00:00:25.640
Hello everyone, I'm going to talk about a concept I'm calling Schemaless SQL. My name is Will Leinweber and you probably know me best for creating the gem install bundler, which if you misspell Bundler and type bundle instead, it will download the gem for you. About 120,000 people have made that mistake. I got tired of making that mistake myself, so I fixed it.
00:00:37.440
I'm currently part of the Heroku Postgres team, and we run a significant number of Postgres databases. Before diving into the main concepts, I want to provide some background on my experience.
00:00:48.840
I unfortunately started out using PHP with MySQL, which limited my application's capabilities. However, after a while, I discovered Rails, and the introduction of Active Record changed everything for me. It was mind-blowing to talk about my application's data in terms of relationships instead of just focusing on the queries.
00:01:05.600
Later on, I found CouchDB, and I really liked it because CouchDB is a database that operates over HTTP. It allows for easy caching and load balancing. It has a RESTful API, which some people argue isn't perfect, but I enjoyed the features it offered, such as multi-master replication and querying with map-reduce views. However, the most significant feature for me was its schemaless nature, where all documents are represented as JSON.
00:01:17.360
It's easy to see why developers love document-based databases like MongoDB for the same reasons. Working with documents is fun and straightforward, whereas SQL can be quite cumbersome. Tables and migrations can become painful, especially with larger datasets.
00:01:35.040
Migrations can take a long time, and they often go wrong, leading to teams avoiding them, which ultimately delays the problem. The normalized form of a database can be a headache. Often, the data for a web application isn't fully relational, which leads to an impedance mismatch between how data is stored and how it's used in code.
00:01:54.400
As an example, I founded a startup focused on versioning songs. Each song had various attributes like title, artist, and an array of versions, where each version had its own lyrics and metadata. While I could have modeled this using SQL, it was difficult to create an appropriate schema, so I turned to documents.
00:02:10.040
Now, with Postgres, although it doesn't natively support documents as a general concept, there are many reasons to choose it. It provides multiversion concurrency control for excellent concurrency support, built-in full-text search, geolocation support, and the ability to treat areas and polygons as first-class entities.
00:02:27.360
The latest version of Postgres even incorporates K-nearest neighbors functionality, allowing users to query for the closest items using an index. This is remarkable, particularly since the literature regarding this technique is relatively new. The ability to use Listen/Notify for real-time notifications is another compelling feature. I use a tool called Qclassic that leverages Listen/Notify for jobs.
00:02:45.120
Postgres excels in various areas like replication, and the open-source tool Wall-E provides efficient backups. Wall-E captures consistent snapshots of the database, allowing fast restoration after a disaster.
00:03:02.960
One significant feature I miss from CouchDB and other document databases is the ability to roll back transactions easily. With Postgres, I can start a transaction, experiment with data, and roll back if needed, making it convenient when testing migrations.
00:03:19.760
I don’t miss the documents themselves anymore because I found ways to integrate document database features into Postgres using two key features: Hstore and PLV8. First, let's discuss Hstore. It's a key-value datatype that can be stored in a single column.
00:03:40.000
The beauty of Hstore is that you can index key-value pairs, enabling efficient querying. Many applications utilize serialized data columns that are often hard to query, but with Hstore, you can perform structured queries.
00:03:54.760
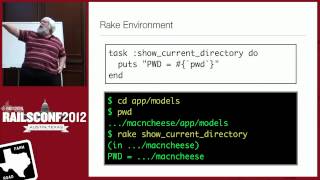
So, let's look at how Hstore works: you can use the double colon operator for casting data types, and the arrow operator is used to fetch specific keys from an Hstore.
00:04:10.000
For instance, if I want to fetch a key from an Hstore, I can query it directly. SQL can be confusing, particularly with operators like concatenation. For example, using the concatenation operator will overwrite existing keys, and you can also subtract keys from an Hstore.
00:04:30.120
Now, imagine having a products table with an attributes column defined as Hstore. You could select products with specific attributes like color, easily updating or querying based on those attributes.
00:04:52.720
Creating an index on Hstore keys enhances performance. You can easily create this index in Postgres, and Active Record 4 provides built-in support for working with Hstore.
00:05:10.680
For example, using the Gen index makes querying easier. My colleague put up a demo on Heroku, which demonstrates how Hstore works behind the scenes.
00:05:30.160
One of the exciting aspects of Active Record is its integration with SQL libraries. For example, we use SQL effectively at various internal Heroku projects.
00:05:45.560
In our work, monitoring the health of our many PostgreSQL databases has become a routine. Every 15 to 30 seconds, new metrics are gathered, allowing us to refine our insights over time.
00:06:02.960
We utilize an Hstore format for observations, which allows us to adapt our queries without needing to run migrations, thus maintaining flexibility. Additionally, we use tools like WickleD to parse log formats into Hstore.
00:06:19.840
I've implemented a bulk bag approach in my database design, where a final column types as Hstore. This allows for agile and adaptable schema changes as we explore new features.
00:06:37.920
Hstore is powerful, but it has limitations, such as not allowing nested Hstores. The keys and values must be strings, so we have naming conventions to work around this.
00:06:55.120
Nonetheless, you can utilize Hstore features today. The more cutting-edge addition is PLV8, which enables the V8 JavaScript engine to run inside Postgres.
00:07:09.440
With PLV8, you can harness JavaScript's capabilities within your database, opening up numerous possibilities for data manipulation and processing.
00:07:29.920
While PL languages have existed for a while, PLV8 provides a trustworthy way to execute code within Postgres without causing crashes, as JavaScript is designed for embedding.
00:07:48.080
The V8 engine compiles and runs JavaScript efficiently, making it an exciting feature for developers. Setting up PLV8 is relatively easy through Postgres tools.
00:08:06.480
One of the most simplistic yet effective examples is implementing a Fibonacci function in PLV8, which is significantly faster than its PLpgSQL counterpart.
00:08:25.360
Using JavaScript's functionality allows for complex and efficient data handling. I particularly enjoyed leveraging JavaScript for functions like Fibonacci due to the speed boost.
00:08:44.640
Let's say I have a JSON document of people's details, including nested structures. With PLV8, you can create functions to extract values such as age or sibling counts efficiently.
00:09:02.640
While working with JSON is powerful, querying it can be slower than querying traditional columns. Still, the capabilities are effective, especially for more intricate queries.
00:09:20.000
Utilizing Common Table Expressions (CTE) allows for organized and complex queries, enhancing data retrieval. Over time, I realized the potential for performance optimization through indexing.
00:09:39.200
Creating indexes and optimizing queries makes a substantial difference, although initial indexing can be time-consuming. Once established, the database becomes adept at handling combined indices.
00:09:55.440
Future developments for Postgres should include native JSON column types, as this would greatly improve working with JSON data. In the meantime, domains in Postgres can help ensure valid JSON data.
00:10:19.760
For now, you can create functions that validate JSON before insertion, preventing corrupt data from entering your tables.
00:10:39.440
Besides validating JSON, you can embed libraries like Mustache for templating within your Postgres storage.
00:10:59.280
Combining JavaScript libraries within Postgres means you can create dynamic web functionalities, processing templates directly in the database.
00:11:22.160
One of the fascinating projects is JSON Select, which can interact seamlessly with your JSON data structures, enabling rich queries within your JSON documents.
00:11:44.000
JSON Select allows you to perform advanced querying and extraction of information from JSON documents, leveraging the best of both JSON handling and SQL-based structures.
00:12:05.600
We must continue to work on refining our methodology for accessing and manipulating JSON data in Postgres. This includes handling type returns correctly to ensure compatibility across queries.
00:12:53.000
Balancing proper type handling will ultimately lead to a more elegant and functional working environment for all developers handling JSON within Postgres.
00:13:10.000
Integrating JavaScript further develops this symbiotic relationship between applications and databases, allowing advanced manipulation and querying directly where the data resides.
00:13:41.000
This all leads to a future where data manipulation is seamlessly integrated, where formatting and querying coexist harmoniously within database structures. I hope to continue pushing boundaries in this area.
00:14:33.000
We currently have powerful document features that developers love, within a world-class database like Postgres.
00:14:56.000
Interestingly, we haven't had a proper data type and language that suits document manipulation so well. As we move forward, I hope to see further advancements in this space.
00:15:15.000
Don't hesitate to leverage advanced database features; they can dramatically improve how data is processed and accessed.
00:15:35.000
Lastly, I want to announce a new release: Postgres.app. It's a pre-compiled version of Postgres for macOS, making it easier to set up and manage your databases locally.
00:16:00.000
Please provide feedback for Postgres.app; your input is vital as we enhance the tool moving forward.
00:16:10.000
Thank you all for attending my talk today!