00:00:21.080
Okay, good afternoon everybody. My name is Nate Berkopec, and this presentation will be an introduction to benchmarking and profiling in the Ruby language.
00:00:26.430
If you're not familiar with me or my work, I am a Ruby on Rails performance consultant. I've been doing that for the last four years or so. I wrote a book called "The Complete Guide to Rails Performance," and I help companies, large and small, make their Ruby web applications faster.
00:00:38.430
I'm also doing a nationwide workshop tour this summer, so if you like what you see today, you can get the full version at one of my workshops. This summer, the workshop is focused on measurement and diagnosis of performance problems, which is what we're going to get into just a little bit today.
00:00:50.550
As you'll see, can I get my timer? As you'll see, there is one workshop two days from now, on Friday, here at the Hyatt Regency. I have just a few more tickets available for that one, so please talk to me if you're interested in staying an extra day and attending that workshop.
00:01:02.370
Okay, so today, my objective is to give you enough of a roadmap on the topics of benchmarking and profiling for you to go home, open up your Rails application, and have a good idea of where to start and what to Google for when you get stuck. I can't cover the complete basics of benchmarking and profiling, particularly the specifics of how to use each individual tool.
00:01:26.069
I think you're all smart enough and good enough programmers to go home and read the documentation to get the exact specifics of how to use each specific tool. But today, we're going to cover at least what tools exist, what they're good for, and what they can tell you about your application. And although this is RailsConf, nothing I'm going to present here is specific to Rails.
00:01:52.200
I want to begin with a story about one of the most famous computing projects of all time: the Apollo Guidance Computer, and how a performance bug almost caused an abort of the very first moon landing. The AGC is famous for having extremely low computing resources—one processor running at one megahertz, thirty-six kilobytes of memory, and two kilobytes of RAM. However, it was one of the first computers that implemented a concurrency architecture that was not based on time slicing.
00:02:22.290
Time slicing is a technique where you divide a second into smaller increments or slices and then allocate time evenly between those slices, but that wasn't going to work for a real-time application like the moon landing. Previous design was created by Harlan, a software engineer at MIT, who devised a new method called the executive. It was one of the first ever implementations of cooperative concurrency, and its design became extremely important during the landing of Apollo 11.
00:02:54.959
As dramatized in the movie 'First Man,' pay attention here to the error codes that the astronauts call out during the landing.
00:04:16.090
So two astronauts are hurtling down towards the surface of the Moon, and they get an error code that they've never seen before—five times in two minutes.
00:04:21.290
During the final descent of Apollo 11, a software error occurred, and five times the Apollo Guidance Computer had to be soft restarted. These errors were of the 1201 and 1202 error code classes. When Neil Armstrong radioed down to Houston and asked what to do, Mission Control radioed back that it was a go.
00:04:37.970
What doesn't show up in this transcript is that a 24-year-old computer programmer named Jack Garman at the back of Mission Control told the guidance controller that the error code was a go and that it was fine—as long as it didn't occur continuously. So there was only one person at the back of Mission Control that knew, 'No, it's fine, don't abort the moon landing.'
00:05:03.800
Although they didn't have time to check it, flight director Gene Kranz had a sheet of paper taped to his desk that listed the various alarm codes that the AGC might raise during the descent. Among these was the 1201 and 1202 codes. That sheet said that these error codes indicated an overflow of the available memory for active work, which could cause an automatic soft reset of the AGC.
00:05:20.150
The 1201 and 1202 error codes noted that the duty cycle might be up to the point of missing some functions. Essentially, the AGC was being overloaded. The bailout routine, which is the subroutine that was called automatically after these 1201 and 1202 error codes were raised, is called when the AGC runs out of course sets. The AGC had eight of these corsets, which were areas that could store a small amount of data related to a single job or task.
00:05:53.900
So, in effect, the AGC had a job queue that was eight jobs deep. If the AGC became overloaded and had too much work to do, the number of corsets in use would keep increasing until a bailout was called, leading to a reset of the AGC, clearing the corsets.
00:06:22.270
The 1201 and 1202 errors were raised when the AGC was running on program 63, which was the guidance mode used to slow down the lunar module during descent. It was the most taxing period of the entire Apollo mission on the AGC's minimal hardware. This is a graph of a simulation of the Apollo Guidance Computer's utilization during descent.
00:06:58.480
So, the top line here represents CPU utilization—back then, the agency engineers called that the duty cycle. During the final phase of the descent, the AGC was expected to see 90% of its available CPU cycles used. The fact that the 1202 and 1201 errors were being raised meant that the duty cycle had exceeded 100% during the lunar descent.
00:07:31.600
The astronauts were on a hair trigger to abort the mission in case of a safety issue. The astronauts, specifically the LM pilot Buzz Aldrin, had lobbied the engineers that during the descent the rendezvous radar would be turned on to track the command module, which was orbiting above them.
00:08:04.510
During the descent, they needed to know where the command module was in case they had to abort, so keeping the rendezvous radar on would increase the chances of a successful abort should it be needed.
00:08:51.310
However, there was a bug in the rendezvous radar. As the lunar module tilted forward, the radar pointed out into space rather than at the command module. This change in angle, combined with an extremely obscure bug in the power supply to the rendezvous radar, caused an overload of tasks and data sent to the AGC.
00:09:19.630
Later analysis would show that the rendezvous radar was consuming 13 percent of the available duty cycle with spurious jobs, which was three percent more than they had available. Now, I’m sure everyone here has never had a super wacky bug take down their application in production.
00:09:57.940
The story of the 1202 program alarm reminds us that no amount of performance work outside of the production context will catch every single performance bug. One disadvantage of the Apollo landing's executive design was that it was non-deterministic. While the Apollo engineers ran many simulations, they could never perfectly replicate the conditions of the moon landing.
00:10:47.490
One of the main objections I get when I teach people about benchmarking and profiling is that they don't like that the performance bug has to happen first in production before we can replicate it on their machines in development. They’d rather perform load testing and try to find these issues before they occur. But as the Apollo story shows us, load testing is not reality. Simulation is not reality. Only reality is reality.
00:11:39.500
Another thing I hear a lot is that people would rather learn the solutions themselves, wanting me to give them tips, tricks, and that one weird solution that will fix all their Rails performance bugs. This is a list of the 321 optimization passes that the GCC compiler makes on every line of C code. This list was provided by Vladimir Makarov of Red Hat, who is working on a JIT for Ruby.
00:12:38.230
Each of these GCC compiler passes makes very small tweaks—optimizing one thing here, optimizing another there. It does this 321 times, but we are not compilers. I could teach you 320 things to check on every single line of Ruby code, but you wouldn't remember 320, probably not 32, and likely not even three.
00:13:40.930
What I'm trying to convey is that all performance work without measurement is premature. This is what we talk about when we refer to premature optimization. If you haven't measured and proven the problem, working on it is premature. That's why benchmarking and profiling are foundational performance skills.
00:14:21.920
That's where I start everybody when teaching performance work. It also saves time. The number one thing that probably stops people from working on performance is when they start and say, 'Oh, I've sped up this part of the code by 10x,' and they deploy it, only to find that it makes no difference to the application because they weren't paying attention to what was happening in production.
00:15:05.170
The method I’m going to teach you here today is to measure twice and PR once. If I can show you how to measure and replicate in development, it’s going to be far more likely that the work you're going to do in production to improve performance will actually work once deployed.
00:15:55.090
Okay, so let’s do some definitions: A benchmark is a synthetic measurement of the resources or time consumed by a defined procedure. Synthetic is obviously a key word here; benchmarks are usually not intended to replicate an exact production process.
00:16:22.759
Benchmarks are usually more granular than that. We can measure not just time consumed—such as iterations per second or how long it took to do something—but we can also measure the resources consumed in benchmarks.
00:16:47.720
So, we can say, 'Hey, this process allocated this many objects and took up this much memory.' That’s also a benchmark, and it’s over a defined procedure like one line of code or one controller action, and we’ll run that multiple times in our benchmark.
00:17:05.810
Profiles are different. A profile is a step-by-step accounting of the relative consumption of resources by procedures and subroutines. Instead of getting a single number at the end—like iterations per second or memory consumed—we get a lot of numbers, providing a breakdown of time spent in each component.
00:17:34.920
We can get this information at an extremely granular level depending on the tool. The way most profilers work is that they tell you, 'You spent 10% of your time here,' but it’s 10% relative to one execution of the entire operation.
00:18:14.030
So, it won’t say, 'We spent 100 milliseconds of time here,' like you would in a benchmark. It gives you an absolute time number; profile numbers tend to be relative, and we can also profile memory and time.
00:19:04.640
Typically, we think about profiles in terms of subroutines, which means in a Ruby context, methods. We’ll look at how much time you spend in certain methods and modules.
00:19:37.420
The overall process I want to teach you today starts with reading production metrics. If you’re not looking at metrics in production and what actually happens to users, you are optimizing prematurely, working on code that is only called once in a million times.
00:20:20.040
Therefore, making that part of the application ten times faster is probably just a waste of your time.
00:20:48.640
Everyone here should be using tools like New Relic, Skylight, or Scout in production. Those are the tools that provide production metrics to make informed decisions. Once you've gathered insights from those tools, for example, 'Hey, our search action is too slow,' you can run a local profile to determine what part of it is slow.
00:21:29.550
If search takes fifteen hundred milliseconds, you need to identify what part is slow. It's not enough to just know it's slow; you need to know which line is causing the slowness. That's where profiling comes in.
00:21:43.160
Once we identify from the profile which parts of the code are slow, we’ll take those slow parts and create a benchmark for them. If we determine that the actual slow part in our search action is not the search itself, but the rendering of the results, we can create a benchmark that measures how long it takes to render one line of results.
00:22:45.390
Once we have the benchmark, it becomes extremely easy and fast to iterate on the solution since we have an actual number. For instance, if the rendering of results was one thousand iterations per second on the master branch when we started, and after implementing a solution it's two million iterations per second, great! Now we know it’s faster, and we can deploy that change.
00:23:15.660
Profiling answers the question of what is slow. These production profiling tools typically can’t give you that level of detail. Profiling adds overhead—it has to, because you're not simply doing the work; you are both executing the work and analyzing it at the same time.
00:24:13.780
As a result, profiling by necessity will make your application slower. Production profilers like Skylight, New Relic, and Scout typically give you less data so they don't impact your production users. However, in development, we don’t care about that—we can add more overhead for more accurate data.
00:24:54.640
To accurately answer the question of what is slow, we need an accurate profiling environment. An accurate profiling environment looks and works as similarly to production as possible. One of the biggest parts of this is the data.
00:25:35.220
Probably the majority, I would say, of Rails performance problems are related to Active Record, which in turn depends on data. This means that the data in your database needs to resemble the production dataset.
00:26:06.860
When we call user.all, we need to get back the same number of rows as we would in production. You need more than ten records when you call user.all; if not, it won’t accurately reflect what's happening in production.
00:26:44.540
You can either download production dumps and insert them into your development database if you’re comfortable with that. If not, I’ve seen people automate the process of downloading production dumps and then eliminating PII—such as dropping sensitive user tables.
00:27:33.110
Alternatively, you could have a solid database seed file, though this is the most difficult option as it needs to create millions of rows and takes a long time. If you work in an environment where you can't use real data, that's your challenge.
00:28:10.650
Now, the other thing that needs to function the same is the code. These are some settings that can cause development mode to operate differently from production. Some people I have talked to about this personally just edit the production.rb file so the code runs in development.
00:29:48.780
However, you can't check this in, so it’s not a sustainable solution for teams. A better solution is to alter the development.rb file conditionally based on an 'n' profile variable. This way, you can have production-like code behavior in development.
00:30:44.050
Some aspects that affect whether profiles in development look accurate include code reloading and asset precompilation. You'll need to turn off Sprockets and precompile your assets.
00:31:36.790
Additionally, active record migrations must be managed; if left on, you're going to see checks for any updates at the start of every profile. So, turning these features off makes the code behave in a more production-like manner, giving clearer results.
00:32:22.830
There are two modes for measuring time in almost all profilers: CPU time and wall time. CPU time counts time based on CPU cycles, so that means that IO and sleeping do not show up in those profiles because no time has passed relative to how many CPU cycles have occurred.
00:32:58.170
Wall time, on the other hand, is based on the clock on the wall—stopwatch time—so everything counts: waiting on IO, sleeping, etc. If we have a method that sleeps for four seconds, a wall time profiler would say it took four seconds to execute, whereas a CPU time profiler would indicate it took zero seconds.
00:33:29.600
This can be useful when you want to exclude IO, but if you're profiling a database driver, you may want to keep the execution time in the profile.
00:34:30.530
There are two designs for profilers: statistical and tracing profilers. Statistical profilers sample a percentage of the available stack frame, while tracing profilers record every method call and the stack at that time.
00:35:39.630
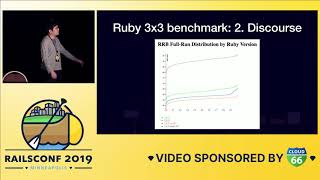
In the Ruby world, we use StackProf for statistical profiling and RubyProf for tracing. Each has its style of output, and I recommend giving both a shot because they are useful for different problems.
00:36:35.510
This is what StackProf's output looks like when you use it with Rack Mini Profiler, which I will discuss more shortly.
00:36:44.890
A flame graph displays the profiling data—each bar represents one stack recording, while horizontal lines are parts of the stack. When analyzing flame graphs, long flat sections indicate functions taking a substantial amount of time to execute.
00:37:38.890
Repeated shapes within the flame graphs signify loops. Therefore, if we can make that loop faster, we can speed up the overall performance.
00:38:56.920
This is what the output of RubyProf looks like when using its call stack visualizer, which is one of my favorite tools to analyze performance. Each line represents one layer of the stack, showing how much time was spent and the percentage of total profiling.
00:39:33.450
The key is to try different formats and profilers for effective analysis as not every profiler is perfect for every problem.
00:39:57.030
We can also profile memory, as Richard discussed in his talk today. Memory profiling is important, and tools like the Memory Profiler gem provide the best fit for this need.
00:40:59.500
Interacting with Memory Profiler and StackProf can be done effectively through Rack Mini Profiler, which adds an easy-to-use interface for profiling.
00:41:33.490
Now, let’s talk about benchmarking. There are three kinds of benchmarks: micro, macro, and app. Each has different levels of scope.
00:42:02.540
A micro benchmark runs just one to a hundred lines of Ruby code and iterates again, which means, it can run millions of times per second, but they can be misleading.
00:42:24.000
A macro benchmark runs anywhere from a thousand to a million iterations and might execute a couple thousand lines of code.
00:42:36.440
An application benchmark is larger and may iterate only a couple hundred times per second, leading to diminished impact from changes to the code.
00:43:17.840
The recommended benchmarking tool I like is Benchmark-IPS, created by Evan Phoenix. It runs your code once as a warm-up and then discards that result to fill up caches.
00:44:21.670
The warm-up phase is crucial, as the first execution of any piece of code will be slower than subsequent runs. Benchmark-IPS runs the benchmarks for about five seconds.
00:45:00.090
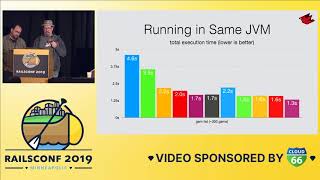
This was an actual benchmark from a gem I used to maintain. The output shows the warm-up phase and the results of the benchmarking.
00:45:57.470
The Benchmark-IPS gem includes object allocation metrics that correlate directly with time consumed. The benchmark can measure both time and resources.
00:46:34.360
The warm-up and benchmark time parameters in Benchmark-IPS typically suffice for 95% of benchmarks. You may need to adjust the warm-up time to maintain stable results.
00:47:07.490
Generally, warming the cache is done when the iteration speed stabilizes. In different Ruby versions or runtimes, you might need longer warm-up times.
00:47:35.900
My number one benchmarking tip is to beware of the loop. Pay careful attention to what's being run in the benchmark loop. If additional overhead is being run, it will obscure the speed differences you want to measure.
00:48:10.890
Be careful of including Active Record calls inside the benchmark loop, as they may increase overhead without providing relevant performance insights.
00:48:54.480
Apps should maintain a benchmarks folder to allow you to track performance changes over time.
00:49:11.590
Even though having a fancy CI setup to run benchmarks is cool, it's equally valuable to just manually run benchmarks from a dedicated folder.
00:49:50.470
When optimizing, you will typically repeat the same parts of code for performance reasons, requiring fewer benchmarks to be effective.
00:50:34.330
To recap the process: Read production metrics, profile the development environment, identify which parts are slow, create benchmarks for those parts, and iterate on those benchmarks and changes.
00:51:24.560
This is a scientific method: observe, create an experiment, run the experiment, and observe again.
00:52:01.120
When working within a large team, they will inquire about the numbers. Making a performance PR to Rails requires demonstrating the performance matrix.
00:52:54.360
Today, I have hopefully convinced you of the importance of measurement, the differences between benchmarking and profiling, the tools available, and an introduction on how to use them.
00:53:39.070
After Apollo 11 landed, a frantic search occurred at Mission Control to determine what caused the program alarms. Luckily, the Apollo was built with a type of production profiler, constantly sending data about its own state.
00:54:45.920
Careful analysis by engineers led to the discovery that the rendezvous radar’s status had been inadvertently altered by the astronauts who modified the radar's position without informing the software team.
00:55:46.890
The lesson is not that we can and should test every production state, but that with limited resources, it’s impossible to identify every potential issue affecting performance.
00:56:59.439
Instead, we must build software that fails gracefully and recreate error conditions in development with the help of profilers and benchmarks, studying and replicating what happened in production.