00:00:21.770
Developers, developers, develop! I'm joking.
00:00:27.539
My name is Eric Allen. I can be found on Twitter at underscore ej all day underscore. Give me a follow, and I'm going to be posting my slides as soon as the talk is over.
00:00:32.850
The title of my talk is 'The New Hotness: Hard Lessons Migrating from REST APIs to GraphQL.' Today, we are going to talk about mistakes and frustrations, and how we as developers sometimes make decisions that have far greater consequences than we initially calculate.
00:00:39.600
We're going to dive into some code and I'm going to demonstrate how to eliminate N+1 queries in GraphQL. If you're not familiar with what an N+1 query is, that's okay!
00:00:45.480
N+1 queries present themselves when we query our databases for a collection of records, and we want to get back associated objects. For example, if we wanted to select 10 countries (10 being the letter N) and all their cities, it would take us N+1 or 11 queries to fetch the same data that we could easily fetch in one single query.
00:01:05.190
We're also going to talk about how to think differently about making mistakes, and how we can make better decisions as engineers. Back in January, when I wrote the abstract for this talk, I was pretty stressed out. Our team worked really hard in 2018; we had just completed a front-end rewrite, migrating from a six-year-old Backbone implementation to React, while simultaneously migrating from a REST API to GraphQL.
00:01:34.590
On Monday, January 7th of this year, when we all showed up to work, I think we were all looking for a bit of a fresh start. Instead, we realized that we had some pretty serious problems. That morning, I logged into our New Relic instance and our apdex score was at 0.82, which was the lowest I'd seen it since I started at the company.
00:01:45.770
Throughput was spiking to about 2,500 requests per minute, and response times were anywhere from 2 to 10 seconds. Now, this isn't catastrophic by any means, but we were receiving feedback from our customers that our application was unusually slow, and for a team that takes as much pride in our work as we do, this just felt flat-out unacceptable.
00:02:17.670
As we started to peel back the layers of the issues we were facing, we discovered three key problems. The first was a memory leak in React, associated with password input fields. When they get rendered into the DOM, an event listener gets added, preventing every node and every child node from being garbage collected properly.
00:02:46.890
If you're interested, find this tweet on Twitter; we have a sample application up on GitHub that demonstrates the issue. Feel free to give a thumbs-up to the issue because, even though we were able to sort of isolate it in our application, the issue is still outstanding today.
00:03:05.880
The second thing we discovered was that some of our architectural decisions in our new React implementation severely increased the throughput. We were making a lot more small requests that ordinarily would take about 60 milliseconds, but the accumulation of so many requests was maxing out our database connection pool. Requests were bottlenecking at the database layer, waiting in middleware, which caused requests that ordinarily take 60 milliseconds to take anywhere from 2 to 10 seconds.
00:03:43.709
These problems were exacerbated by the fact that GraphQL introduced N+1 queries throughout our application. So, how did we get here? Before we move forward, I just want to pause for a brief moment and acknowledge that simply giving this talk puts me and my team in a somewhat vulnerable position.
00:04:01.290
I didn't ask for their permission before I wrote the abstract, primarily because I never thought it would be accepted. In the process of writing the talk, it really forced me to confront a lot of my own fears and feelings of imposter syndrome throughout my career because I didn’t come from a traditional software background. I've been writing software for about seven years now, but I come from a finance background, and I've worked in sales and marketing.
00:04:40.080
Having to stand up here and talk about mistakes was a little challenging for me, but luckily for me, the team that I work for is incredibly supportive, and we value learning over everything else. To the people who have been supportive of me, both at Cirrus MD and throughout my career, I just wanted to take a second to say thank you.
00:05:06.400
I've worked at various companies such as Thoughtbot, Ello, and Pivotal Labs, and now I work at Cirrus MD. It's been a huge privilege to work around incredibly talented engineers. However, when you're surrounded by such talent, the bar is set extremely high. In the back of my mind, I had always sworn that I would never submit an abstract or give a talk unless I convinced myself that the subject matter was technically valuable enough.
00:05:40.780
And yet, here I am giving a talk about mistakes. When the talk was accepted, I experienced a moment of panic. I did what most people probably would do and just googled 'how to give a technical talk.' After a bunch of research and reading blog posts and watching other people's talks, most people suggest figuring out why you’re there and why you’re taking up 40 minutes of someone’s time.
00:06:04.270
For me, there are a few reasons. First and foremost, I’m really passionate about my work—specifically performance and API design. I also believe that a huge part of our jobs as engineers is to make quality, well-thought-out decisions that never put our customers or our own businesses at risk. Sometimes our judgment can be clouded because we want to learn new things and work with new tools, and perhaps in those moments we fail to consider the full cost of our decisions to the business.
00:06:48.460
I think as a community we can do a better job acknowledging and talking about the fact that we often have to make really big decisions with limited amounts of information. We make these huge bets on technologies when it's impossible to calculate the short-term and long-term costs of those decisions. Lastly, I wanted to give this talk because I care a lot about this community, and I've really enjoyed working with GraphQL. I hope that by sharing some of the struggles we faced, I can make someone else’s transition a bit smoother.
00:07:40.000
Before we jump into the code, I want to paint a small picture of what our app does. I’ve stripped away as much domain knowledge and context as I can so that the code will speak for itself, but I believe having a basic understanding of what we do will help the code come alive and make it easier to understand.
00:08:00.000
I work for Cirrus MD, where we have created a HIPAA-compliant medical chat platform focused on providing patients with barrier-free access to an unparalleled virtual care experience. What does that mean exactly? It means that anyone with access to our platform can log in and, within seconds, be chatting with a doctor, pharmacist, or financial counselor—whatever their medical need dictates.
00:08:42.000
This is a screenshot from a chat I recently had about my son Arthur when he wasn't feeling well. Upon logging in, a patient sees streams—multiple streams that correspond to the type of care they're receiving, whether it’s from a pharmacist, doctor, or financial counselor. Each stream displays a plan, denoted at the top. In this case, it's the Cirrus MD employee plan.
00:09:12.000
Every stream contains numerous messages, with each message having an author who can either be a patient or a provider. Once the chat is completed, we wrap everything up into what we call an encounter, giving the chat a level of finality, signifying that it's finished. While this application may seem similar to other chat applications you've worked with, the object relationships in our space can be subtly complicated.
00:09:55.000
Like I mentioned, we have mini streams, and a stream belongs to a plan, which has a name and some operating hours. We also have an encounter object that encapsulates all those messages, and then we have our authors, both patients and providers. On the far right, we have our credential object, which we use for authentication, storing emails and passwords.
00:10:35.000
Naturally, when a user logs in, they might hit their streams endpoint to fetch their collection of respective streams that belong to their experience. But what happens when you're logging in from our iOS or Android client? Those platforms will have different data needs, and their connections are likely to be less performant than our web app, depending on their connection.
00:11:05.000
If you've ever had to maintain a REST API, you probably understand the challenge of trying to write one API that serves all the respective needs of each client or the pain of attempting to maintain multiple APIs specific to each client type. These problems are costly for businesses as they require you to write and maintain documentation, ensure backwards compatibility, and slow down your path to delivery since your API team needs constant communication with the client teams.
00:12:10.000
This is exactly why we decided to move to GraphQL. For those of you who may not be familiar with GraphQL, it is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API and gives clients the power to ask for exactly what they need and nothing more.
00:12:46.000
It makes it easier to evolve APIs over time and enables powerful developer tools. GraphQL APIs are organized in terms of types and fields, not endpoints. With GraphQL, you define a type system with queries and mutations, establishing guardrails around your data while allowing each consumer flexibility within those boundaries.
00:13:16.000
The result is an introspective API that self-documents and shows us how to query it. Our perception at Cirrus MD was that this flexibility would grant greater autonomy between our clients, leading to faster cycle times and reducing the coupling between our API and our clients. Not having to maintain documentation was probably my favorite part.
00:13:55.000
On the surface, a GraphQL API doesn’t look all that different from a REST API. In REST, we have many controllers and actions, with index and show actions for reading data, as well as update and delete actions for modifying data. In this example, we have our streams index that returns a collection of streams, and in GraphQL, we have many queries to read our data and mutations for modifying data.
00:14:30.000
In this case, we have our streams resolver, which resolves our streams query, returning the same data that our streams index action would provide. In REST, we have serializers, while in GraphQL, we have types. In both frameworks, these objects determine the structure of the data returned from our API.
00:15:05.000
In our serializers, we define attributes and relationships, while in our GraphQL type objects, we define fields for both our attributes and relationships. Moreover, the relationships in our serializers rely on other serializers, just as the field relationships in GraphQL rely on other type objects.
00:15:37.000
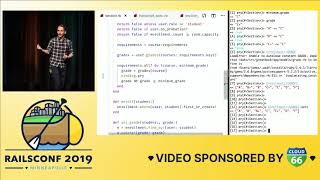
So why, with all these similarities, does GraphQL produce N+1 queries while REST does not? This brings us to our first lesson: eager loading. The first mistake we made when implementing our resolvers in GraphQL was assuming that eager loading would be respected in the same way it would be in a REST controller action.
00:16:28.000
If you think about the fundamental difference between GraphQL and REST, with REST we know exactly what the client will ask for because it's predetermined ahead of time. We can refer to our routes file, which tells us all the options available. It's like a menu of endpoints, meaning every time we hit one of those endpoints, we return the exact same data, allowing us to write efficient queries.
00:17:20.000
However, in GraphQL we can never know in advance what the client might request. Therefore, eager loading in GraphQL is somewhat of an anti-pattern because, even if it does work, you likely end up loading much more data than necessary for each request. For example, consider our streams query: if we request an active encounter along with the provider tied to it and a patient in the plan, this query might be typical in GraphQL. But what if one of our clients only needs a collection of stream IDs?
00:18:20.000
They can use the same query string and just pare it down to only request the ID. So again, if we don’t know what the client is going to ask for, how can we ensure efficient loading of those objects? First, we’ll remove eager loading from our resolvers. As a result, when we load a collection of streams, each stream object retrieved will be handed into our stream type object.
00:19:15.000
Currently, with no eager loading, as each stream is processed, we will trigger queries for the active encounter, the patient, and the plan. If we fetched in streams, we would effectively add three extra queries per stream, not to mention any additional queries triggered by the underlying objects or relationships within those types. This is highly inefficient.
00:19:56.000
We were not the first engineers to encounter this problem. Fortunately, the talented folks at Shopify created GraphQL Batch to help address issues like these. GraphQL Batch provides an executor for the GraphQL gem that allows queries to be batched together. To leverage batching, we installed the gem, added a few lines of setup code, and then defined some custom loader objects, such as a record loader and association loaders.
00:20:30.000
We can modify these loader objects to fit our application's needs. To eliminate those extra queries, we return to our type and define methods for each of the object references, such as the active encounter, the patient, and the plan. Within these methods, we use our newly defined loader objects. We need to do the same for all of our type objects, ensuring that any object relationships within our GraphQL type definitions are associated with their respective loader objects.
00:21:09.000
Once we finish defining these relationships and associating them with the appropriate loaders, we run our streams query again and check our logs. This time, we notice a reduction in our N+1 queries, but we still have more to address, leading us to our second lesson: delegation.
00:21:50.000
In our stream type, we have a patient relationship tied to that stream. When that patient object is handed into the patient type, we use our record loader to batch all the patient queries together. Initially, everything appears fine, but upon inspecting the patient type object, my instinct is that there’s no extra workload here since I don't see any other types being utilized.
00:22:30.000
However, if we examine our patient class, we notice that one of the biggest benefits of Rails is its ease of interaction with complex object models, allowing a language surrounding your domain that’s easy to read. This readability can sometimes cause you to forget where the data is sourced from. Remember the patient credential object where we store emails and passwords?
00:23:00.000
Both patients and providers maintain a credential relationship, but we don’t intend to interact with that credential object directly from our API. Therefore, when calling patient email, we’re actually calling patient doc credential.email. This subtle line of code creates a hidden N+1 query in GraphQL.
00:23:30.000
To solve this problem, we return to our patient type and define a method for email, just like we did for other relationships. Note the `.then` syntax; our record loader object now returns a promise. By calling `.then` on the promise returned from our record loader, we gain access to the credential and can retrieve the email property from it without triggering additional queries. We rerun our query and check our logs again, where we see our credential queries are now batched together.
00:24:21.000
However, we discover other N+1 queries in different areas, which leads us to our third mistake: how we leverage service objects and decorators. In our application, we have service objects and decorators used to present data in a specific way based on various factors. For instance, each plan has predetermined business hours. If a patient attempts to log in outside of those hours, we need an intelligent way to inform them that a provider will get back to them once we're open for business.
00:25:07.000
When we fetch a stream, we provide this message along with the active encounter. The active encounter object is handed to the encounter type, where we have a field for patient queue status and a method calling out to our patient queue status object. However, the moment we observe that the encounter also requires a plan and a stream, we realize that a slight complication arises.
00:25:40.000
In a REST API, eager loading is respected, so this might not cause significant issues. Nevertheless, in GraphQL, this becomes another potential N+1 query waiting to occur. To resolve it, we need to preload all the objects that the patient queue status depends on ahead of time. Additionally, we should update the method signature to allow passing these objects together.
00:26:30.000
To achieve this, we utilize our record loader objects and define a method for the stream object and plan object. The patient queue status object needs all of these items—the encounter, plan, and stream—present before it can be invoked, and since we cannot predict when the promises will resolve, we apply the Promise.all syntax to ensure all the needed objects are ready before calling our patient queue status object.
00:27:01.000
After implementing this last update, we check our server logs... Voilà! All of our N+1 queries for the stream resolver are eliminated. Let’s recap what we’ve learned: eager loading will not be respected with deeply nested objects in GraphQL, so we must use loaders to query our objects efficiently. Method delegation to associated objects introduces N+1 queries, as does relying on decorators and service objects called from your types without preloading all the data they rely on.
00:27:40.000
Today, our app's Apdex score stands at 1.0, with average response times around 60 milliseconds, averaging 550 requests per minute. So, what do we gain by adopting GraphQL? The first and perhaps most important benefit is the significant flexibility in interacting with our API; we've noticed fewer changes required in our API as we introduce new features on the front-end.
00:28:26.000
While I can’t speak to the Android and iOS clients yet, we are just beginning to transition them to GraphQL, and we’re incredibly excited about it. We also gained free documentation, which is my favorite part. Anyone who’s had to maintain an API knows how laborious it is to keep documentation up to date, so this has been fantastic.
00:29:20.000
However, we also took on some new dependencies moving forward, requiring us to rely on the open-source community to maintain those dependencies and ensure that they're up-to-date and secure, especially concerning our domain space. We've lost some confidence, both internally and externally, with our clients—albeit only for a brief period.
00:30:00.000
Another sacrifice was HTTP response codes. Initially, I wasn’t aware that GraphQL always returns a 200 status code regardless of the outcome, unless manipulated otherwise. So even in cases of errors, GraphQL will respond with a 200 code while including an error key inside the response.
00:30:35.000
This means we need to rethink how we handle error messaging in GraphQL, as it differs from typical REST APIs. While it might seem subtle, the absence of 401 or 404 responses alters our approach towards error handling. Additionally, we've noticed a reduction in granularity within our performance monitoring.
00:31:20.000
As our application has aged, I've observed a challenge in adapting our tools to the shift towards GraphQL. We were accustomed to using the Bullet gem to identify N+1 queries in our REST API. Unfortunately, we assumed these tools would function similarly with GraphQL, yet they weren’t designed for that.
00:32:15.000
This is particularly true for New Relic; due to our need for HIPAA compliance, approximately 80% of the New Relic API is inaccessible. When your entire application relies on a single GraphQL endpoint instead of multiple endpoint routes, identifying issues in a transaction trace becomes much more challenging and requires additional code to manage.
00:33:12.000
Any migration from one technology to another carries an opportunity cost. We could have allocated the time spent migrating from REST to GraphQL to developing other features. While hindsight is often 20/20, it’s vital to weigh such considerations when making decisions.
00:34:15.000
Returning to our critical responsibilities as engineers: we must focus on making quality decisions that do not jeopardize our customers’ or our businesses’ interests. We can also enhance our conversations about the implications of our technology choices.
00:35:03.000
I've long felt the struggle, especially as I’ve navigated conversations with engineers possessing Computer Science backgrounds who might prioritise new knowledge over discussing how such decisions impact business outcomes. Recently, our CTO recommended a podcast by former professional poker player Annie Duke, who discussed her book, 'Thinking in Bets,' prompting me to reflect on the essence of quality decision-making.
00:36:00.000
This discourse influenced my thoughts on how we should handle information in discussions. How many of you have been in a meeting where someone presents an opinion as fact? This behavior is toxic; it can create an uncomfortable atmosphere, discouraging others from contributing. We must focus on the costs and benefits of decisions rather than fixing on the right vs. wrong narrative.
00:36:53.000
We should also be comfortable admitting when we’re unsure about something. Often, we feel pressured to appear certain, but embracing uncertainty can make us better decision-makers by accurately representing our levels of certainty regarding decisions.
00:37:36.000
Instead of stating, for example, that GraphQL is the right decision, we might say, 'I’m about 75% sure that GraphQL is the right direction,' acknowledging uncertainty allows others to contribute valuable insights.
00:38:15.000
Once a decision is reached, we must recognize that the decision’s quality isn’t solely tied to its outcome. Sometimes, great decisions lead to poor outcomes for reasons beyond our control; this doesn’t mean they were poor decisions. Great decisions stem from a sound process that accurately assesses unknowns.
00:39:05.000
Linking decisions too tightly to their outcomes can lead to cognitive traps where we make assumptions about causation based merely on correlation, leaving no room for uncertainty—all of which can lead to detrimental decisions in the future.
00:39:47.000
Let’s strive to eliminate bias from our technology choices based purely on our desire to learn something new. We should be transparent about our motivations so they don’t overshadow our decision-making and lead us to choices jeopardizing our businesses. Finally, we should embrace mistakes—not as shameful, but as opportunities to learn.
00:40:53.000
Instead of feeling bad about admitting a mistake, we could acknowledge that feeling comes from potentially missing an opportunity to learn something valuable. We should promote an environment of accountability where mistakes are viewed as lessons and encourage each other to embrace them, as it allows us to grow.
00:42:28.000
I left some time for questions. I will do my best to repeat them and remember to do that. So, the term 'free documentation' relates to a tool in GraphQL called GraphiQL.
00:43:36.000
Inside your Chrome developer tools, you can access GraphiQL, which provides an interactive interface showcasing a menu of various query strings accepted by our API. For instance, if you need patient data such as allergies, date of birth, or medical history, GraphiQL allows you to customize your request and remove unnecessary fields. It's indeed quite a fantastic tool and an exciting aspect of working with GraphQL.
00:44:43.000
The next question concerns whether we've experimented with other gems built on GraphQL Batch. I must admit that we haven't yet. While it’s inspiring how quickly the community innovates and new tools appear, we must make informed decisions based on current information and mature tools.
00:45:23.000
I prefer to be conservative in my tool choices, seeking stability and proven effectiveness, especially in our healthcare domain, necessitating careful selection due to compliance requirements.
00:45:58.000
Furthermore, as mentioned in discussions by other speakers, every tool we select relies on the goodwill of the open-source community, and I envision contributing back to that community as our understanding of GraphQL deepens.
00:46:36.000
Addressing earlier inquiries, I didn’t specify whether I would repeat this experience of migrating to GraphQL, as I am reluctant to make assertions. However, based on my experience in contexts where multiple APIs cater to numerous clients, my answer is yes—I would do it again.
00:47:03.000
However, for applications limited to a single client, I wouldn't necessarily advocate for it, as flexibility remains pivotal for diverse client interactions. And if I were starting a new Rails project tomorrow, I would likely still choose GraphQL due to the advantages I’ve experienced with it.
00:47:36.000
If anyone has more questions regarding the shoulds and shouldn’ts, I would happily discuss those afterward. Lastly, regarding our implementation of fine-grained access control, GraphQL does integrate well with tools like Pundit.
00:48:00.000
In the context of our domain, we manage the consumers of our APIs, which reduces complexity around access management, but for public APIs, I understand that supporting those methods is essential.
00:48:43.000
One question was about handling error responses, given that GraphQL always returns a 200 status code. We ensure graceful failover in our applications through open patterns. Our objective is to minimize error responses and when they do arise, frontend protocols manage them appropriately.
00:49:22.000
Regarding my experiences with mutational queries, I find they operate similarly to reading queries. We utilize an interactive pattern, where objects are responsible for creating data while maintaining their behaviors. More critically, the architecture facilitated smooth transitions from REST to GraphQL, requiring minimal adjustments within our existing frameworks.
00:50:19.000
As for using GraphQL Pro, we haven’t adopted it yet but have considered it. It’s pertinent to mention that during our migration phase, the GraphQL Ruby gem experienced a major overhaul transitioning from function-based to class-based APIs. I preferred waiting for a stable, reliable integration before pursuing upgrades.
00:51:09.000
I wish to engage more with this and if interested, I’d look forward to it, but for now, we haven’t transitioned to that step. Thank you all for your questions! We have some t-shirts and stickers; please come see me after the talk. I really appreciate your time, and if you have any feedback, feel free to share.