00:00:20.990
All righty, how's everybody doing today? Alright, today I'm talking about building your internal tooling from the console up.
00:00:28.439
I want to start with an initial question: How old is your codebase? Just by a show of hands—nothing I'm going to be able to see all of you all that well just because of the lights coming in here—but how many have apps that are essentially Rails and less than six months old?
00:00:39.660
A few more, six months to 18 months? Okay, eighteen months to three years? Alright, and more than three years old?
00:00:44.910
Okay, the vast majority of you are here. So I'm going to set up some central questions that I want you to keep in mind throughout the course of the talk. When is a good time for a team to start making their internal life better?
00:01:08.520
This is essentially when you start building an application—you're really starting to solve an external need. Generally speaking, when do you start paying more attention to what your internal needs are? What might that look like? Who should advocate for it, and who should do it?
00:01:26.610
About myself: I am a senior developer and team lead of an education-focused eBook store, and my team builds the store on a Rails codebase. We aren't using anything other than Rails; we're not using Active Merchant. Well, we're using Action View in a few areas and stuff like that, but we basically built a custom app for this.
00:01:53.420
I am one of three production key holders, and I review a lot of code. So our store looks like this. Internally, we call it Stargate. On the administrative side, we have a rudimentary interface with some nice graphics and a few things that we take care of in terms of administrative tasks.
00:02:06.420
One of those tasks is looking at our 'catalog imports', which essentially describes our inventory ingestion process. I checked all this out earlier, and I noticed that my full frame screenshots were very tiny from the back of the room, so I tried to make these big—for the back of the room folks.
00:02:29.010
Here you'll see the type of inventory import we're doing. The next two columns don't get used a whole lot. They track how long things have taken, who started them, and whether or not they were successful.
00:02:37.650
About halfway down, there's something called 'In Progress', and we'll talk about that a little bit more. The application itself is currently running Rails 5.1 and Ruby 2.5, with React for the front-end. There's a fair amount of Active Record feeding into React as well, and we use MySQL and Redis for data stores.
00:03:11.040
For background job processing, we use Kick and Kubernetes on Google Cloud for deployment. This is pretty much an app that is situated at the sweet spot of Rails. We're not doing terribly hard computer science—we're not inventing any new algorithms for this sort of thing; we're running an online store.
00:03:47.040
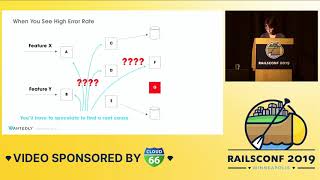
I spend a lot of my time helping my team, which reflects how I spend a lot of my time helping them find answers to questions that they can't find on their own. It's not because they're not smart people—I work with some very, very smart people—it's because they don't have access to find the answers themselves.
00:04:07.769
Accordingly, I am a bottleneck of knowledge and access. Now, if anybody has read The Phoenix Project, what kind of character defines Brent in the book? Brent is a focal point of multiple team dependencies. He can't focus because he either seeks out or gets pulled into every emergency or emergent situation that comes up, spending all his time being a firefighter instead of being a mentor.
00:04:21.239
My situation is not nearly as bad as what is conveyed in the book about Brent—it's not catastrophic, but it has, at times, been incredibly frustrating feeling the weight of expectations and demands on my time. I want to make this dynamic better; I don't want to be Brent, and I don't want anyone else on my team to be Brent either.
00:04:56.130
So, what are we going to cover? We're going to talk about some overarching goals for this. I’ll build up the state of the world for how my application is presently, and I'm hoping that you all can find something to relate to in where your apps are at. We're going to talk about some initial pain points, the approaches to problem-solving, and then we will step up from the Rails command line and console.
00:05:26.730
Next, we'll go into some initial automation and notifications. We'll take an opportunity to reevaluate our pain points, look at some administrative frameworks, and then we'll discuss building your own tools. Our goals include making problems easy to see, evaluate, and act upon for the entire team; we don't want to limit who can see if a problem exists.
00:06:18.300
We want to limit keyholder-specific tools to being rarely needed, well-defined, and basically used for higher risk situations. We intend to develop, observe, evaluate, and iterate on this initiative so that we can build on it over time.
00:06:39.060
Some further goals include less involvement for myself and the other production keyholders in emergent situations. And when I say emergent situations, that means something with some sort of business urgency that isn't necessarily an emergency—just something unplanned that comes up.
00:07:01.690
A lot of it can boil down to a publisher we're doing business with not having an answer for why their particular title isn't in the store. Someone has to go find that answer, which is an emergent situation; an emergency would be the store being down.
00:07:35.340
We want to facilitate fewer emergent situations overall by providing proactive tools that help folks discover and address problems quickly or find the answers to questions they may have. I want to take the time I'm currently putting into these emergent situations and redirect that into longer-term mentorship, helping my team improve the tools they work with to better answer their questions and operate the site.
00:08:08.520
Ultimately, I want to ensure that neither I nor anyone else on my team becomes Brent. Some caveats to acknowledge: this is all a work in progress, and I'm okay exploring ideas that will make our collective lives better—this is all iterative. I don't want this to be a final state in any sense of the word.
00:08:40.770
In the world-building context, the codebase here is about four years old. It was started with a consulting company, and over time we've both grown and scaled down the consultancy involvement. The team turnover has meant that all development efforts have primarily been around implementing sales-focused features and solving external problems.
00:09:01.860
Not so much on addressing our internal life. Production access is limited, we have some notifications for automated jobs, but not all of them, and production access is required to determine the state of automated jobs and generated artifacts—our feeds that go out to search indexes.
00:09:20.790
Problem-solving presently involves a lot of ad hoc Rails console or database digging. We have a constraint of only three keyholders, and the vast majority of these operational questions require this specialized access.
00:09:47.730
We need to reset stale data and investigate error states of transactions, such as customers attempting to make purchases on the site. Troubleshooting and restarting failed jobs, like inventory ingestion, is another main issue. Additionally, we need to find and verify artifacts—for instance, ensuring our site maps and store feeds to external sites succeed.
00:10:20.400
Contact switching is painful. I find that disruption from these emergent situations and ad-hoc requests is a productivity pit, manifesting in my spending a lot of my time context-switching or answering questions instead of focusing on feature work or team mentorship.
00:10:51.790
For example, we will have ingestion failures, notifications to third-party sites failing, questions from publishers asking why a title isn't listed in our inventory, troubleshooting payment transaction problems, and notifications failing to send, like password reset emails.
00:11:24.360
We also occasionally experience DDoS issues, overly aggressive site crawlers from search engines, fraudulent purchases, and just all the general issues that can arise from running an e-commerce store. Some of these are one-off, others ongoing and cyclical, with strong sales cycles tied to college semesters.
00:11:50.720
So how can we begin improving this situation? We can approach the issues iteratively. Define the issue: this could be a simple restatement of the problem. Who has the issue, or who has to address it now? This means identifying the limited population of team members who can actually address the issue.
00:12:16.110
What makes that true, and who could potentially address the issue if prior constraints were removed? How can solving this issue be easier—meaning prevention, easier mitigation, and higher visibility that sorts of things?
00:12:53.410
We need to define visibility for the issues. We'll talk about chat alerts and notifications, utilizing monitoring with New Relic or Skylight, or operational dashboards that cover various problems such as payment issues, fraud, inventory operations, or periodic job schedules.
00:13:11.990
Moreover, we want to improve resilience. We should make expensive processes, like our sitemap extraction, more fault-tolerant. This process takes multiple hours to extract content from our inventory and write it to XML files.
00:13:58.470
Instead, for less expensive items, we should make recovery from failure easier. Having a well-defined path for rerunning tasks allows for practical recovery. When addressing problems like this, think pragmatically—let individual circumstances dictate how you approach issues rather than sticking strictly to general principles.
00:14:51.669
Involve your team in the problem-solving process. Socialize the issues, review, and iterate solutions with them to avoid bottlenecking the process with just one person working on the problem.
00:15:07.800
For my team, we have a rotating responsibility known as a point developer every couple of weeks. This person acts as technical triage for bugs and general questions, serving as a focal point of interruption for business stakeholders, product managers, and business analysts.
00:15:44.380
As time progresses, we aim to improve internal tooling, allowing point developers to be more effective. Currently, we're refining what this responsibility entails, and maintain a daily operations spreadsheet monitoring various issues.
00:16:05.400
We assess any alerts or spikes in system performance; we check if catalog ingestion is working correctly, and ensure background job processing works as expected. Now, let's start making some improvements.
00:16:43.440
We're beginning with the command line in Rails console. The console is useful for investigating data and state changes, and it allows for one-off fixes and testing new classes and methods against production data.
00:17:35.820
You can even write SQL queries directly within it, which is handy when lacking live access to a database server. We utilize it to check error states on pending transactions, troubleshoot missing inventory items, toggle feature flags, and make data corrections as requested by our business partners.
00:18:48.810
The benefits of using the console are its ad hoc nature; you have scope visibility into your production data without needing special access. However, this comes with limitations—you're conducting work in production and aren't saving any artifacts or records of changes for review or auditing.
00:19:17.520
To enhance our approach, we should first plan actions in a non-production environment. This is an ideal time to collaborate with a peer who isn't a production keyholder, so that they can understand your plans while gaining experience.
00:19:59.640
You must also inform your broader team of your intentions, detailing what you're doing and how, when, and why it will take place so they are aware of the actions being taken.
00:20:34.440
Next, as part of our strategy, we will automate as much as we can and make processes visible. Initial automation has improved our system's visibility. However, we have a considerable amount of alerts in our system, and it can become noisy if something goes awry.
00:21:34.920
It's critical we understand which notifications are beneficial and which may be unnecessary to prevent overwhelming our teams with information that doesn't point towards actionable insights.
00:22:20.570
Our automation efforts include tasks that repeat periodically. Once you notice a pattern, apply some effective automation tools—whether using rake tasks, scripts, or other methods to manage these recurring issues effectively.
00:22:54.630
For instance, we have found that we can quickly carry out the catalog range renewal for our inventory ingestion process with a simple rake command. If it fails, we have established a quick rerun path, enabling us to address issues more swiftly.
00:23:50.090
Now we're at a point where we can start reevaluating the improvements we've implemented. While we've talked about the Rails console, ways to enhance automation, and notifications, we still haven't addressed the bottleneck issue.
00:24:30.780
Next, we can explore administrative frameworks like Active Admin, Rails Admin, or Administrate. These frameworks provide a broader view of data—even showing order and customer details in an organized format—for production keyholders to conduct inquiries without constant intervention.
00:25:01.290
However, caveats remain; ensure that these frameworks are integrated with your authentication and authorization schemes. You don't want to expose sensitive production data to just anyone—protect access appropriately to prevent misuse.
00:25:57.400
If your needs go beyond what existing frameworks provide, consider building your own interfaces. This would allow for representing complex workflows, rather than strictly data presentation, streamlining processes further in response to your unique operational needs.
00:26:30.760
For instance, in our case, we currently employ an interface for currency conversion to manage products priced in U.S. dollars sold across multiple countries, which compensates for a lack of local pricing data from publishing partners.
00:27:00.080
We may also want to evolve our data alert system instead of dumping everything into Slack. By creating a dashboard within our app, we outline actionable insights, reducing the need for manual out-of-band responses to emerging issues.
00:27:46.590
We could also improve our transaction troubleshooting by proactively addressing verification failures and re-initiating processes when needed, thus removing unnecessary friction that currently contributes to users reaching out for support unexpectedly.
00:28:36.460
Additional improvements might include considering automated job processes as a stream of events, allowing teams to easily observe job statuses and errors without deep dives into the system.
00:29:10.880
For example, establishing a clear method for addressing issues that recur enables quicker resolutions, potentially sinking the time spent on both troubleshooting and development efforts into streamlined processes.
00:30:04.500
Remember, tools alone are not the end-all; engaging with your team to identify shared problems and questions helps reduce bottlenecks. Centralizing communication can be very helpful in fostering collaborative and creative solutions.
00:30:34.070
Let’s revisit the central questions posed earlier. When is a good time for a team to improve their internal structure? Now is a fine answer. The extent to which you can act depends on your circumstances, but initiate the conversation about improving your internal infrastructure.
00:31:07.250
What might that improvement look like? It could involve standardizing cron jobs, building an admin interface, or providing greater data access for technical and business stakeholders alike without requiring production access.
00:31:50.500
Who should advocate for these changes? Ideally, all technical practitioners and business stakeholders should support this shift towards improved access to information—to deliver more value without further burdening production keyholders.
00:32:29.140
Finally, what is the necessary time commitment? That varies—20% of time, a week every month, or engaging someone specifically on internal tooling efforts. Review strategies during retrospectives to ensure an ongoing focus on improvement.
00:33:02.290
Leverage the upcoming reviews to communicate strategies and implement potential changes that could alleviate pain points, transforming challenges into opportunities.
00:33:55.600
In conclusion, I encourage you all to explore related resources to deepen the understanding and effectiveness of these changes, such as reading The Phoenix Project or engaging with podcasts that provide valuable insights through diverse perspectives on productivity.
00:34:21.680
These resources guide both technical and non-technical audiences. Lastly, I appreciate your participation in this session; your engagement has made this experience fulfilling. Thank you very much, and enjoy the rest of the conference.