00:00:10.700
I'm really excited to be here talking to you about this at RubyConf this year. I just want to take a moment to thank all the organizers who have put in a lot of work to make this event happen.
00:00:17.490
Again, my name is Tim Mertens. I am a software architect at a fintech company based out of Chicago called Avant. Prior to my current role, I led our test engineering team for about three years, and I've been working in the software industry for about ten years.
00:00:32.099
You can find me on GitHub and on Twitter, although I'm not a big Twitter user. I'll be posting some links later on my Twitter account with some resources for you to look at.
00:00:38.610
Today, I'm going to be discussing deterministic solutions to intermittent test failures. A lot of us have experienced the problem of having a really large test suite where things start to fail irregularly, and it can be a real pain.
00:00:57.960
Just to illustrate that fact, my wife made fun of me for making this slide. She says I'm a bit of a fanboy for Elon Musk. Picture Elon sitting in his chair reading an article about another gravitational wave being detected and saying, "You see, it's happened again.".
00:01:12.930
His logical friend responds, "Elon, this isn't a simulation, it's reality!" Meanwhile, somewhere else in the universe, there's this old guy sitting at a computer saying, "Jesus, the build failed again. Can you rerun it?" And this younger guy replies, "Sorry, I’m kind of busy," while playing games on his phone. The old guy retorts, "Don't make me send you back down there," to which he responds, "Yes, father." This is something we all deal with.
00:01:41.400
I will be using some code samples in my presentation today. These samples are primarily based on RSpec. However, the workflow I'm going to share can be applied to any testing framework. My primary experience is with RSpec because it provides a lot of tooling that aids in what I'm showing you today. Additionally, I have some source code examples available that are purposely failing, allowing you to familiarize yourself with the types of failures I'm discussing.
00:02:16.530
It’s common for builds to pass consistently for a while, but inevitably, someone will exclaim, "This is awesome! The build has been passing for so long!" and what happens next? The very next build fails! People dismiss this as just a flaky test. Before we dive into the workflow part, I want to address the myth of flaky tests.
00:02:49.170
There’s a common notion that some problems within our test suite are unsolvable. However, I refuse to believe this. I want to remind everyone: your tests are software. If you have a critical API call that fails from time to time, and a CEO or business person asks why, would you say, "Oh, that’s just a flaky endpoint and there’s nothing we can do about it?" Of course not! It’s software; you make it work as needed.
00:03:29.490
When we use the term 'flaky', we imply there’s an unsolvable problem. Instead, I prefer to replace that term with 'non-deterministic'. This signifies that there is behavior in our system that can be accounted for once we understand the root cause. When we identify such failures, we can modify our tests or fix production bugs, allowing our tests to be deterministic.
00:04:07.790
Additionally, ignoring failures can mean overlooking legitimate defects in production code. So, let’s discuss how I got to this point and the story behind it. It’s a story fraught with challenges. I’ve faced many failing tests, and the insights I’m sharing with you today are derived from my experiences.
00:04:30.360
For those of you who haven’t been part of the development community for long, we often talk about continuous integration. This is the process of pushing your code to platforms like GitHub, where some service automatically runs your tests. Examples include Travis, CodeShip, CircleCI, and Jenkins. In the earlier days at Avant, our small testing code could easily fit into our CI tool.
00:05:01.390
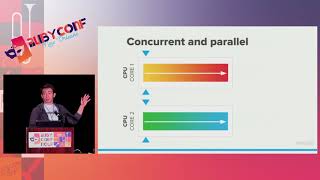
Over time, our code base and test suite grew, taking a lot longer to run. To manage this, we decided to parallelize the builds, which means distributing a thousand or ten thousand tests across different containers or workers. We implemented this strategy and every once in a while, something in the test suite would fail, yet we were focused on building features.
00:05:30.020
When focused on feature development, it's easy to lose sight of underlying bugs in the test suite. People often shrug off a failing test as just a flaky test and recommend rerunning it. If it passes, they then merge the code, leading to a cycle where the problem is ignored in favor of rapid feature development.
00:06:06.880
As we continued building, we introduced complex dependencies in our test suite, using factories to construct intricate graphs of dependencies for testing complicated business logic. Eventually, no one was completely aware of everything happening when running a test, so while we kept running many builds, failures persisted, yet only critical failures prompted action.
00:06:45.000
Eventually, we realized our CI provider wasn't meeting our needs, and we sought a new one capable of accommodating our larger test suite. We transitioned to this new CI provider to improve efficiency, but all of a sudden, our tests exploded with failures. We recognized our old CI provider was breaking tests into manageable groups.
00:07:07.670
As a result, certain tests were never run together under the old setup. This led to newly introduced complexity causing our tests to fail after randomization, resulting in many issues that had until then been hidden from us. During the next eight to ten months, a colleague and I focused on fixing our tests.
00:07:39.100
Today, I will share a workflow for troubleshooting these types of failures, a workflow born from fixing thousands of tests. Consequently, when something does fail, I typically have a good grasp of what is likely causing the failure, so I want to give you a guide to help you fix test failures.
00:08:06.000
So, when the master fails and the tests fail, what do we do? The first step is to run that failing test by itself. If it fails consistently every time, that’s the best-case scenario. We have a reproducible failure that will be easier to debug on my local machine to figure out what’s going on.
00:08:43.990
Reproducible failures are a common challenge with intermittent failures. Next, I will briefly cover a few common errors that tend to occur but won’t dwell into them deeply as they are usually easier to fix. Some pitfalls include stale branches, where someone works on a branch but fails to back merge for weeks. When they return to merge their pull request, the test suite may fail because of incompatible changes introduced by others during that time.
00:09:29.920
Other examples are tests that rely on logic depending on dates and times. You may encounter differences in behavior when running tests close to weekends, holidays, or end of the year due to the date and time dependencies. Also, be mindful of mocking time. If you are using a gem like Timecop for mocking system time, remember that external processes may not acknowledge that mock.
00:09:49.289
Another pitfall relates to missing preconditions. When your tests depend on setups from other tests, if those tests are not run due to randomization or ordered execution, failures may occur because certain required setups are absent. Finally, don’t overlook real bugs. While troubleshooting tests, ensure you understand the root causes of any failures instead of simply covering them up.
00:10:33.360
Now, if we correctly ran the test by itself and it doesn’t fail every time, we can take the group of tests that ran in our CI container and run them again using the seed that was used to randomize the execution. A test group is simply a subset of tests from our suite that ran on a specific node during the parallel build.
00:11:10.450
When using the RSpec command directly, you may not have a specified test group beyond running all tests at once. Your test seed pertains to the integer value passed to RSpec that reproduces the order tests were executed in your CI environment. After running your tests, the output will display the randomized seed value.
00:11:56.170
We take that test seed, and while rerunning our tests, we also apply the seed option to replicate the environment and execution order. It’s also beneficial to use the fail-fast flag, allowing RSpec to stop upon hitting a failure, thus optimizing the debugging process.
00:12:36.750
If subsequent test runs still fail, we can then implement bisecting the failure. In RSpec 3.3, a feature allows for this automated process. We essentially want to start with the full group of tests that previously ran, cutting them in half repeatedly until we isolate the point where the failure exists.
00:13:05.360
If this process leads us to a particular test that fails alongside a passing test, this indicates we’re dealing with test pollution, which occurs when the side effects from one test adversely affect another. Common failures associated with this include data pollution, where a test persists data outside its transaction without proper cleanup.
00:13:44.090
At Avant, we embrace defensive testing: tests should clean up after themselves, being robust enough to handle non-pristine conditions. For instance, if a test affects a user’s creation, that action could inhibit other tests that also attempt to create a user.
00:14:04.940
It’s advisable to reformulate tests to expect changes rather than specific conditions, allowing our tests to pass even in the presence of other records. For example, instead of expecting global scopes to only return the records created during the test, we can assert for inclusion or exclusion without stringent conditions. This promotes resilience in our tests.
00:14:56.770
Caching also presents its challenges; if tests mutate global state or modify singleton caches, it could lead to problems. Ideally, test cases should reset any cache changes made and utilize stubs or mocks to avoid global state modifications.
00:15:24.230
When dealing with singletons in tests, it is important to implement singleton behaviors correctly, ensuring that we modify local instances rather than the global state itself. Mutating constants is another common pitfall that can lead to future inconsistencies, which is why leveraging the mocking tools from our testing framework can mitigate these risks.
00:16:03.090
Ideally, avoid rewriting production class implementations during tests. Instead, create instances for the purpose of testing and apply stubs where necessary. These practices will safeguard against unintended side effects that arise from direct modifications.
00:16:25.180
Additionally, it’s wise to refrain from defining constants in your tests as this can lead to unexpected overlaps in the global namespace with future tests. Prefer using local or let variables for assertions to prevent unintended consequences arising from state mutations.
00:17:10.000
If we rerun our tests and the failures remain unresolved, we may be facing unreproducible failures—failing tests that break CI builds but are difficult to replicate locally. These failures often involve timing situations or environmental outcomes.
00:17:40.680
When these failures occur, examine your tests under various conditions such as weekends or holidays to check for issues compatibility with business time. Utilizing Timecop or a similar tool can allow you to test specific dates and times more effectively. Moreover, ensure you account for discrepancies between your local time zone and UTC to avoid such disagreements.
00:18:32.860
Another hurdle involves SQL date comparisons. When passing date/time objects into Active Record under certain conditions, it can lead to conflicts. Failing to ensure proper comparisons can lead to unexpected results, especially if your application’s time zones don’t align. Keep testing conditions localized to mitigate these issues.
00:19:29.930
Timeouts in asynchronous JavaScript or browser tests can also cause intermittent failures, especially if performance drops in the CI environment compared to local runs. This inconsistency is often exacerbated by previous test executions or how your test suite is configured.
00:20:13.890
When conducting browser tests, avoid setting limitation values too low in your CI environment, as it can lead to flaky test assertions. Instead, adjust the timeouts to reflect realistic execution conditions, allowing for variability that may affect overall performance.
00:20:57.230
If failures persist and remain unclear, start scrutinizing environmental differences. Compare your CI configurations to your local environment to spot any discrepancies in environment variables or setups between your local execution and CI.
00:21:37.410
Investigate library versions and behavioral inconsistencies across operating systems. Using Docker across both local machines and CI provides consistency in the testing environment, helping to eradicate variability. If this doesn’t yield results, digging deeper into the CI environment via SSH may offer further resolutions.
00:22:23.100
Utilize common sense to evaluate failures by examining stack traces and forming hypotheses as to their causes. When hypotheses involve third-party gems, check their repositories for related issues or updates that could influence your application.
00:23:14.820
Lastly, aim to narrow down the scope of defects systematically. Avoid throwing random possible solutions at the issue; instead, methodically assess each factor through incremental adjustments to enhance the clarity of emerging issues.
00:24:11.640
Be in tune with your test support code to ensure it isn’t conflicting with your current tests—especially with a large number of tests like those exceeding 30,000. Observing failure trends may provide insights as to whether particular tests exhibit recurring failures.
00:25:05.930
Adding logging to your tests provides context for when failure occurs, helping to understand what happened leading up to the error. To wrap up, thank you for being here today. Here are some quick takeaways: keep your builds green to avoid frustrations.
00:25:47.190
It’s truly discouraging to come in and find multiple test failures. Remember, tests are code too, with the capacity to execute exactly as instructed. Set realistic expectations for yourself when addressing existing issues with your test suite—it takes time to rectify these problems. Lastly, celebrate successes, both big and small, as milestones in your journey.
00:26:34.350
I’ll be sharing the larger workflow from my slide deck on Twitter. Thank you for your time!