00:00:20.779
Good morning everyone! Welcome to "Death by a Thousand Commits." My name is Kyle d'Oliveira.
00:00:28.740
I am based out of Vancouver, British Columbia, Canada. If you’ve never been to the West Coast, specifically the West Coast of Canada, it’s beautiful! I highly recommend it. I am a staff software developer at Clio.
00:00:42.180
Clio is a 12-year-old SaaS-based company focused on making legal software to transform the practice of law for good. I work on their backend infrastructure team.
00:00:53.550
My team focuses on three major things: making our codebases scalable, both in terms of data set size and code size; making the codebases approachable, meaning we consider how long it takes for a new developer to onboard into a specific area or into the codebase in general; and lastly, we focus on the overall developer experience when working in all of our codebases. This means I think a lot about technical debt.
00:01:24.840
Over the seven years that I’ve been with Clio, I have seen various stages of how the company has handled technical debt, from ignoring it entirely to setting aside a bit of time to fix it while still letting it accumulate. Eventually, we reached a point where we strive to pay down all technical debt to improve future development.
00:01:49.380
I don’t know how many times I’ve looked at a piece of code and thought, "Who wrote this?" only to find out it was actually me from several years earlier. Technical debt is an interesting concept—it often doesn’t change the behavior of the system, so the business might not see it. What it does do is slow down development and potentially impact site performance, which the business does notice.
00:02:13.230
As developers, we need to advocate for time to address technical debt, explaining the risks and rewards of leaving it alone versus paying it down. The slowness can stem from developers being pulled off projects to address emergencies or from the need for more maintenance and optimization due to legacy code.
00:02:25.860
In 2009, Martin Fowler wrote a post about how technical debt is introduced into codebases. He created technical debt quadrants, with one axis representing deliberate versus inadvertent actions, and the other representing reckless versus prudent actions. In the reckless and inadvertent area, this occurs when people don’t know any better and face hard deadlines pushing them to move quickly.
00:03:08.129
At Clio, we’ve had instances where we deployed code in our API that we thought was right at the time, but years later it still bites us because we didn’t know and can’t get rid of it. When we move into the reckless but deliberate quadrant, people know better but still push forward, cutting corners and not worrying about the technical debt being introduced.
00:03:25.079
Sometimes it’s acceptable to be in this quadrant when speed is crucial, such as when being first to market is the most important. However, we ideally want to move towards the prudent and deliberate side, where we understand the consequences of the technical debt we are delivering and deal with it before any major consequences emerge. At Clio, we strive to be in this quadrant as much as possible.
00:04:15.790
We try to schedule time for cleanup immediately after projects. We believe that if we can deliver something a month early to gather user feedback and stabilize things, that’s a worthwhile approach. We can then use the extra month to clean up the project, as it isn't completely done yet, but users have it in their hands early.
00:04:52.000
Lastly, we might encounter an inadvertent but prudent category where you introduce tech debt unknowingly, but then use it as a learning lesson. It’s unreasonable for developers to know every way technical debt can be introduced and which ones will slow them down. As much as we want to be in the upper right corner of the quadrants, we often end up in the lower right and use these situations as learning experiences for the entire company.
00:05:28.540
Once technical debt is in the codebase, which is inevitable, we need two strategies for how to pay it down. The most basic strategy is being reactive, addressing consequences as they arise. This could occur when developers didn’t know technical debt existed or mistakenly deemed it an acceptable risk, which is now not the case.
00:06:06.400
For example, a database could become slow, and servers might struggle to serve requests, prompting the business to push developers to resolve this issue as soon as possible. Alternatively, certain situations could arise that cause customers to leave, escalating to the highest priority for developers and distracting them from their projects.
00:06:51.990
Alternatively, we could be proactive in identifying problems and tackling them before they become emergencies. This involves foreseeing potential problems, determining indicators of those issues, and monitoring them to gain warning signs when they may occur. If there are bad patterns we want to avoid in the codebase, we should aim to exclude them from day one rather than fixing them after we discover their presence.
00:07:35.820
It can often be difficult for businesses to understand the risks associated with leaving technical debt in place. Therefore, it is our responsibility as developers to advocate for time to fix these issues. Ultimately, we can also choose to invest in tools.
00:07:56.680
Investing in tools might slow you down initially, but in the long run, it greatly speeds you up. Sometimes the tools may have already been developed, requiring only a bit of research and setup. In other instances, they may not exist, necessitating that you build them yourself.
00:08:36.000
I would like to discuss four lessons we have learned at Clio that have helped us mitigate technical debt in our codebase. The tactics and tools I’ll share today may be directly applicable to your codebases, but I hope they prompt you to consider how you can tool away some technical debt present in your projects.
00:09:15.000
The first lesson is about addressing technical debt as it arises. You may wonder why you should fix technical debt when you could just find a way to remove it entirely. Imagine there’s a whole classification of problems you could address now so that future developers don’t have to think about them.
00:09:51.520
I want to share a specific instance at Clio where we noticed this lesson in action. There was a time when we had a controller endpoint that wasn't consistently fast. All our local tests and the tests on our staging servers indicated that this should be one of the fastest endpoints, but in production, it was one of the slowest. So, we began digging into what was happening.
00:10:39.330
We discovered that the endpoint was making hundreds, if not thousands, of database queries. It turns out that this endpoint had a multitude of problems, specifically with N+1 queries. For those unfamiliar, N+1 queries are a common issue in Rails and similar frameworks that use relational databases.
00:11:17.919
Essentially, the issue arises when you first query a collection of objects from the database—for example, contacts—and then attempt to access associations on those contacts. This results in individual queries being made for each contact. Each query has a small overhead and may be quick when executed in small numbers. However, when hundreds or thousands occur, it can significantly slow things down.
00:12:02.700
These issues do not usually influence end-user behavior, so they can be easily overlooked. Ideally, you should optimize your querying process to make two queries: one for the collection of contacts and another for the collection of emails associated with those contacts.
00:12:38.350
Let’s look at a code example illustrating how these issues can pop up in your codebase over time. Imagine we have a basic JSON API. Here's a simple controller that grabs some contacts and renders them as JSON, along with their names and IDs. If we use Active Model Serializers, our serializer might simply include ID and name. This allows us to have a functioning JSON API that returns all of the contact IDs and names.
00:13:29.710
In the future, customers might request that this API also return the emails of those contacts. If the model has the associations set up already, adding this field to the API is straightforward; you just add one line to the code. This may give the impression that we are being productive and moving quickly. However, did you notice the N+1 query that we just introduced? This sort of error can be easy to miss in a standalone pull request, and human errors are common.
00:14:52.600
If this mistake made it into production, it likely wouldn’t be disastrous or even noticeable at first. However, as the API evolves, if we subsequently add phone numbers or addresses, and maybe even emergency contacts—all with their own associated details—we might inadvertently create hundreds, or thousands, of queries instead of a handful, leading to performance issues.
00:15:36.190
In Rails, there is a way to fix this: we can look for any associations being used and eager-load them in our controller. This approach resolves the N+1 query issue, yet it still requires considerable manual effort from developers. They need to grasp the usage of the code and understand the associations being utilized. They have to locate the original query to insert here the includes.
00:16:20.680
For smaller systems, this approach works well, but in more complex systems, there may be a significant distance between where data is queried and where it’s utilized, making this quite challenging. In our previous example, the usage occurred in the contacts serializer, while the queries were performed in the controller. Developers must understand both components.
00:17:15.250
This only addresses one instance of the N+1 queries at a time. Each time we edit these files, we need to think about this situation again. Moreover, we have to consider what happens when we no longer need the association: do we just accept that we’ll keep pre-loading it because we’ve already fixed the issue, or do we leave it as is? There must be a better solution.
00:18:09.900
A tool that helps raise signals whenever an N+1 query is generated exists, but manual effort is still needed to resolve them. To address this, we developed a gem named JIT Preloader—to improve preloading it just in time. This gem has been successfully running in our production environment for a couple of years, effectively removing N+1 queries entirely.
00:18:57.630
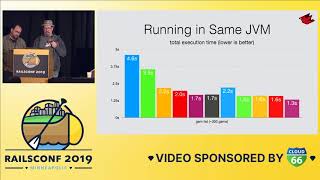
After dropping the gem into our project and configuring it to be globally enabled, we observed a significant decrease in database time usage. Initially, we recorded a spike of two to four minutes in database time every thirty seconds, resulting from multiple concurrent requests hitting the endpoint. However, after deploying the gem, we stabilized around 30 seconds—roughly four to eight times better by eliminating those N+1 queries.
00:19:43.080
In addition, we examined a graph that displayed the number of database queries associated with a specific table. The initial performance showed us making hundreds or thousands of queries, but after deploying the gem, the number stabilized down to a handful. We also conducted requests analysis before and after the gem deployment and found that the 95th percentile of requests was twice as fast after deploying the gem, while the 99th percentile improved threefold.
00:20:32.520
This process that could have required immense effort from us to manually address all N+1 queries was instead transformed into an investment that resulted in being able to build a useful tool. Now, developers can focus more on delivering value to the business without worrying about N+1 issues.
00:21:27.880
The second lesson I want to discuss is the importance of cleaning up code that you no longer use. Many of you may have experienced dilemmas during significant framework upgrades, such as Rails. You might encounter pieces of code that break, leaving you uncertain of whether it’s being utilized. There may be failing tests suggesting these codes are in use, leading you to decide whether to support them or not.
00:22:16.000
At Clio, we had a situation during an interface upgrade where we duplicated all our views—one set had the new interface, and the other retained the old. This arrangement was meant to last a couple of months only, but we never cleaned up the duplicated views. As a result, we ended up supporting both for too long until someone finally took the initiative to start removing things en masse.
00:23:09.440
Unfortunately, we hadn’t yet learned our lesson, as a couple of years down the line, we found we needed another major upgrade, resulting in a huge accumulation of rake tasks that were no longer being used. We kept pushing through this issue more times than we should have. Eventually, we decided to put some effort into unsolicited cleanup.
00:24:02.510
Currently, as we are transitioning from Rails-generated HTML templates to a frontend that consumes a JSON API, we recognize the urgency of cleaning up the old endpoints during this process. However, leaving this old code untouched costs nothing in the short term, but it may complicate future efforts while scaling the codebase.
00:24:59.640
We started off with some ideas to handle dead code, one of which we called the "tombstone." This simple approach made an error and reported it to our Bug Tag instance—our bug tracking service. By inserting single-line markers into random methods or views to signify code as obsolete, we were able to track its trends over time, noting when exceptions were thrown and indicating if certain methods were still being utilized.
00:25:43.360
Recently, we developed a library we termed the "Dead Code Detector." While it may not yet be capable of addressing rake tasks or views, it can track many methods within our code. We’ve deployed it live for about a month, allowing us to analyze unused pieces and begin deleting them. The idea behind the tool is to leave it running for a reasonable period to track methods that have not been used, after which we can safely delete them.
00:26:38.900
We have also identified an existing library called Coverband, which serves a similar purpose. It provides more detail around individual lines of code that have been called or not. While the Dead Code Detector only tracks methods, Coverband states clearer insight at the potential expense of stability and higher memory usage. Regardless, both tools enable the removal of unutilized code.
00:27:38.230
After adding Dead Code Detector to our project, it resulted in the deletion of approximately 300 controller actions and a thousand methods. We were fairly conservative in our analysis, tracking mainly controllers and models; in the coming months, we intend to expand our approach and purge as much unused code as possible.
00:28:26.990
The third lesson I want to convey is that you will never escape the need to handle emergencies. They will always come up, often causing pain both in terms of interruptions and wasted database time. A particularly memorable episode occurred in February a few years back, when everything was going smoothly, only to see periodic spikes in long response times for our users.
00:29:21.000
This meant a situation where normally quick requests were taking several seconds or outright rejected, leaving users with error pages. At the time, we relied on New Relic for monitoring application performance. However, when the database slows down, all endpoints slow down, rendering New Relic almost useless.
00:30:07.750
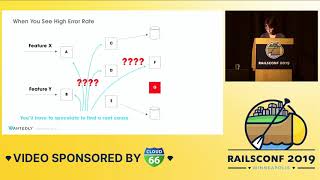
Instead of pinpointing specific slow endpoints, it would return a mess of slow data, and under such pressure from the business, we commenced a hunt to figure out the cause. Developers found themselves working late, overwhelmed with noise and little informative signal.
00:30:51.640
In our search, we combed through the MySQL slow query log, which was a daunting mass of information that proved difficult to parse. We sifted through the log for anything unusual—including lengthy queries or ones accessing large numbers of rows. Yet there always remained the challenge of determining what to do with our findings.
00:31:43.420
Eventually, we relied heavily on the developers’ collective knowledge, seeking the most experienced individuals who could identify the code responsible for the slow SQL query after scrutinizing them first. This process required countless hours spent by multiple developers figuring it all out. These emergencies began to disrupt our projects regularly.
00:32:43.390
Recognizing that we had made queries based on false assumptions—queries without limits or with many joins, crafted in an era when the data set was small, resulted in significant latency. We investigated what tools could remedy the situation. Basecamp's gem Marginalia, for example, attaches comments describing the query’s source to the relevant ActiveRecord queries.
00:33:14.320
Setting it up required adding the gem, and while initially ambiguous, it ultimately provided additional metadata for parsing our query logs. The ambiguity dissipated, allowing us an initial understanding as to where the query originated from.
00:33:57.240
Rails 5.2 introduced Active Support Current Attributes, enabling developers to append custom metadata to queries executed through ActiveRecord. By attaching user IDs or request IDs, we could glean insights to understand trends better.
00:34:43.540
Establishing that a query’s duration exceeded a defined threshold is achievable, and could flag such queries with messages indicating their details. As a result, scenes that previously involved manual endeavors digging through logs transformed into automatic alerts recording long queries and efficiently flagging them.
00:35:31.370
When we identified the queries and their origins, it generated a report detailing exactly which queries were long and which lines generated them. Trends, release information, and frequency came into view. This influx of proactive information proved beneficial in seeking time management to handle emergencies before they escalated to crises.
00:36:17.490
The final lesson I wish to discuss is managing and automating the prevention of bad patterns. If you know that a particular pattern is bad, you can employ preventive measures to keep it from entering your codebase entirely, avoiding reliance on human review. Let’s examine an example: sometimes, your code may need to write to temporary files. The issue arises when these temporary files are not consistently deleted when something goes awry in the code.
00:37:11.200
For example, if a method throws an exception, it could leave temporary files piling up, ultimately consuming disk space and potentially causing a partial outage. Coding practices at Clio discourage leaving temporary file creation unwrapped. We require this to be properly implemented.
00:38:08.420
With CI measures in place, using static code analysis tools such as RuboCop can enforce various rules and ensure erroneous patterns do not enter your codebase. You can implement this in CI processes, or pre-commit hooks, to get rapid feedback on rule violations. RuboCop can also handle auto-corrections for minor issues.
00:39:20.455
RuboCop covers conventional issues, such as preferring single quotes over double quotes, but also encompasses more complex rules that prohibit code practices known to introduce technical debt in our codebase.
00:40:19.540
Shopify has developed a new methodology referred to as list-driven development. This involves designating a whitelist of acceptable code behavior and blacklisting everything else. This allows you to enforce behavior in specific parts of your system while you work to remove those behaviors elsewhere.
00:41:10.430
Once again, referencing Shopify’s blog, we could define a whitelist, for instance, to restrict certain classes from performing behaviors no longer deemed acceptable. This approach allows a gradual enforcement of good practices without hindering development velocity significantly.
00:41:59.000
Taking a proactive stance in preventing bad patterns from infiltrating our codebase will enhance our work environment. For instance, at Clio, CI mechanisms are set in place to highlight any new temporary files proposed within a pull request, providing immediate and constructive feedback regarding coding practices.
00:42:56.520
We maintain a repository of Robocop rules—along with several others—making the overall process of preventing negative patterns easier in light of the community’s cooperative efforts. By staying cognizant of technical debt and its ramifications, we can actively work towards building improved tools for the future.
00:43:49.520
Through continuous sharing and collaboration, the Rails community can develop into an invaluable resource, creating a wealth of knowledge that allows us to mitigate technical debt actively. Let's all strive to contribute to this community and seek out innovative methods of minimizing technical debt.
00:44:38.110
Thank you for your attention.