00:00:16.189
We're good, thank you. Sorry for the delay. Classic—you know, even in the future, nothing works. Welcome! I am Todd Schneider, an engineer at Rap Genius, and today's talk is going to be about data science.
00:00:20.460
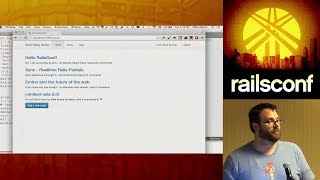
With a live tutorial. Before we get into the live coding component, I want to show you all a project I built previously, which kind of serves as the inspiration for this talk. This is a website called Wedding Crunchers.
00:00:36.420
What is Wedding Crunchers? It's a place where you can track the popularity of words and phrases in The New York Times wedding section over the past thirty-some years. A lot of you might be wondering why on earth this would be interesting, relevant, or funny, and I hope to convince you of that very quickly.
00:00:55.170
Here is an example from wedding announcements in The New York Times, this particular one is from 1985. If you don't know me, or don't live in New York, The New York Times wedding section carries a certain cultural cachet. It’s kind of an honor to be listed there, and it has a very resume-like structure that allows people to brag about their schools and jobs.
00:01:15.330
So here’s an example: Diane DeCordova is marrying Michael Lewis. They both went to Princeton and graduated cum laude. Diane works at Morgan Stanley, and Michael works at Salomon Brothers in New York. This should sound familiar to many of you. Michael Lewis is famous for his book 'Liar's Poker,' which details his experiences at Salomon Brothers. Before becoming a successful writer, however, he was just another person listed in a New York Times wedding announcement.
00:01:47.600
What Wedding Crunchers does is take the entire corpus of New York Times wedding announcements back to 1981. You can search for words and phrases, seeing how common they are by year. For example, you can look at the terms ‘banker’ and ‘programmer’ in these announcements.
00:02:17.989
In the past, the term ‘banker’ was used much more frequently than ‘programmer’ in these announcements, but as of this year, 2014, ‘programmer’ has finally overtaken ‘banker’. This reflects a significant shift in the kind of people getting married in New York, indicating a change in societal trends.
00:03:00.100
Another interesting comparison is between Goldman Sachs and Google. Goldman Sachs represents the traditional New York finance institution, while Google signifies the rising tech industry. This dichotomy in the wedding announcements tells a powerful story of changing tides in different professional landscapes. It's amusing, but it’s also quite insightful.
00:03:22.230
Today, we're going to build something just like Wedding Crunchers. Instead of using the text of wedding announcements for our analysis, we will look at all the RailsConf talk abstracts. I hope this is interesting to the people here. One key takeaway from this talk should be to work on a problem that's interesting to you. Especially in data science, much of the work can be messy.
00:03:35.640
You may need to scrape data, and it’s easy to get frustrated or lost. If you’re not working on something you care about, you might get easily distracted and ultimately bail on the project. So, remember to focus on topics that you are genuinely interested in.
00:03:58.360
The particular analysis we are going to conduct today is called n-gram analysis. For those who aren’t familiar, an n-gram is simply a consecutive sequence of words within a sentence. For instance, in the sentence 'this talk is boring,' the 1-grams are 'this,' 'talk,' 'is,' and 'boring.' The 2-grams would be every pair, so 'this talk,' 'talk is,' and 'is boring.'
00:04:13.440
To build a graph analyzing trends in RailsConf abstracts, we need to look up for each year how many times specific words or phrases appear in our data. This is what we are going to build today. I have outlined three steps that are generally applicable to any data project: Step one is gathering the data and getting it into a usable form.
00:04:52.760
Step two involves performing the n-gram calculations and storing the results. Lastly, step three creates a user-friendly front-end interface to visualize and investigate our findings. Unfortunately, there's only so much we can cover in a 30-minute talk, so we'll focus primarily on steps one and two, while glossing over step three.
00:05:12.340
The analogy I like to use is watching a cooking show on the Food Network, where something is put in the oven, and suddenly something completely different pops out. It appears effortless, but we know there was a lot of work that occurred behind the scenes. Don't worry—everything we do today is also available on GitHub. There’s a repository I’ll share at the end.
00:05:32.690
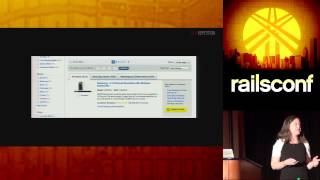
Let’s dive into step one: gathering the data. We'll first take a look at the RailsConf website to figure out how we will model a Rails talk in our database. We need to know what attributes a Rails talk has. It's straightforward: each talk has a title, speakers, an abstract, and a bio.
00:05:54.900
For our database setup, we will need attributes like the year, the conference title, the speakers, the abstract, and the bio. In terms of our gem file, it's primarily boilerplate for Rails and Ruby 2.1. The only gems I want to highlight are Nokogiri for scraping and parsing websites, PostgreSQL as our main data store, and Redis to build indexes for word occurrences.
00:06:11.950
Many people often criticize Ruby for lack of support in scientific computing because other languages have more robust frameworks. But I believe that is not a significant concern. You can achieve a lot with simple tools you build yourself. You don’t necessarily need a fancy gem or algorithm.
00:06:40.880
Ruby is especially good for web scraping, which is the focus of today's talk. Now we actually need to write some code to scrape the talk descriptions from the RailsConf website. If you have experience with this, you know that the Chrome Inspector is your best friend. Let’s fire that up and inspect the elements we’re interested in.
00:07:05.220
We are looking to take the HTML on the page and turn it into database records that we can use later. All the talks are contained in session classes within the HTML structure. There are 81 session divs, and I happen to know mine is number 78.
00:07:23.730
We need to extract the title, speaker, abstract, and bio from the HTML. The title is in an H1 element, and the speaker is in an H2. The abstract is contained within a P tag, while the bio is usually located in another P tag.
00:07:41.300
However, we need a way to differentiate between the bio and the abstract because they both use P tags. Using specific CSS selectors will allow us to accomplish this. By using the greater than symbol in CSS, we can ensure we only select the P tags that are immediate descendants of the session div, which gives us only the abstract.
00:08:05.450
Next, we need to write the actual Ruby code to do this. I already have a method for fetching and parsing the URL using Nokogiri. Let's set up the document and iterate through each session.
00:08:24.950
In our coding process, we must ensure accuracy by checking each output. It's vital to be proficient in CSS selectors as they play a crucial role in how we extract the required data. As we analyze our document, we find the title, speaker, abstract, and bio in their respective tags.
00:08:43.680
As we validate these elements through our selectors, we realize our implementation is working as intended. However, it’s important to always check and recheck our outputs to ensure we're capturing the correct data.
00:09:06.560
We can simplify our commands by leveraging jQuery-like syntax in Ruby and focusing on immediate parents or children where necessary since we have specific tags to target. We’re getting our first successful outputs.
00:09:25.170
Once we have the required data in place, we wrap it all into a create method for RailsComp. Although this process sometimes feels tedious, it’s foundational for building our dataset and ensuring we can perform data analysis effectively.
00:09:54.690
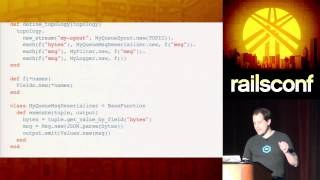
The next steps in our analysis involve creating the n-gram calculations. To do that, we write methods to analyze the text, focusing on creating the 1-grams, 2-grams, and how those will contribute to our overall dataset for exploration. This is how we get the little insights that can potentially turn into larger patterns of knowledge.
00:10:26.060
Now we need a method to visualize trends, and for this, we might choose to use data visualization libraries that fit well with our framework. The ultimate goal is to create a clean interface that will allow others to dig into the results we gather.
00:10:47.040
As mentioned, the core components of our n-gram method will allow us to analyze word frequencies, and the final presentation layer will play a crucial role in expressing the findings clearly to our users.
00:11:09.980
After building our models correctly, the next step is to set up our Redis database to store and analyze our word frequencies effectively over the years. This will allow us to query by year and see the evolving trends in word usage, which ties directly into the insights gathered from earlier on.
00:11:35.860
As we gather the data from the Rails talks, we can progressively build up these relationships and understand the shifts happening within the community over time. This process reinforces how data science is deeply intertwined with tracking records and storytelling.
00:12:04.350
We’ll continue to run tests to ensure accuracy in our word count, and every successful capture of data builds a fuller picture of our society’s changing language. The culmination of our insights will serve as a testament to the evolution of language around our subjects.
00:12:30.390
Through countless iterations of coding and analysis, we create the end product, which highlights these trends in data. It’s a reflection of how we can capture nuances buried in text to extract meaning and derive valuable information.
00:13:00.360
We’ll continue diving deep into these sets, ensuring that we stay focused on not just gathering data, but also on validating our assumptions during the analysis. This ensures that as trends shift and emerge, we can communicate them effectively in actionable terms.
00:13:29.110
As we approach the conclusion of our talk today, I urge each of you to explore the full capabilities of the tools at your disposal. Make use of the GitHub resources to experiment and further develop your own datasets, applying these principles of data science and visualization.
00:14:00.220
I’ll be sharing a link to our GitHub repository, and I welcome any question. It’s crucial to remember that while we have touched on the basics today, diving deeper into these topics will be of tremendous benefit in the long run.
00:14:30.930
I appreciate everyone for joining me today as we explored how we can bridge code with tangible analysis. I encourage discussions about the project and of course, your curiosity is always welcomed. Let’s make sure we take this knowledge and continue to learn from each other.
00:15:00.140
Thank you once again for listening, and I look forward to seeing how you all might apply these concepts to your own projects! Let's wrap this up and open the floor for questions.