00:00:19.260
To the Postgres and Rails 6 multi-DB talk, we're going to discuss some pitfalls, patterns, and performance insights today. Just a quick show of hands—who uses Rails and Postgres together? It looks like just about everybody in the room. Awesome! Who's on the latest and greatest version of both—Postgres 11 and Rails 6? And for those on the latest Rails 5, that's fine too.
00:00:41.040
With Rails 6, full support for multiple database abstractions has been added. This allows read and write databases to be specified at every level of your Rails application, including in rake tasks, active record models, and even filtering API requests based on database selections. So how exactly does this interact with Postgres?
00:01:07.890
Before we dive in, I want to give a quick thank you to the Rails contributors who worked on this project. A tremendous amount of effort went into making this possible, including significant refactoring. A little about me: I have been a Heroku data engineer for about three years, primarily working on Sinatra and Ruby on Rails applications. I've also worked extensively with various SQL and NoSQL databases, but my focus at Heroku has been on Postgres, especially with high traffic loads and large data sizes.
00:01:42.750
In this talk, you will hear phrases that may sound familiar if you are acquainted with Postgres. However, if you would like more information, feel free to come talk to me afterward. Some of these phrases include vacuuming, partitioning, sharding, replication, statistics collection, caching, and connection pooling.
00:02:21.540
I gave a talk last year about Postgres 10 performance, referring to a self-help life coaching business I run, which is currently booming. Many people are interested in motivational materials like success quotes and speeches. We've got customers who sell various products, from inspirational mugs to framed images, targeting shared interests such as favorite quotes, TV shows, movies, food—you name it. Now, we find ourselves up to millions of users and hundreds of millions of data entries per day.
00:02:58.050
However, as our platform has grown, customers are starting to complain about slowdowns. Profile updates take a long time, and they struggle to update their shipping addresses. Customers want to upload their own quotes, but that process is unbearably slow. After initial analysis, we found that the number of favorite TV show and movie characters we track is growing rapidly due to the amazing new shows on various platforms. It's tough to keep pace.
00:03:34.560
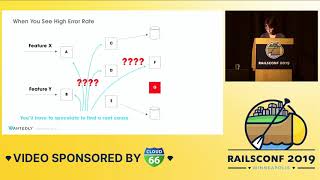
To alleviate this issue, we can move some of the more expensive read queries off to a replica database. This solution could significantly lighten the load on the characters table, which is causing most of the slowdown. However, there’s a catch: I want direct access to use it in my Rails app, but there appears to be a challenge with the CAP theorem.
00:04:08.540
The CAP theorem asserts three tenets: consistency, availability, and partition tolerance. It states that you can only achieve two of the three at any given time. You might compensate for the lack of the third one, but you will never fully achieve all three simultaneously. This framework helps you identify critical failure points and enhance the overall responsiveness, longevity, and stability of your application.
00:04:32.250
How does this framework translate to Postgres in Rails? Characters in our database are numerous, with hundreds of thousands of TV shows and movies and potentially thousands of characters in a single show. They all require constant updates to their information, which we primarily control and update. As the popularity varies for each show or character, the frequency of queries fluctuates as well.
00:05:04.349
Since Rails 6 introduced multi-DB support, we can enable Rails to intuitively split reads and writes, optimizing performance. To illustrate this, let’s look at a basic example of how to split the character data. Let's say 'characters' is a URL we’ve defined in our application configurations. Alongside that, we can create a read replica in a similar way, noted in the database.yml file.
00:05:51.210
Now, we need to define how Active Record connects to it. Thankfully, updates have simplified these connection definitions. By establishing a single table inheritance strategy, we can also pass this connection strategy down to the child classes, such as TV show characters and movie characters. This method allows us to control workloads effectively and enhances performance by prioritizing write throughput versus read throughput.
00:06:36.250
Additionally, you can specify a role for specific characters. Suppose you want to select a random TV show character to start your day; you can specifically ask the database to pull that one character from your read area. If specific operations don’t require the connection to determine whether you should read or write, you can configure it to avoid unnecessary checks.
00:07:09.870
However, we’ve encountered issues where the latest characters uploaded aren’t appearing in the assigned database. Customers aren't seeing their latest additions to their favorites. It seems we are behind on our read replica due to a large number of commits not being replicated. This could indicate a follower lag issue.
00:07:55.200
For those unfamiliar with the concept: Postgres relies on write-ahead logging (WAL) to replay changes, causing more traffic to the primary database. The more write-ahead logs created, the more pressure there is on replicas to keep up and replay them. Various factors influence this delay, and while we can look at whether we are missing any indexes or assessing connection usage, optimizing Postgres for write operations differs significantly from read operations, especially concerning indexing strategies.
00:09:26.870
Let’s discuss using EXPLAIN ANALYZE to identify problems with your queries. By evaluating queries in your Postgres console, you can observe what your Active Record SQL queries are doing and how they perform. As an example, if you're querying for characters from a specific show ID, it’s crucial to ensure that the necessary indexes are in place to avoid full table scans.
00:10:24.890
Without an index on the show ID, you might end up scanning an entire table, resulting in slow performance. Conversely, when you add the right index, you'll see significant performance improvements, reducing the number of rows returned and resulting in a drastic decrease in query time.
00:10:51.790
However, if you check the indexes and still experience lag, there may be other underlying database issues. Heavy primary workloads can impede performance, writing large numbers of updates or quotes each day. Customers are demanding more interaction and reporting that not every character they wish to quote is available.
00:11:43.480
As we enhance user engagement through avenues like adding more quotes, we must also monitor the volume of heavy usage queries impacting replay dynamics. Writing significantly more data creates a larger write-ahead log, adding pressure on replicas to catch up. Connection churn and pool saturation can also contribute to these issues, impacting database responsiveness.
00:12:36.610
Another important aspect is the general size of data affecting indexing efficiency. Larger data sets can lead to suboptimal query plans and overall slower performance. As more data are added, database caches start to churn, making it essential to examine how databases manage these interactions.
00:13:21.210
Postgres has allowed for better partitioning of tables, especially with the recent updates in Postgres 10 and 11. Partitioning older quotes can effectively reduce access data and free up database cache resources, enhancing performance. This feature supports auto-suggested partitioning based on unique indexes and primary keys, allowing for improved query efficiency across partitions.
00:14:32.510
As we partition our quotes table based on timeframes, we can also keep legacy data available without needing to drop it altogether. It’s essential to learn more about these features, so if you’re interested, I'd love to talk more during our Q&A.
00:15:05.760
With the implementation of separate tables for characters and quotes, our data volumes are managed better. However, sluggishness can still arise from an increasingly large quotes table, impacting overall querying.
00:15:50.670
To handle this data growth effectively, sharding quotes with Rails multi-DB allows us to define tables stored in separate databases. This distinguishes responsibilities, allowing the primary database to prioritize user access, logins, and profiles while still delivering functionality for users’ quotes and characters.
00:16:38.610
Through this method, we can enhance performance as characters flow more seamlessly across the application. However, we’ve observed that Rails can become sluggish due to logic within the app leading to repetitious database loops. Jumping between multiple databases can cause significant network latency, contributing to performance issues.
00:17:22.860
Query caching becomes less effective as queries might be directed to the same table multiple times, causing systematic slowdowns. Focusing on the 95th and 99th percentile queries can shed light on the problems causing bottlenecks, often because just one or two queries can halt database activity.
00:18:10.560
Network latency is a challenging problem that isn't directly addressed by the CAP theorem; however, related considerations can surface in various architectures. When partitions experience failures, developers must choose between availability or consistency. In situations without critical partition failures, the challenge often tilts toward latency versus consistency.
00:18:59.310
The result is that as we scale, our concerns shift to the network layer rather than the database itself. To optimize response times, we must address how to minimize network hops during queries, especially when we have significant data to manage.
00:19:46.130
Connection pools are important to manage, as are the configurations set for app and database servers. Mismanagement allows Rails to oversubscribe connections, which means recognizing when individual databases are reaching limits is crucial. Whether they are specific to certain servers or shared across multiple databases can often affect overall performance.
00:20:24.610
We also need to assess how caches are performing across databases. This varies between writable databases and read replicas. Often, performance issues manifest more prominently in read replicas where caching mechanisms are less responsive, which means identifying which replica is causing bottlenecks is critical.
00:21:32.580
As data sizes expand, the relationship between your caches and overall database size becomes vital. Avoiding excessive disk swapping by managing how Postgres serves memory requests must always be a priority. Excess swapping indicates a performance drop-off; optimizing how you manage reads and write operations efficiently is essential.
00:22:09.510
Examining your application server's health—such as memory, CPU usage, and connection limits—can give insights into potential points of failure. When CPU usage soars due to waiting on disk throughput, your database may struggle to respond in real time.
00:23:15.450
Additionally, establishing safety measures in your apps, like feature flagging or circuit breakers, helps minimize downtime during unexpected critical situations. You should maintain awareness of overall resource thresholds to ensure safe operations, particularly during traffic spikes.
00:24:08.320
The importance of continuously evaluating new strategies cannot be overstated. The nature of user behavior is ever-changing, and so should your data strategies. Implementing principle-of-least-privilege architectures can further optimize performance.
00:24:59.280
Refactoring monolithic applications to eliminate god classes and overly complex designs will enhance maintainability. Understanding real-time applications versus those that can afford some delays is crucial for scaling performance. Ensuring relational constraints aren't bottlenecks for your performance can also enable smoother growth.
00:25:48.560
At this point in the talk, let's delve into what Heroku offers today, including the latest features in Postgres 11. We've announced its general availability, encompassing various enhancements such as stored procedures, advanced parallelization, and improved optimization features.
00:26:53.860
Additionally, we provide curated analytics tools to help you query insights about your performance metrics and slow queries. We expose this information in logs and detailed reports to assist optimization efforts through tools like PG Bouncer.
00:27:42.860
PG Bouncer is in beta, and while it supports transactional connection pooling, note that session pooling can introduce complexity, particularly with the management of exceptional queries. This approach is especially beneficial for asynchronous workloads, particularly in systems requiring heavy queue processing.
00:28:25.440
For further protection against potential operational failures, we also track queries and resource usage through Heroku's graphical insights, enabling organizations to optimize performance proactively.
00:28:51.020
Now I would like to open the floor for Q&A.
00:29:21.960
If you partition your table, querying from the default table may not require engagement with specific queries unless you're optimizing for historical records. Rails allows raw SQL for queries on different partitions if nuanced adjustments are necessary.
00:30:37.670
As for programmatic joins and relations, you'd manage those manually in your Rails layer, as migrating relational logic between databases means Rails doesn't inherently know how to manage those connections. Thus, additional stress on the Rails layer requires thoughtful handling of data.
00:31:34.600
In terms of performance testing, assessing the complexity of your Rails code is necessary and should be mirrored closely to the production environment. Various tools, like New Relic or log aggregators, can assist in discerning varying performance metrics more accurately.
00:32:08.010
Overall, Rails performs connection management but does not handle those sophisticated strategies inherently; it is your engineering team that needs to implement optimizations across the board. Thank you all for attending!
00:34:30.669
[End of Talk]