00:00:10.820
Thank you.
00:00:25.380
Alrighty, g'day! How are you all?
00:00:31.199
I sound like I'm booming. Am I deafening everyone in the back of the room? No? It's okay? Good!
00:00:37.200
So, this talk is called 'From Rails Rumble to 50 Million Results.' Isn't that an awesome number?
00:00:43.140
In fact, we're even bigger now; it's now 65 million! But for some reason, they didn't want to reprint all the programs for me. I reckon that's just slack and a lack of foresight.
00:00:48.960
But, um, that of course means that I can say that we're enterprise now. So, now that I've got all the basic keywords out of the way, I'll start the talk.
00:01:02.460
First off, I'll just tell you who I am a bit. You may or may not know who I am. I started a company called Reinteractive. We're a development shop in Sydney with about 13 people now, I think, spread all over Australia.
00:01:13.500
In fact, three of them are here. We don't actually have an office, so we run everything remotely, and all of our developers live and work from home. We only catch up once every month or so.
00:01:24.960
This month, we decided to meet up in Austin. It was a long flight—30 hours—but it was a good team meeting, so that was good.
00:01:31.860
We also started stillalive.com, which is what this talk is about; it is a web monitoring service. I wrote the Mail gem—that's my claim to fame.
00:01:44.159
Mail was really funny because when I first started writing it, I was doing this application that used TMail. Who's here has used Gmail? Yeah, I'm sorry.
00:01:56.520
TMail was awesome in that it existed and it worked mostly. But there was this great quote from causes, Mike Kozlowski. He said that TMail is really good at detecting spam because all you needed to do was wrap TMail in a begin-rescue block, and if it crashed, it was probably spam. You'd just delete it because it couldn't handle malformed emails.
00:02:14.580
This wasn't working very well for what I needed out of ActionMailer, so I decided to write a Mail gem, thinking, 'How hard could that be?' Anyway, there are 24 RFCs that you have to go through to get Mail working, and it took me two years, but we got it written.
00:02:30.900
My most proud achievement is that—last night at Ignite RailsConf, I found out that my net contribution to Rails, even though I'm in the top 20 committers, my net contribution is minus 24,000 lines of code from the Rails code base. And I'm so happy about that. I mean, that just rocks.
00:02:43.140
So, yeah, I'm a Rails Commit Team member. I'm a self-taught developer. I didn't really study much computer science. I tell you, going from a business degree at university, going from a business degree to writing parsers for email is about as vertical a gradient as you want to make in computer science.
00:03:02.220
But it was a lot of fun! I blog at lindsaar.net, and I tweet at Lindsaar. Feel free to ask me any questions.
00:03:20.159
So, what's this talk all about? This talk is about how to bootstrap a startup on the side. Okay, we all have our jobs. We might even work for companies that have startups they want to do on the side, and how to get that running.
00:03:32.159
There are some pain points involved in that, and this talk is going to cover how you go from zero to a lot more than zero, and how to produce an application that's actually working. The talk is going to be more than just technology; I'll go over a few technology points.
00:03:49.980
Obviously, we're going to cover some database issues and pain points we ran into there, some stuff on queuing, and a few other topics, but it will be a generalized talk.
00:04:03.060
Where do I get this data from? Mainly, it's from when we screwed up in the application; the servers crashed. I want to try and impart some of that knowledge to you so that you don't also have that sort of problem, and when they do crash—because any app will crash—how you can mitigate that and recover from it quickly to get back into action.
00:04:18.959
Also, I will share my own practical experience because we've got Reinteractive, which is a development company; we do a lot of Rails maintenance and support for Rails apps that we didn't build. We look after many Rails apps, so there's a lot of practical experience there.
00:04:31.560
We were then able to fold back into our experiences with Still Alive and my hard-won knowledge.
00:04:44.100
First off, I'm going to give you a little bit of a description of what Still Alive is so that we're all talking on the same page. So, does anyone here actually use it? Ryan, you're awesome, but you don't count. Who's that? There was a hand—yay, you're awesome!
00:04:58.199
So, what's Still Alive? It's our attempt to help you catch every bug on your website before your users do. That's a pretty big statement! What we actually do is we conduct live tests against your full-stack production environment.
00:05:18.060
So, we're not just checking that the front page is up or anything like that; we're doing a live production test. The best way to explain it is with a very short video.
00:05:29.460
You have a website that’s an online store selling pictures. It has a lot of complex moving parts, each working independently. But what happens when a part of it breaks may not be immediately noticeable. Your site may even look like it's functioning correctly until you find this in your inbox.
00:05:50.940
So, what's a person to do? A simple ping check won't stop this from happening again. That's why we created Still Alive, a website monitoring tool that tests the individual features of your website, not just whether a user can see a page.
00:06:09.000
You can be certain that whenever anything on your site breaks, we'll let you know before your users do. It's really as simple as using Capybara against an external website. I mean, that should be easy, right? Just, you know, when I go to google.com instead of when I go to example.com.
00:06:26.039
Anyway, we thought it would be really simple, but what does production testing mean? Well, it's really a smoke test of your production environment.
00:06:37.940
You're obviously not going to run your unit tests through Still Alive—if you do, let me know, and I'll send you a free membership for a year—but it's really about smoke tests following the common application paths that cover all layers of your stack.
00:06:50.580
A lot of you, if you run a production site, probably have some service like No Ping or Pingdom that checks your website's online status. Your front page has an H1 tag on it, and that's good, but in the modern days of web browsers and web applications, often your homepage will come up, and your database can be out to lunch.
00:07:02.640
It's not until you try to log into your app that you find out that the session table's full or you've run out of space to save a new image or something like that, and that's what Still Alive is designed to catch.
00:07:20.640
It's these full-stack tests. We have people doing shopping cart checkouts with Still Alive every minute of every day using a dummy credit card number. We have people signing up for their service every minute of every day with a dummy user ID.
00:07:36.000
We also have people navigating around the entire dashboard and all the major screens to make sure that nothing returns a 500 error. These scripts are only about 15 or 20 lines long because, when you think about it, modern web applications have a few happy paths that customers will generally follow.
00:07:47.520
That's the sort of thing that Still Alive can handle. We also do deployment testing, where, when you push a new set of code to servers, the first thing you really want to check is, 'Did it break anything?'
00:08:02.520
A lot of people will just start clicking around as developers, which is better than nothing, but it's very random. So, we have people using Still Alive as a smoke test post-deployment.
00:08:20.400
If the deployment happens and blows up, they get alerted, and they can roll it back. In about three to four weeks, we'll be releasing an API which will allow you to pull one app server out of the cluster, upgrade it to the new code base, and check its health.
00:08:43.260
If it's all okay, it will return a positive response and your deployment can continue. If that returns false, then the deployment can roll back and that can be fully automated so that you don't have the fear of hitting deploy on your website anymore.
00:09:07.620
You can just deploy it and, yeah, thanks. So, what we have is a lot of demand for that, and it will be up soon. We actually needed this as a solution for our clients. We monitor a lot of people's websites, and clients really love it when you email them to say, 'By the way, your site was down for three minutes today; we fixed it, and it's all good.'
00:09:32.460
So, Rails Rumble was coming up, and we decided to build Still Alive for Rails Rumble. This was a triumph, and I made a note here to say that it was a huge success. If anyone understands the Portal song, I'm really surprised that no one got that. Did anyone get that? You know the 'Still Alive' song? This was a triumph—I made a note here, huge success. If you haven't played Portal, there's one takeaway from this talk: go play Portal.
00:09:55.800
The technology that we use is Rails 3. We have these workers that check the websites—they were using Capybara and Mechanize, but we've now got them running on Capybara WebKit. They're very forked versions, but that's what they are.
00:10:13.920
Our queuing is handled by ZeroMQ, and we're using Chef for configuration. I'm going to go through all of those now.
00:10:36.300
So, the first part I want to talk about in scaling your startup is that we are not talking about a startup where you've received 14 bazillion dollars from 15 archangels, and now you want to produce an online store selling pictures of cats.
00:10:48.000
We're talking about how to get your startup running on the side—the project you've always wanted to do—and how to get it up to a point where it's profitable. That's what Still Alive is.
00:11:00.360
The first thing I found is that you have to start simple, and it's critical that you start simple. One of the really cool things about doing our initial launch and coding out of Rails Rumble is that it forced us to be simple.
00:11:17.300
Who here has participated in a Rails Rumble? Yeah, they're awesome! Does anyone not know what a Rails Rumble is? A few? Okay, so Rails Rumble is basically a 48-hour competition where you get a team of four people together, and in that 48-hour period, you have to design, code, and release an application that does something useful.
00:11:45.579
You've got 48 hours, and it's a competition. Then, all the applications entered get rated based on how complete they are. Some really cool apps have come out of this. We did this two years ago and got it done in that time.
00:12:08.520
What it does, though, is that when you have four people working for 48 hours, you really only get about 130 hours of development time, so it forces you to tighten down on what your core features are and only focus on those.
00:12:27.780
So, if you're starting a startup and you have this idea, the best thing you could do is set yourself a hard deadline and say, 'It's releasing on this date, come hell or high water,' and just get it out on that date.
00:12:49.920
What this will do, by setting that date, is it will start a mental process in your head where you start rejecting features that are too complex or too fluffy and really focus you down on what's important.
00:13:04.600
The other thing that Rails Rumble taught us was that, at the end of that Rumble—when I say we built Still Alive in 48 hours, we did—we built it in that time, and I've spent the last year and a half fixing it. But it worked mostly—it was pretty good.
00:13:18.300
What it really did was validate us because we got hundreds of users in that first week; so many people signed up, and we started getting feedback instantly. The things we thought were important weren't really important, and the things we hadn't considered turned out to be vital.
00:13:35.200
Then we could really focus, which brings us to the next point: you have to focus. Once you have your core basic system out, you want to focus on the key features.
00:13:44.500
For us, the core features of our app are that the worker works well. The worker in our app is the piece that does the testing on the website, which is critical—if that doesn't work, we’re basically screwed.
00:14:01.320
We've just done a spike of development where I had half time and one of our developers full-time for five weeks on getting new features into the worker.
00:14:23.060
At the end of that sprint, the front end users won't see anything that has changed on Still Alive, but it will be a much better, more advanced worker.
00:14:39.120
The other things that are important to us are the site's stability; the last thing you want with a monitoring service is to go to the monitoring service and find that the site is down.
00:14:50.220
That's not good! That's happened a couple of times, and we get some really interesting emails like, 'Hi, guys, just thought you might like to know you're down.'
00:15:05.100
The next worst thing is false alarms because the next on the list is waking someone up at 3 a.m. telling them that their site is down only to say, 'Just kidding, sorry, whoops.'
00:15:18.960
To give you an example of how focusing on the worker improvement can yield results, one of the things we recently did was to take Capybara Mechanize out and replace it with Capybara WebKit.
00:15:38.460
We're doing this as a parallel test, and I was really hoping to launch it today, but it's not quite ready. It's probably going to go online tomorrow or the day after.
00:15:48.300
What this gives us, of course, is full JavaScript testing ability. You can use Still Alive to check your Backbone app; it doesn't have to be just HTTP requests—it can handle everything.
00:16:02.520
One issue we encountered with Capybara WebKit was that it can pull in many external dependencies like images and fonts. Our traffic on the utility boxes was relatively low running Mechanize, but when we switched over to WebKit, it exponentially increased because it was pulling down everything from ads to analytics.
00:16:18.960
So, we pushed a fix for that up to Capybara WebKit; now there's a flag to turn off image loading. We also added support for Blacklist URLs—that was a fun problem.
00:16:39.240
We started testing all these servers in parallel, and we ran into a situation where some users were mistakenly thinking we were terrorizing them with traffic. We didn’t really communicate this to our users because they would see an extra request each minute, and no one would care.
00:16:53.859
But we received about 15 emails saying, 'What the hell are you guys doing?' and we had to explain that our testing service was the cause of the happenings.
00:17:11.520
We added blacklist support so that Capybara WebKit can accept a list of URLs that will just never be visited, preventing things like Google API and advertising servers from being loaded.
00:17:29.460
Reliable timeout handling, however, is another issue that we hit. If you ever clicked a website with a bad net connection, how long does your web browser wait until it says it can't be reached? It's often 10 or 15 minutes.
00:17:42.960
If you’re testing a thousand sites and one of them goes down, the worker now won't do anything for 15 minutes while it waits for WebKit to timeout, which is not useful.
00:17:53.179
So, we hacked in a timeout that we are setting up as a pull request; these are all points where you're focusing on the core functionality of your application.
00:18:06.600
Another important part when scaling the features of your site is to engage with your customers as much as you can.
00:18:19.300
Now, obviously, if you don't have millions of dollars, there’s only so much you will be able to do in terms of engagement, especially if you've got your day job.
00:18:30.600
But the key is to just remain in communication with them. If they say that something isn't working, send them an email saying, 'Thanks for letting us know; we'll get to it as soon as we can.'
00:18:43.860
But don't feel pressured to just implement everything that everyone wants instantly. That could lead to major pitfalls.
00:18:55.440
What you're going to need to do is really target and choose the requests that give you the highest return on investment.
00:19:08.879
You don't want to mindlessly introduce every new feature that comes along your way, so play a curator role. If someone wants feature A, say, 'Okay, thanks; I'll add it to the list.' If you can implement it right away, and it's along your development path, go for it.
00:19:27.480
But you need to make that judgment call.
00:19:41.520
What we came up with was performance scaling in terms of monitoring. There are several ways you can scale the performance of your site.
00:19:52.420
If you're not monitoring your site, it’s almost pointless to do any sort of performance scaling because you won't even know what the problems are.
00:20:07.020
So, we break our monitoring into three broad areas.
00:20:13.500
First is user experience alerts. Now, we actually use Still Alive to test Still Alive! Yeah, we use our own dog food.
00:20:24.480
That might sound a bit stupid because if Still Alive goes down, how are we going to monitor that while it's down?
00:20:36.840
Believe it or not, monitoring our own service with Still Alive has found about five incredibly hard-to-reproduce bugs that we've been able to solve.
00:20:54.500
So it's good we use it ourselves; we also use it on all our client sites. This ties back to what DHH was saying this morning: great tools are made by people who use them.
00:21:09.120
One day, when we were first getting our monitoring set up, I got woken up one night because of false alerts. I swear I spent two days doing nothing but fixing that so I wouldn't get disturbed again.
00:21:25.900
Still Alive is good for detecting broken type alerts and that's about queries taking way too long and timing out; your web app notifications.
00:21:35.620
One of the reasons it's good at identifying when a query is taking too long is that if you've got a Rails app hooked up to AirBrake and your query takes so long that Nginx kills the Rails process, you won't necessarily get an AirBrake alert. It'll just be a timeout.
00:21:49.460
The first we knew about this happening was a Still Alive alert coming in saying it couldn't log in. We thought, 'What do you mean it can't log in?'
00:22:04.900
Then we tried it and could log in, but one user couldn't log in while Still Alive was trying to log in at the same time, and it would crash without sending any errors.
00:22:13.680
It's an impossible situation, but because we had this system, we found it out. I'm going to go over what that problem was later in the slides.
00:22:26.640
The next type of alerts we run is system operation alerts. These check really core features of your application. You don't want to do massive checks.
00:22:40.920
What we do is we run a cron check hitting a URL in our application that evaluates a quick internal systems check.
00:22:58.680
We check two key metrics: how long ago the last result was generated by Still Alive and how many scripts are waiting to be executed.
00:23:09.380
If either of those gets too big, we know we've got a problem, and that command starts alerting everyone.
00:23:20.520
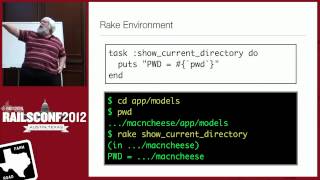
I hope my mobile phone doesn't go off during this talk! We do this with Cron by hitting the URL. The reason we do it this way is to reach the full Rails stack without booting Rails.
00:23:30.780
There's another common method where you go, 'Rails script execute' followed by method name to call, and it will return a result. But the problem is that it has to boot the Rails stack to run that, and that can take 30 to 50 seconds.
00:23:42.900
If you’re doing it every minute, suddenly you start overlapping, right? So, this method hits a production app server that's already running, and that request happens in about half a millisecond.
00:23:57.900
If something goes wrong, then the Rails app will take longer to respond, and will send out SMS alerts.
00:24:15.240
Another benefit of using Cron is its reliability; it just doesn't break. Once we coded it, we never had to touch it.
00:24:32.300
The other analytics you want to have running on your startup include entries from PostgreSQL slow query logs; those are valuable.
00:24:43.680
Rails log files are useful for tracking down specific requests. Having exception notifications—something like AirBrake—is incredibly useful too, and New Relic is helpful for digging into issues.
00:24:59.480
But yeah, using PostgreSQL monitoring has saved us many times.
00:25:12.000
These are the broad types of alerts that you need to run. One of the lowest hanging fruits in terms of increasing performance in any Rails app is the database layer.
00:25:25.500
Generally, unless your app isn't doing many database calls, you can achieve significant performance improvements.
00:25:40.020
The lowest hanging fruit of the lowest hanging fruits of database performance is indexing.
00:25:55.240
In PostgreSQL, there's this command called 'EXPLAIN ANALYZE.' Who's familiar with that? About half the room. The rest of you must be using MySQL.
00:26:08.640
We had a query that was taking four minutes to run; this was causing problems whenever a user logged in. When someone would log in at the same time, it would crash.
00:26:23.620
The reason was that it took so long to run, so they clicked refresh multiple times, and eventually all our app servers would try to execute that long request against the database, causing it to struggle.
00:26:39.480
Let me show you what this four-minute query was. It was a simple select from results with order by created at descending limit of 50. It shouldn't be taking four minutes.
00:26:55.040
We had an index on site ID, and we had an index on creator, but the query planner was doing a full table scan of 30 million rows.
00:27:06.040
It confused me at first because I know a fair bit about database queries, but I was sure that it must have a problem.
00:27:18.580
So, what 'EXPLAIN ANALYZE' does is print out how it worked out the query planner execution for this SQL. What on the third line from the output said it was going to do an index scan using the index on created at, which made sense.
00:27:29.200
However, underneath, it says, 'Filter: site ID equal to X,' and that expression wasn't using the site ID index. So, what ended up happening was a full table scan of 30 million rows on a database without enough RAM to hold it.
00:27:43.380
The solution was to add a compound index on both created at and site ID. That reduced the query from four minutes to 0.448 milliseconds. I was pretty happy!
00:27:56.060
Now you can run the same 'EXPLAIN ANALYZE' on that index, and it shows it's doing an index scan on site ID and created at and generates results much faster.
00:28:09.460
But now we hit another problem: how do you add a new index to a 60-million row table that's getting 2,000 inserts a minute? When you index a table, it locks, and it won’t let you add or delete records until it finishes.
00:28:35.000
That means, if not using PostgreSQL, you just go down for an hour while you update your index. So, luckily, we have technology—we have concurrent indexing.
00:28:51.740
Who’s heard of this? Okay, good. Concurrent indexing is useful: it allows you to use the word 'concurrently' on the normal index statement and build the index while your database is running.
00:29:05.000
It works by doing two full table scans of the database, taking the first snapshot and then playing back all transactions and then doing another table scan.
00:29:21.000
This allows you to add an index without taking your database offline. However, it takes a lot longer to run—more like three to four times the time of a standard index.
00:29:39.980
An indexing operation that normally took about 45 minutes in production would take close to 2 hours, but you'd have a running service with no issues for the users.
00:29:56.620
However, you can't do this in a Rails migration; all migrations run within a transaction block, so you need to SSH into your server and execute it directly.
00:30:09.760
The other useful aspect of concurrent indexing is when you need to re-index a table. The problem with re-indexing a table is that it locks your table; you won’t be able to read or update.
00:30:29.120
If you need to re-index, create a new index with a different name, give it the same constraints, build it concurrently, and then drop the older index.
00:30:43.640
Another issue we've hit is our queuing. Does anyone use queuing in their apps? Yes? It's a common problem.
00:31:00.840
Our old queuing system, which we are still migrating away from, used Delayed Job. While it's simple and effective, it needed a direct database connection and consumes ample RAM.
00:31:17.800
Each Delayed Job worker was consuming 450 MB of RAM just to boot, and this proved problematic as we wanted distributed workloads across cheap servers.
00:31:34.820
The old queuing system had a heavy footprint and choked the database server with too many connections, resulting in no profit for us.
00:31:51.640
At RailsCamp, a collaborative conference in Australia, we decided we wanted a new queuing system that worked. We wanted to distribute workloads alongside individual gems that did one task efficiently.
00:32:09.760
We wanted those workers to be lightweight and limit RAM per worker to approximately 100 MB.
00:32:27.540
The model I wanted involved a database publisher that published the jobs, a worker doing the job parsing, and a sync to drain all the results.
00:32:51.240
This is so we can build a system that efficiently runs workers independently without relying on a central message broker, which I find burdensome.
00:33:07.740
On a friend's recommendation, I discovered ZeroMQ, a socket library for network ports. If you put a job on a socket, it reaches the first worker available instantly with no polling needed.
00:33:32.460
I will provide a demo of this functionality shortly, which helps to illustrate just how powerful this system can be.
00:33:51.680
This is a simple Ruby script that demonstrates the publisher, which will send out the jobs into the queue.
00:34:05.520
The workers will pull jobs from the publisher while running. This setup should yield efficient task management.
00:34:20.060
I'll run this demo now and show how effectively ZeroMQ operates. By triggering the ventilator, it sends jobs to the workers waiting for tasks.
00:34:35.160
The distribution happens seamlessly, showcasing the advantages of not having to rely on a central broker. The results are processed quickly, highlighting the performance efficiency.
00:35:02.660
Overall, ZeroMQ is a highly stable and scalable queuing solution. Its lack of a central broker minimizes overhead while allowing us to add or remove workers dynamically.
00:35:23.440
We also extracted the concurrent job processing functionality into separate gems to interact independently with the queue.
00:35:38.680
This means that we now have a streamlined process where nodes can quickly deploy their required tasks without overhead.
00:36:01.880
The last area I want to cover is process scaling. When running businesses on the side, ensuring you're not wasting time is crucial.
00:36:14.720
One effective measure is to standardize your actions. We originally ran all our staging servers on Heroku because it was cheap, but it was not smart.
00:36:36.220
The reason it wasn't smart is our production servers run on EngineYard, so our staging environment had different underlying technology.
00:36:53.580
Although it never caught us in a big way, that inconsistency created hurdles in our testing. Therefore, we moved our staging environment back to Engine Yard.
00:37:10.480
This allows us to spin up and down snapshots as we need without concerns—a valuable move when you're running on the side.
00:37:26.760
The application deployment is critical for a startup; automate it as much as possible and document extensively.
00:37:37.740
You may not commit to your code base for a month or two due to busy schedules, so you need clear documentation on how to deploy when you return.
00:37:49.640
We’ve streamlined our deployment to a single command; it deploys to all servers efficiently.
00:38:05.180
It's important to ensure zero-downtime deployments whenever possible. We use Unicorn for that process, allowing for smooth, continuous service.
00:38:19.860
When reloading happens, Unicorn forks again and kills the old workers while users do not notice any downtime.
00:38:44.240
Automation is key; without it, you'll often find yourself caught off-guard during crucial periods.
00:39:01.300
Application configuration is another essential aspect. Using tools like Chef ensures that everything runs smoothly.
00:39:16.980
An example is being able to rapidly spin up new workers effortlessly, allowing for easy scaling.
00:39:36.720
The time spent setting this up is returned many times over, especially when it comes time to do a broader scale.
00:39:54.520
The most significant point is ensuring that you automate where you can. Standardizing actions saves you resources in the long run.
00:40:16.540
If you engage in a diversity of practices as you run operations, it turns into a chaotic experience that no one wants.
00:40:37.440
So, to summarize, in scaling your startup, start with feature scaling: focus on key issues and high-return actions.
00:40:55.380
Put a deadline on it and stick to it; stay in communication with your clients. The most important is to adhere to deadlines.
00:41:15.560
Performance scaling utilizes database tools; if your database doesn’t have tools, consider switching databases.
00:41:26.880
Employ external monitoring systems like Still Alive, and maintain smaller, tighter code chunks.
00:41:42.760
Simplify responsibilities in your codebase to isolate issues when they occur.
00:41:54.740
Avoid loading your Rails stack for background jobs—it will just end in tears.
00:42:12.740
Process scaling means having a dedicated staging environment that mirrors production conditions.
00:42:30.920
Make continuous deployment standard, implement configuration management, and prioritize automation.
00:42:50.200
Lastly, I have a 30% off promo code if you sign up for a trial at Still Alive: you’ll receive 30% off when your billing cycle starts.
00:43:02.760
Thank you very much for listening to me for the last 45 minutes. I will now open the floor to questions.
00:43:47.480
Thank you.
00:43:53.460
Thank you.