00:00:20.810
All right, let's get started. This talk is about event sourcing and how we made it simple at Kickstarter. But let's kick things off by creating a to-do app together.
00:00:32.970
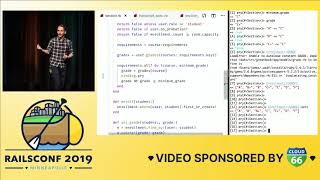
We will begin by generating a brand new Rails app called 'to-dos'. Then, we will add a model called 'task', which is just an ActiveRecord model. Next, we'll implement the controller, including the index, show, and create actions.
00:00:40.410
The first thing I want us to implement together is completing a task. To do this, we will create a new action called 'complete' in the task controller. This action is quite simple: it finds the task by its ID, updates the 'completed' boolean attribute to true, and then renders the task as JSON.
00:00:53.010
Now, a new requirement comes in: we actually want to record the completion date—specifically, when the task was completed. This may be necessary to surface that data to the user or to send a daily recap email summarizing all the tasks completed that day.
00:01:09.899
To implement this, we will replace the boolean attribute with a 'completed_at' timestamp. This is something we often implement in Ruby on Rails applications. From now on, whenever a task is completed, we will set the 'completed_at' timestamp.
00:01:22.679
Next, we need to add that column to the model. To do this, we create a Rails migration. In that migration, we will iterate over every single task that has already been completed and update the 'completed_at' timestamp.
00:01:35.580
Now, the question is: what should that value be? It could be the current time, but considering that the data is essentially lost, we don't know what the real 'completed_at' timestamp is. We might use the 'updated_at' timestamp, which is the closest thing we have, but that is still not perfect.
00:01:59.759
Moreover, we want to know who completed a given task. Once again, we return to the controller and assign the 'completed_by' value to the current user. However, when it comes to adding that foreign key to our tasks, we face a similar issue: we don’t know who completed the task beforehand, so the data is still lost.
00:02:17.879
Now, let's add some event tracking because as soon as the application goes into production, we need to track some events related to it. We add a snippet of code that tracks the event with 'track_event: task_completed', providing it with the task ID and user ID. You can imagine how we incorporate this into every action in nearly every controller in our app.
00:02:42.069
Next, let's implement email notifications. Since this is a multi-user platform, we want users to receive emails whenever someone else completes a task they've created. This is what the snippet of code will accomplish. Additionally, we want to build an activity feed so users can see what has happened on a given project.
00:03:06.040
In this new line of code, we create an activity item with the subject as 'task completed' by the current user. Now, when we release the feature for the activity feed, we will not have any past activities, so we will start with a blank slate. You could write some custom scripts to backfill those activities, but you would essentially be guessing.
00:03:23.860
Hello, my name is Philippe Creux, and I work for Kickstarter. Today is a special day because we are celebrating our 10th anniversary.
00:03:42.489
It really feels like an Apple Keynote, and it seems appropriate to mention. As we reflect on the past 10 years, Kickstarter has helped fund 162,000 creative projects. Sixteen million people have backed a project on Kickstarter, and we have raised a total of approximately 4.2 billion dollars for those projects.
00:04:06.060
You might know Kickstarter for blockbuster projects like 'Cards Against Humanity', 'Exploding Kittens', or the 'Pebble Watch', but there are also thousands of smaller grassroots projects spanning various fields such as film, documentaries, dance, art, comic books, and more. We encourage you to visit the Kickstarter website today, as there are many Easter eggs to celebrate our 10th anniversary.
00:04:29.700
Now, let's delve into the topic of event sourcing. The concept of event sourcing is that the application state is the result of a sequence of events. Let me illustrate this: we have the application state at the top and events at the bottom.
00:04:54.150
When a user interacts with our task management application and creates a new task, for instance, we generate a new event called 'task_created' with the title of that task. We then apply that event to the application state, creating a new task with the given title. If the user goes back to the UI, clicks on the calendar icon, and sets a due date to April 20th, we store that event in the database and then apply that event to the application state.
00:05:26.520
If the user realizes the title was incorrect, they could go back and update it, which generates a new event that we also apply to the application state. Similarly, if I am responsible for preparing my slides, I assign that task to myself, meaning another event is generated when applied to the application state.
00:05:47.100
As I get closer to the deadline, I might change the due date to April 24th and apply this update to the application state. Finally, when my slides are finished, I can mark the task as completed and again apply that change to the application state.
00:06:12.540
In these instances, we only see events with their data, but events can also contain a lot of metadata. You can store information such as when the event was created, who created it, what device was used, and what IP address the request originated from. Essentially, you can persist all the context available in your controller, which may be necessary later.
00:06:50.560
The good news is that you use event sourcing every day or at least a tool that has some flavor of event sourcing. Your current working directory in Git is basically the current state of your application. As you create new commits and move between them, you are creating events. Each event, accompanied by a commit message, explains why the change happened while the diff shows what precisely changed.
00:07:22.599
With Git, you can perform some great operations; you can replay commits, branch off, or even go back in time. This parallels what we are discussing in event sourcing.
00:07:36.010
Let's delve into the key benefits of event sourcing. Firstly, it provides you with a full history and a complete audit log of all the different events that have occurred, allowing us to understand how we got to a particular state.
00:07:52.760
This comprehensive history greatly simplifies debugging, especially when events originate from various users or are the result of webhooks and API calls. Having this complete history aids in customer support, as you can easily reference what occurred in the app.
00:08:07.060
You can replay events to backfill new attributes and, as I mentioned, events carry a wealth of data and metadata. When a new attribute is added to the application state, you can adjust the function that applies those events, replay all the events, and now your data is cohesive with that new attribute.
00:08:21.550
You can replay events to recover lost records, allowing you to wipe your application state clean and replay all events to restore it. This capability is particularly beneficial when working through migrations.
00:08:34.590
This aspect of event sourcing provides a new perspective on your data. Knowing that you can erase everything and always get it back gives you confidence.
00:08:50.760
You can also replay events to resolve inconsistent states. If race conditions emerge due to incorrect event applications, you can rectify the situation by replaying events to restore a consistent application state.
00:09:05.870
You can also travel back in time by replaying all the events up to a certain point to view your application state at that moment. This essentially grants you a time machine.
00:09:22.370
Events also have significant value as first-class citizens. You're not merely creating a placeholder with the 'track_event' method; rather, the event itself becomes central. You can forward these events to your data warehouse, monitoring solutions, and any analytics platforms to maintain high-level application oversight.
00:09:36.090
For instance, you can verify that there is at least one pledge every minute on Kickstarter and raise alerts if that doesn't happen. You can apply events to build tailored projections.
00:09:50.040
As we noted, each event is applied to what I refer to as an aggregate. Take, for instance, our task events applied to the task aggregate. Similarly, account events could be applied to account aggregates or subscription events applied to subscription aggregates. While these aggregates serve as main projections, you can create multiple projections and transform events to generate activity feeds or daily reports.
00:10:07.230
If your application requires fast reads, you can build projections tailored to specific needs or user types. As events are generated, they update these projections, allowing you to read from them instead of constructing complex SQL queries every time a report is needed.
00:10:25.780
Events can also assist in backfilling your data warehouse tables. As we've discussed, you can forward events to your data warehouse. After your initial setup, if you need to send historical data to your data warehouse, you can do that too. This is particularly useful when you launch a new feature like Activity Feed.
00:10:43.319
Event sourcing shines in distributed systems, and much of the literature surrounding it focuses on these systems. Microservices can generate and send events, yet you don't need a microservice architecture to benefit from event sourcing. In fact, event sourcing works splendidly within a monolithic architecture.
00:11:05.270
So, let's talk about how Kickstarter implements event sourcing and has managed to make it simple. About two years ago, we studied a new product called Drip, a subscription-based platform to support creators on an ongoing basis.
00:11:19.830
We determined that developing this new product would be a great opportunity to experiment with event sourcing. As we set forth designing the event sourcing framework, we identified several key requirements. Firstly, it had to be very simple to learn and use since we aimed to launch Drip within six months.
00:11:37.140
Secondly, it had to be easy to remove; it was merely an experiment. If things went south due to the tight deadline, it should have posed little difficulty to revert back to standard controllers.
00:11:56.229
Ultimately, our solution was a custom framework comprising around 150 lines of code that heavily utilizes ActiveRecord and its callbacks. Events are essentially regular ActiveRecord models. In essence, we only changed the way we mutate data without altering the structure of how we read from the database.
00:12:13.859
With that in mind, let’s dive back into our task completion action. This time, instead of directly mutating the application’s state, we create an event called 'task_completed'. This event is just an ActiveRecord model associated with the task and contains some metadata.
00:12:22.740
For now, we're only passing the user ID, but we could include much more data. What the event essentially does is signify that a task has been completed, tracking the current user completing it. The event has an 'apply' method responsible for updating the state.
00:12:47.050
Thus, when we create an event, we persist it to the database. Then after the event is successfully created, we simply apply it to the task and save the task, marking it as completed.
00:13:02.590
In the database, we have two tables: tasks and events. Each event has an ID associated with a task. The task's event type is 'completed', and this event possesses both metadata, currently only user ID, and a creation timestamp.
00:13:17.810
Now, we have a new requirement: we want to record the exact time when the task was completed. This time, rather than adjusting the controller, we only have to change the 'apply' method in the event. Instead of simply setting the completed attribute to true, we will set 'completed_at' to the created_at timestamp.
00:13:32.020
Setting 'completed_at' to 'created_at' is very important to ensure that if events are replayed later on, the same timestamp is consistently applied.
00:13:50.330
When we need to add that new column to our database through a migration, all we have to do is replay the saved events. The snippet of code responsible for replaying events is fairly uniform across the application: we iterate through all tasks, lock each task to avoid concurrency issues, and for each task, we fetch all respective events to apply them and save the updated state.
00:14:06.850
By simply replaying the events, the 'completed_at' timestamp can now be backfilled efficiently. Similarly, if we want to know who completed the task, we will also make adjustments in the controller.
00:14:23.940
The controller does not require changes; we’ll extract the user ID from the metadata saved from the beginning. The migration will add the 'completed_by_id' to the database.
00:14:39.030
Next, we need to set up email notifications, which involves implementing something we call 'reactors'. These reactors are triggered when an event is created, not when it is replayed, and they enable the performance of any necessary side effects.
00:14:54.300
Reactors can be linked with one or more event types and can run either synchronously or asynchronously, allowing us to trigger side effects and even create other events in response.
00:15:12.100
To add an email notification, we will register our dispatchers and reactors within a dispatcher that utilizes a straightforward DSL to pair a reactor to an event. For instance, when a new 'task_completed' event is generated, it triggers the 'notify_completed' reactor.
00:15:34.240
This notification reactor is just a lambda function, capable of taking the corresponding event as an attribute. Whenever a task is marked as complete, that reactor will be triggered, leading to an email notification being sent.
00:15:50.780
We can now proceed to implement event tracking. For this, we will set up a new reactor named 'forward_event' associated with 'task_completed'. This reactor will merge the event’s metadata and send it to the event bus, thus allowing for a seamless transfer of data.
00:16:07.570
Finally, we create the 'create_activity_entry' reactor, which will take an event and create a corresponding activity entry in the database.
00:16:22.600
Through the dispatching of these events, we have built a system where task events are dispatched to both the 'forward_event' reactor and the 'create_activity_entry' reactor.
00:16:43.600
As we continue to add more events, these will be automatically forwarded to the corresponding event list without requiring further coding adjustments.
00:16:59.830
Additionally, you can easily choose to run a reactor asynchronously by swapping the keyword from 'trigger' to 'async', which will queue a job for execution. Currently on Drip, about three-quarters of our events are processed asynchronously.
00:17:14.860
Returning to the original example of the task controller—where tasks were identified and updated with email notifications, activity feeds, and events sent to the event bus—the new approach entails creating a 'task_completed' event that updates the task while simultaneously allowing reactors to handle email notifications, event tracking, and activity logging.
00:17:32.410
Our new model focuses solely on the way in which we write data, rather than altering how we read it. After one year of using event sourcing on Drip, we have accomplished a great deal. According to our metrics, we currently maintain 15 aggregates, 135 unique event types, 60 reactors, and close to 100,000 aggregate records alongside 500,000 event records.
00:17:56.780
While this volume may not seem large compared to some implementations, it provides a solid understanding of our key 'AHA' moments. First and foremost, the ability to replay events is phenomenal. It allows us to backfill newly added attributes efficiently, such as when we wanted to reflect the deactivation of a subscription.
00:18:14.970
For instance, we modified the deactivation event to capture that change in vibe and replayed all events, ensuring that our data remained accurate without losing track of anything.
00:18:29.870
Another important advantage is the recovery of previously destroyed records. Initially, we deleted records whenever users performed destructive actions. However, we soon realized that marking these records as 'soft deleted' by simply adding a 'deleted_at' timestamp was more beneficial.
00:18:47.940
We modified the 'destroyed' event to appropriately set aggregates as destroyed without deleting them. After replaying all events, our previous records were restored without loss.
00:19:01.830
Our aggregates are fully audited; for example, consider a subscription that can be tracked effectively throughout its lifecycle. You can observe events like creation, activation (from Stripe's webhook), or invoice states—whether collected successfully or otherwise.
00:19:17.550
Tracking these data points provides invaluable insights for customer support, particularly when debugging scenarios that involve race conditions.
00:19:34.660
We frequently experience issues where we expect webhooks to contain specific data or occur in a predetermined order, yet that is not always the case.
00:19:52.320
The ability to replay events enables us to fix these discrepancies by simply adjusting our applied methods and replaying events to put everything back in its rightful state.
00:20:08.990
We utilize a combination of StatsD, Graphite, and Axiom FlexDB for monitoring our event handling. This approach guarantees that our events are properly recorded and ready for reporting.
00:20:26.230
When problems arise in production, the data is readily accessible for exploration, enabling us to create charts or reports with minimal effort.
00:20:44.400
This same principle applies to our Redshift cluster where we send all events. The Business Analytics team can access all events without necessitating constant requests to our team for code adjustments.
00:21:01.590
Interestingly, we launched reporting features approximately six months after our product went live and managed to replay all historical events to the Redshift cluster.
00:21:15.940
So we had every event from day one within our data infrastructure.
00:21:29.690
One noteworthy aspect of our framework is the DSL for connecting reactors to events. Since reactors can create events and those events can trigger other reactors, we end up with an intricate system that remains comprehensible.
00:21:48.360
For example, when a 'subscription_created' event is triggered, a reactor may then issue a 'subscription_activated' event, which could in turn trigger notifications and activity feeding entries.
00:22:06.070
By utilizing this straightforward DSL, it becomes far simpler to conceptualize our application's architecture, including how events are generated and managed.
00:22:26.480
Moreover, an important takeaway from this process is understanding the distinction between data you write and the data you read. The key with event sourcing lies in retaining all relevant data within events, thus allowing for versatile future data retrieval.
00:22:46.920
In typical relational databases, you may struggle with available data that might not fit neatly, but with event sourcing, it's generally easier to retain all necessary data within events for relative ease of access.
00:23:02.220
You could define each aggregate specifically for your current needs, understanding that as time progresses, you can replay older events for any required changes.
00:23:15.940
Let’s now discuss the challenges, particularly the aspect of naming. Selecting appropriate naming conventions is crucial in event sourcing because once you designate a name, it essentially remains unchanged.
00:23:44.520
Investing time to choose the right names for your events can pay off in the long run, but the need to maintain consistency becomes of utmost importance.
00:24:03.280
Updating event schemas isn't as daunting as it might seem; many ask how new attributes can coexist in immutable events.
00:24:18.020
In practice, when new attributes are added, they often carry an implicit default value. For example, adding a currency to a subscription defaults to the US dollar.
00:24:39.070
As new attributes evolve, they often inherit the same default values over time, which creates less friction when handling these additions.
00:24:55.130
A common complexity arises when structuring requests into multiple events. Our event sourcing experiment required that we hide storage requirements behind a conventional API.
00:25:06.560
We utilized commands to help maintain request structures and ensure that specific operations could only be performed when the right conditions were met.
00:25:22.420
Furthermore, each command checks the current state against the new attributes received. If a user updates a post in the UI, we compare if the title has changed and, if so, generate an event.
00:25:39.970
It's important only to emit events when changes occur; this logic ensures that you aren't flooding your system with unnecessary events.
00:25:56.390
This structure allows a single request to generate multiple commands, which in turn may generate different events.
00:26:11.230
Overall, this structuring approach becomes crucial in maintaining an efficient and organized event sourcing system.
00:26:23.100
In summary, I hope I've conveyed the fundamental principles of 'Event Sourcing made simple'. Remember, event sourcing emphasizes that the application state results from a sequence of events.
00:26:41.490
Events hold both data and metadata, allowing us to backfill application state easily and fix bugs without cumbersome procedures. Events also serve as first-class entities in our systems, enabling connection to various services for enhanced integration.
00:27:01.500
Thank you for your time!
00:27:56.470
Now, I’d like to open the floor for questions.
00:28:11.960
The first question: What is the framework? Is it open to others? Yes, it's a 150 lines of code framework and we've open-sourced it. It's not a gem or anything, but some companies have drawn inspiration from it.
00:28:27.710
You can find further information in the blog post where I've shared a link. If you check our GitHub repository, you'll locate it under a zip called 'rails to do event sourcing demo' or something similar.
00:28:43.300
Another question has come up: How do you document your events and track them? This is a challenging question. The events generated within our framework use a DSL to specify the attributes they hold.
00:29:05.730
We generate a documentation file in YAML format that lists event names and their attributes alongside metadata accessible at creation. This configuration file is updated every time we run the test suite or boot the app, becoming a reference point for the data team.
00:29:22.770
Further, another question arose: Do we capture the entire business logic during event creation, including validations? Validations reside in commands rather than events. Every API call or webhook traverses through a command responsible for attribute validation.
00:29:39.090
This design decision streamlines processes for engineers, as we have learned to avoid embedding validations in events due to the evolving nature of data. Any changes in attributes only need validation executed in commands.
00:29:56.480
The discussion of managing metadata is important, especially with user IDs, as users are 'soft deleted' rather than destroyed. This approach ensures that users' data will remain available even if those users no longer exist.
00:30:10.520
Lastly, the question: Can you migrate from PaperTrail? Excellent question! PaperTrail fundamentally works opposite to event sourcing, capturing changes made to data, while events create historical records.
00:30:25.240
The challenge is you cannot easily replay with PaperTrail without the complexity that event sourcing provides.
00:30:37.200
Furthermore, timing issues arise when different server clocks are misaligned. Strive handles webhooks that may trigger concurrently, potentially presenting out-of-order events.
00:31:01.780
We have set up different services that handle these incoming webhooks, allowing us to maintain organized, sequenced events as needed.
00:31:11.340
Pessimistic locking mechanisms are employed to ensure event integrity, enabling us to process incoming events quickly and efficiently.
00:31:30.230
The conclusion is that our event sourcing system is designed to manage millions of records effectively, accommodating scalability, preventing conflicts, and preserving historical accuracy.
00:31:45.980
We are still learning as we grow, but I am confident that event sourcing will continue to be beneficial for Kickstarter moving forward.
00:32:09.560
Thank you all for your participation!
00:32:26.520
[End of Transcript]