00:00:15.560
Okay, it's about time to get started. But in the interest of letting some more people shuffle in, this is my very first RubyConf. I sort of went all in, thank you! So if you'll indulge me for a brief aside, I have some time at the end, and we'll take a minute for that. Yesterday, I went to a talk by Jack Danger. Did anyone else go to that one? Yeah, so I went, and he started talking about the pitfalls of the technical interview. My heart sank a little bit because I thought I would have to trash everything I worked months on and just replace it with his ideas.
00:00:33.630
Thankfully, he went much higher level and way beyond what we're going to cover here. His talk was more strategic and high-level, while this is going to be a little more in the weeds, if you will. If you didn’t catch his talk, I recommend checking it out when Confreaks makes it available. I’m not making this up; I met someone right after that whose name is Justice. He’s actually here in the crowd, and he looks like a superhero. I thought to myself, 'I came all the way here from San Diego and ended up at Comic-Con.' Anyway, between Jack's talk and Justice, let's get into it.
00:00:51.840
In addition to meeting Justice and hearing Jack’s talk, some people were kind enough to share anecdotes about challenges they’ve faced with technical interviews—some are solved, while others remain unsolved. I think this is something that everybody faces to some degree. If you’re facing these challenges, like Jeremy in the audience, who is doing this for the very first time next week, see if you can apply some of the concepts we discuss today. We have a good size audience for some participation, which is totally voluntary, but I encourage you to ask questions both when prompted and at the end when there’s time.
00:02:24.780
So, why even bother with a refactor? The fact that you’re here means I think you already see some value in this, but sometimes you aren’t making all the decisions. I find it helpful to enumerate the costs of not paying attention to your hiring and interview processes. If you have a CFO, CEO, or a numbers person saying that you’re not allowed to spend time working on this, you can point to this list. If you’re not making the best hiring decisions, it’s costing everyone time and some amount of money. Resources are spent on-ramping that person and teaching them the workflows.
00:03:14.610
Someone mentioned that opportunity costs are an important part of it—opportunity costs of potentially training someone else who could be a better fit. Also, reputation is at stake. It’s not a good situation for anyone if you make a hire that’s not the right fit; it’s a poor experience for the new hire, for you, and it can hurt morale around your team. It can also increase technical debt. These are real issues that can be tricky to quantify but are not impossible. Therefore, if you can answer the question of how much is it costing you, it will be easier to justify spending time and resources to make it better.
00:04:03.800
Is there any questions on this piece? Good. So it’s important, but is there anything wrong? Again, I think everybody has an idea that there’s some opportunity for improvement here. I’m going to walk through a couple of things. This is part of the Joel Test: I actually like this 12-part test where candidates write new code during their interview. I think this is an important part of the technical evaluation of someone.
00:04:31.020
The issue is the kinds of questions that we ask. Has anyone been involved in an interview that asked at least one of these questions recently? Yeah, most of the room. Any other examples of questions someone faced recently? Jack mentioned balancing a binary tree, and I think I would probably struggle with that one, as I've never used it in my entire career of coding. But in an interview, you might need it. So does anybody understand or think that these are good questions to ask that you can learn something from?
00:05:01.680
Well, yes, you can definitely make some evaluations based on those things. We’re going to revisit these in a minute; first, we’re going to walk through an analogy. I really like analogies and tangible things, so bear with me for a couple of slides; this will relate. Let's say you ask any question in a carpentry interview, like how do you build a drill? Imagine asking a carpenter that. Or, consider this: you have a structure where every third plank is birch and the fifth is maple. What’s a carpenter likely to say? Probably something along the lines of, 'Why are you asking me that?'
00:05:49.810
The issues with these questions are that they have been solved a long time ago. People figured out how to mass manufacture drills, quality control, and all of that stuff is standardized. You can find a drill easily at any hardware store. It’s trivial; no one cares if you can figure out the number of pieces of maple in such a scenario unless you’re doing something very specific. So relating this to software development, we have similar quick questions like sorting algorithms—QuickSort from 1959, Mergesort from earlier, and Radix sort from 1887. If you want to have a little fun in your next interview, they might ask you to implement a sorting algorithm, and if you get to choose, do Radix sort.
00:06:38.069
Now, just tell them that you really care about backward compatibility. In addition, these sorting algorithms, min/max, and those kinds of things are standardized. If you can find me a language that doesn’t have these, I would have to ask why you're using that language. There are hundreds of publications, blog posts, books, and online tutorials that prepare you not for a job, but for an interview; and trivial ones like FizzBuzz or BubbleSort are interesting. There’s an academic paper that suggests BubbleSort should be entirely removed from the computer science curriculum because it’s remembered on the same footing as other sorts but its time complexity is bad.
00:07:34.310
So if you’re asking someone to implement BubbleSort, something is wrong. Now, why do we ask these questions? I touched on this a little bit, so let’s revisit it again. Some people raised their hands before and said they might be able to figure out where someone lies in their technical abilities. Any other ideas on what makes these standard questions helpful?
00:08:10.289
Yes, it’s a good initial gate, potentially. Here are my thoughts: those kinds of questions are optimal for evaluating algorithm writers and procedure implementers. Once upon a time, I think everyone in this field had to be highly skilled at this—it was just part of the job. But some things weren’t figured out, and some things weren’t standardized; and I think that was a long time ago; those skills aren’t optimal for these kinds of developers. If you can implement BubbleSort, that doesn’t necessarily tell me how you might design a system or create objects in an object-oriented language.
00:09:49.370
In other words, the skills related to algorithm implementation are valuable, but the skills related to designing systems are more valuable. So, you should optimize for those over algorithm writing. If you already have some questions that you use for your interview, I have a two-question litmus test to see if it could use a refactor. One: would you be happy or very upset and confused if someone did this on the job? If someone told you, 'Oh, I spent last week implementing FizzBuzz instead of whatever feature you wanted me to do,' you’d probably be pretty upset about that.
00:10:47.420
So don’t ask them to do it in the interview. The next question: which book would better prepare someone for your interview—this one, or this one? Of course, these aren't the exact books, but whatever the de facto standard is for interview prep at the time in your language. And since we're Rubyists, the 'PickAxe' is a pretty good one, but if you’re in a different field, I’m sure there’s a standard for learning coding styles and best practices.
00:11:38.230
So, if you answered yes to either of those questions, consider a slightly different approach. Algorithm writing is still important; that’s not totally absent in our field. Maybe you’re not sure what the right balance is, or you might need someone who has both sets of skills mentioned earlier. In general, what is the point of an interview? What’s the basic thing you’re trying to figure out?
00:12:09.560
Yeah, that’s definitely part of it. More generally, it’s to see whether someone can do the job. Being part of the team and being an effective member is definitely a piece of that. So if we want to see if someone can do the job, we should line up the job expectations with the interview expectations. This is my list; I think it’s broadly applicable, but you might have your own. It’s very short: I expect someone to be able to read code. This is mostly about the technical aspect of the job. Communication and soft skills are also important, but my focus here is on the technical interview.
00:13:20.940
Reading code, understanding it, and making it better are the things I care about in a developer. You might have a different list, but what this means is that when I set up my interview questions, I have certain expectations. I want someone to read code; I want them to explain it. If you understand what it means, I also need them to explain it, which introduces a communication aspect as well. And then, of course, they should make it better. Does anybody notice any words, verbs, or terms that are absent here?
00:14:11.520
‘Fast’ is not here, either. Right, that was the answer I was looking for; we’ll come back to that. So what about writing new code? The Joel Test said that people have to write code during the interview. Joel also stated this fact very plainly; it’s a fundamental law of programming.
00:14:47.170
Sandi Metz and Robert C. Martin quantified it well over ten to one. Okay, now, implicit in making code better, you’re going to at least be editing; you might be authoring new things. But reading, if you believe those experts, constitutes 90% of the technical work and more difficult writing, which is 10% of the technical work and easier. I contend that if you want to follow the 80/20 rule or the 90/10 rule, you should care more about reading and explaining than about authoring something new, especially if the authoring is something trivial. Even if someone does write new code on the job, they’re often referencing examples or using generators—different types of things.
00:15:38.130
How many times do you start with a blank slate and just type? Maybe never. Cool, now we have a new problem: what code should they read? Does anybody have any ideas here? It’s your code. Your code—I mean this in the plural possessive, somewhat abstract way. It doesn’t mean your actual code necessarily. It might be something that someone wrote five years ago before your company. Ideally, it should be the closest to what you think the person will be working on.
00:16:27.300
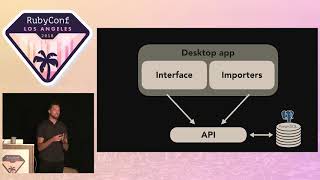
I’m going to give you a couple strategies later on how to curate this, and if you’re in a situation where your code is confidential with too many NDAs and all that, you do have another option—we’ll talk about that later. But I would bias towards production code; that’s the main point here.
00:17:35.080
Okay, let’s try it. I’ve got a couple of examples here. The first one is the very bit of code that I ever used when experimenting— it is somewhat simple; it’s not very much code. It’s not a good example of writing software by any stretch; it was real production code at a former company. I still use it because it shows how many opportunities there are for insight with this kind of approach.
00:18:34.320
The other example is more recent; we’ll get to that in a minute. Cool. Step one: read code. Can everybody see this? Good. I’m going to give you just maybe 30 seconds to digest this before we jump in. If it’s not obvious, this is the Active Record that Rails uses. We have a couple of those, obviously, in the production codebase; these are in their own files and have been distilled down and packaged together for an interview situation so they don’t have to dig around through files—it's close to a whiteboard scenario.
00:19:54.090
So, the first question is: what is this code even doing? Let me be more specific here. It’s the sort by bit that I care most about—what is happening with that? The other stuff is more for context. Does anybody have any guesses? Yes, it’s sorting based on the position attribute and then by the group. Is there anything else important going on here about the sort order that we need to consider? Yes, there’s the ternary, which is basically saying if the package group is not present, put a zero there and that will sort to the top if you do not have a package group for a particular item.
00:20:48.020
It’s a good point about string concatenation; you’ve got high and low order digits where you might have ten and ten versus a hundred and one. There are some bugs in this code for sure; that's an excellent point. If you have a candidate struggling, you can ask some directed questions, 'Is there any difference between order and sort by?' Yes, exactly! One happens in the database while the other happens in Ruby memory.
00:21:53.120
There are trade-offs there. You might ask, 'Should we swap one out? Is there anything we can do to make them both order?' What are the side effects of that? Some questions like that. Why the ternary? Why the two? Any thoughts on that? We need concatenation, not addition. So we have to change it to a string at the top. It depends on whether it’s a stable sort; it’s an excellent question: if the packages are already in order, will they remain in order during the sort? That’s a good question; I actually don’t know the answer that off the top of my head, but I would want to hear those kinds of trade-offs. And the two? I’m not even sure that’s necessary; it might be, but I don’t think so. Ruby can sort strings pretty easily.
00:23:22.280
So, let’s review. While someone is explaining code, you may learn how they translate code into human understanding. I think this is kind of the crux of what we do; even if you’re a rockstar developer, if you don’t understand the human problems you’re solving, it doesn’t matter how good your code is, right? Vice versa, if you’re very good at understanding human problems but you can’t code, you won’t be able to tell the computer what needs to happen. So I think you get a sense of that when they translate from computer code to human understanding.
00:24:51.220
Order and sort by give you some insight into the depth of knowledge. What tools are at disposal here? Enumerable, Active Record—what are the implications of using one versus the other? Do they consider trade-offs? If you do it all in an order by clause, it’s faster, but you might break something unexpectedly. Why the ternary? Why the two? We kind of hit this on the head with how does the language treat operations, both sorting operations and the addition operator.
00:26:36.600
Now, imagine if you take a minute to step away and give them an opportunity to make it better. You can review what you discussed and give them time so they don’t feel pressured. If you want to be available to answer questions, that part is kind of up to you. But pretend you gave someone twenty minutes to make it better, and when you come back, we’re going to run through a few of these. Has this improved, in anyone's opinion? Show of hands if you think this is any better? A few people. Is it more readable? I think so.
00:27:32.080
But maybe not; I don’t think it does anything to the runtime. It's more or less equivalent. So it’s a cautionary refactor aimed at improving readability. Okay, how about this? Any improvements here? Is this a naive solution? Are we missing something? Yes, should use a batch processing approach, like a find_each. That’s a great point. Yes, now we’ve broken things! This eliminates packages that don’t have a package group. That’s not necessarily a dealbreaker, but it’s something that you want to discuss.
00:28:58.830
And one we review, we’ll talk more about that. Is this an improvement? Does anybody love SQL? I love SQL! I think this is great; it’s fantastic. Bringing it back to Jack's talk, one thing is if you’re looking for someone where your knowledge isn’t duplicated and no one on your team is, this might be the most interesting solution for you because now you’ve got a piece of the puzzle your team is missing. Same for some of the other solutions.
00:29:58.820
Is anyone here a SQL person? A few? Are there any issues with this solution? If you are a SQL person, the answer is easy—there's a trivia question here. Yes, NULL is specific; it’s not part of the SQL standard. ISNULL is equivalent for MS SQL, and NVL for Oracle. Coalesce is actually the SQL standard, so this will not work. You’re no longer database agnostic. If you have a database person, they should point that out.
00:30:53.510
Is this an improvement? Maybe this is very Active Record-like. I believe it is correct; it requires knowledge that you can merge other relations to allow for more complex joins and ordering. Have we introduced anything here? Again, this one should be a little more obvious—it doesn’t take a lot of thought. If you’re thinking too hard, don’t think so hard. We lost an instance variable name; we don’t have packages anymore. Well, maybe a view breaks now. We gave more descriptive names, but we forgot about backward compatibility.
00:31:47.230
A quick recap—you want to know if they ask good questions, any mention of writing tests. Do tests exist? Should I write tests? What would they cover? We talked about how we introduced some bugs or eliminated packages that we should have preserved. Now, I'm not expecting them to write many tests or RSpec on the spot; that's a little too time-consuming. As long as the mindset is there, I’m happy with it. If you’re more about TDD, maybe you don’t even care about their solution—you just want to see the tests they write around the code.
00:32:37.700
What about the database? What if there’s a foreign key constraint? All that’s for naught! Again, if you don’t have a database person, then asking those types of questions might be a good complement to your team.
00:33:18.400
How about commit messages or reasons behind the initial code? This is the one that I care about the most; all the other stuff is technical details. This is weird code; this was a weird bit of code. Maybe somebody was under the gun to get it done, but you don’t write code like that by accident. You’re hacking at it until it works. Is there a good commit message? It says, 'Yeah, I know this is ugly, but this happened, and this is the only way to solve it. We’ll revisit it later.' Maybe there’s not a good test, but there is a message that communicates what you need; that, to me, is what I care about most.
00:34:23.080
Oh, I forgot to introduce this. So does this approach scale? What if you’re interviewing a junior versus a senior or staff? Does this single question scale to those different roles? I would say it does to some level. If you're asking a junior, you might have more prompts or different expectations about the trade-offs they mention, and implications of different things. For a more senior candidate, you might expect unprompted answers; you might expect them to talk about database compatibility and all of those things.
00:35:09.750
So your expectation of the answer and how much you guide can scale up or down, maybe not infinitely, but to a degree for sure. The next topic we’re going to discuss is more recent. We have someone that’s going into a technical interview next week, and this example is hot off the press. There’s an open PR in our repo for this right now; I pulled this last night so you don’t need a lot of time to prep these types of questions.
00:36:02.740
My coworker David, who’s familiar with this pull request, did some work on it, and I included the line numbers on purpose. This code looks familiar to anyone who’s used Rails recently, at least some of it. There’s not a ton of context for the definition; it requires MFA, so I’m not worried about implementation details. But what are some concerns with this code when you think about object-oriented principles?
00:36:29.920
What are some concerns? Yes, there are too many dots in the method calls; you may end up with nil errors, which means you’re asking for trouble if you have five dots in a row. There are a few code smells here; we duplicate that call twice to Rails Config, both on the very next line. What thoughts can you share on how we can make this better?
00:37:10.920
Again, without full context, how can you apply some principles to make this better? A new object might get rid of some of the dots, right? Great idea! That’s what we can do—implement a new object. This approximation shows what we came up with. There are some concerns, though, for security reasons regarding environment variable names and other things, so I’ve redacted the private methods.
00:37:55.660
Now, imagine that we didn’t have this solution in place but instead knew we were basically changing this user to require MFA as a new feature, thus revisiting this code. You’d get a couple of benefits: one, you get some free labor, and the other is you won’t have expectations about what the answer is. Some concerns may make you afraid you’d be leading or projecting the answer.
00:39:11.500
What if you don’t know the answer? That places you in an interesting spot; it can be a little nerve-wracking. I think it’s valuable to give them the freedom to drive the answer.
00:39:54.520
So how do you curate these? The easiest way for me is if you're doing a bug fix: save a before-and-after snippet. If you'd rather, use your Git diff between two hashes—that’s a good tool. If you need to go back in time, of course, search your commit history. If you do things like put tags or references to ticket numbers, look through your commit messages for those. Look at what's changed before and after. Pull a ticket from your current sprint. If none of that works, run a churn versus complexity report.
00:40:52.660
There’s a great tool called RubyCritic for this. Independently of the interview process, I highly recommend RubyCritic, and we’ll explore that in just a moment. So for your commit history, look for interesting bugs, or new features that required some design trade-off decisions. It’s like getting a second opinion; that can be a fun way to approach it.
00:41:37.680
What if my code is confidential? This is a big barrier because then you have to get NDAs involved and maybe lawyers, which is no fun. Any ideas before I go into this? You can anonymize your own code, sure. What about using open-source? If you’re in Ruby land and using zero gems, again, that’s not a good situation.
00:42:27.800
If you can’t use your own code, at least get close to the code that they will be using on the job. If you heavily leverage gems, maybe monkey patch some; extend them—dig into that source code, open it up, have them look at it. I don’t have any examples of this yet since I haven’t had to do it, but it’s certainly an option, and the opportunities are out there.
00:43:24.040
What if you need a skill but no one on your team is qualified to evaluate that skill? That’s a chicken-and-egg problem. Pull one of these scenarios out, give it to them, and say, 'As a Rubist, we need someone who knows C, Java, whatever. Explain this to me in a way that I can understand.' There’s a saying: you don’t truly understand something until you can explain it to someone else. If they can explain it to you, then they probably understand it well, and I think that’s the best you’re going to get in the absence of having expertise yourself ahead of time.