However, we also inform consumers that they should always check the errors parameter, which will indicate any fields that were not processed appropriately. Different approaches may apply based on the specific constraints and expectations of each system you are handling.
00:15:43.990
Our particular use case has not required us to roll back due to partial updates. Additionally, we typically update business profiles with data coming from bureaus or direct user inputs. In one scenario we faced, a user did not expect the service to handle their data in a partial manner and erroneously assumed that we would throw an error instead.
00:16:11.370
To address this, we ensured proper communication with front-end teams to clarify how the service operates. This is vital in systems where partial acceptance might rely on integrating multiple fields, so we need to inform other teams of testing processes and behaviors.
00:16:42.160
Another question revolved around distinguishing valid uses of our system versus someone trying to exploit its flexibility. I want to clarify that our Business Profiles service is quite insulated within our infrastructure; it is protected by several other systems managing access control. Our configurations help to ensure that while we maintain flexibility, we limit potential exploit scenarios.
00:17:06.540
We track metrics on failure situations to ensure we're aware of any issues that arise from data retrieval. For example, we have Bug Snag set up to get notifications contextually around errors, capturing relevant data to identify where failures come from. Keeping these records helps us understand the origins of corrupt values, many of which traced back to our migration process.
00:17:30.780
When it comes to prioritization after we gain visibility on errors and failures, it's essential to collaborate with a good product owner. They help weigh the business value and impact of each potential failure. It’s imperative for engineers to communicate what they know and work cohesively with product managers to ascertain which issues might require urgent attention.
00:17:49.610
Ultimately, fixing failures must be linked directly to whether it delivers new business value or restores lost value. A significant error might be pressing, just because we see a high volume of incidents, does not mean they will all require immediate action. By analyzing the data we gather, we can correlate urgency and importance to those errors.
00:18:14.260
Furthermore, to distinguish between errors worth addressing and those that can be considered background noise, employing metrics to weigh both frequency and severity becomes invaluable. Systems like Bugsnag offer insight on how specific errors affect users, but for a full understanding, tracking metrics and error rates is crucial to decide how impactful various failures are.
00:18:38.540
The more detailed the metrics, the clearer the scope of issues becomes. By utilizing different visibility tools alongside Bugsnag, we gain detailed insight into error significance compared to the total traffic volume passing through our services, which can significantly guide us in prioritizing bugs and improving our systems.
00:18:58.430
I believe we are out of time now. Thank you all for coming!