00:00:10.820
Thank you.
00:00:25.439
If you are here for Stack Smashing, then you're in the right place. If not, I'd still like you to enjoy the talk. Please see me afterward and I can validate your parking.
00:00:37.800
If you go to the link speakerdeck.com, I've posted the slides online. For folks in the back, if you cannot see the two projection screens well, you can follow along at home. Hopefully, you'll stay for the entire presentation.
00:01:01.199
My name is David Czarnecki. Like most of you, I am on Twitter at @zarneckiD. If topics like Ruby, Rails, video games, pictures of food, snowboarding, and beekeeping are your thing, then follow me! I also have code on GitHub at @czarneck.
00:01:29.220
I work for a company called Agora Games, where we provide middleware for video games such as Guitar Hero, Call of Duty, Brink, Blur, Mortal Kombat, and Saints Row the Third. If you've played a major video game, we have data that may flow through our system.
00:01:47.880
We are also part of Major League Gaming, handling all of their online properties. Today, I will discuss simplifying your infrastructure and share key lessons learned managing over 16 interconnected applications on minimal hardware.
00:02:07.140
This initiative, which I termed "stack smashing," arose from the need to collapse nearly 100 virtual machines down to just two physical boxes. Of course, we have additional utility boxes for services like databases, memcache, and Redis, but mainly, our applications run on these two servers.
00:02:19.379
This goal was a priority on the Whiteboard for our CEO. Coming off a previous project, he asked me to take on initiatives that were not being addressed by anyone else. Managing server infrastructure was not something I had much experience with, but as a full-stack developer, I welcomed the opportunity to gain experience in this area.
00:02:51.360
I originally thought this project would be a one-month tour of duty, but as I learned more about the complexities of infrastructure, it has extended from last September to the present.
00:03:10.080
My key goal was to simplify all aspects of our infrastructure. We had many virtual machines for various applications, which complicated things. I aimed to create a clearer understanding of how these applications interact with each other and how to manage this configuration more efficiently.
00:03:30.660
A vital part of this process was documenting everything to ensure that the entire engineering team was aware of ongoing changes and the technologies being utilized. Here’s a brief overview of the network we're discussing for Major League Gaming.
00:04:03.840
As you can see, we have around 15 applications that are intricately intertwined. I have highlighted the larger applications we’re dealing with, such as Pro Gamer, which handles player profiles and stats; MLG TV for video on demand and user-generated content; and a StarCraft arena site for tournaments. Additionally, we offer a live event experience four to five times a year, allowing attendees to mix and match video streams.
00:04:57.920
We sell memberships and various merchandise on the web. Our single sign-on (SSO) is fundamental, enabling all network applications to identify users across the platform. When it comes to computing needs, we perform some simple calculations: the number of apps multiplied by the capacity we require indicates that a minimum of 30 virtual machines is desirable.
00:05:40.620
This would provide failover support in case one machine goes down. However, demand varies based on specific applications and peak times of the year. Therefore, we often require additional capacity and, consequently, more virtual machines. Currently, we are utilizing Rackspace, hosting applications on VMs with configurations of 1 gigabyte of RAM and 40 gigabytes of disk storage. This should allow for the effective operation of several services and provides the flexibility to scale.
00:06:40.620
Our traffic numbers are significant, amounting to millions of views and page views per month, indicating that our operations are anything but negligible.
00:06:54.000
While this scalability via VMs is advantageous for handling traffic, it also incurs variable costs. Switching to physical servers would offer us fixed costs along with reliable computing resources. However, it’s essential to consider that the more servers you have, the more complex your infrastructure becomes, making it harder to manage and understand.
00:07:20.880
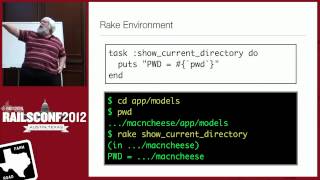
We have established a robust hardware profile for our application servers, featuring processors with six cores, extensive memory, and significant disk capacity. These servers also have hyper-threading enabled, providing a performance boost. We manage our server provisioning using Chef, and I can't stress enough the importance of using automated tools for managing infrastructure.
00:08:25.200
Our Chef recipes are mostly standard, and I will go into detail on where modifications have been made and share some code samples. Alongside provisioning, I want to talk about application migration. We migrated 16 applications from virtual machines to physical servers.
00:09:06.180
The migration process began internally, using the tools of internal departments before moving on to more customer-facing applications. During this process, we encountered many challenges, allowing us to identify potential problems and edge cases. By the time we transitioned the last applications, we had resolved most of the earlier issues.
00:09:45.960
What I've learned from this iterative approach is that repetition helps illuminate patterns and abstractions that can efficiently be applied to your infrastructure.
00:10:23.820
We encourage autonomous decision-making regarding the technologies used across our applications. All applications run on Ruby 1.9.3 and Rails 3. During our infrastructure migration, we also upgraded from Rails 3 to Rails 3.1, which mostly revolves around the asset pipeline.
00:10:48.240
In the upgrade process, you can check out a branch of the Ruby project and set your Rails gem to an updated version. Although the asset pipeline is optional, I recommend enabling it to take full advantage of Rails’ features. The steps include grouping necessary gems in the Gemfile and making adjustments in application.rb to set up the asset pipeline.
00:11:39.780
Also, moving your assets from the public directory to the app/assets directory is a part of the upgrade process. While this was our upgrade path, your specific experience may vary.
00:12:07.680
Additionally, we transitioned from using Thin to Unicorn for our application server, a switch that yielded numerous benefits. Unicorn exhibits impressive performance compared to other servers, as confirmed by benchmarks.
00:12:31.680
One of the significant advantages of Unicorn is its ability to manage worker processes at the kernel level, providing a streamlined way to handle load balancing, while avoiding complexity in our codebase. It also supports rolling restarts, allowing us to maintain zero downtime during deployments.
00:13:06.020
We developed some Capistrano tasks for scaling our application workers according to traffic demand, enabling us to dynamically adjust resources instead of provisioning new VMs or servers.
00:13:39.240
Next, let’s talk about our Rails recipe for Unicorn. We set the Rails environment for specific applications based on their requirements, ensuring that our applications have a robust configuration.
00:14:01.680
In terms of service configuration, we discovered that a server failure can lead to rapid alerts, prompting direct action. A common culprit is identified as the database YAML configuration, particularly if it references a specific machine by name. Imagine facing a primary database crash with several applications relying on that configuration.
00:14:54.120
To mitigate this issue, we implemented DNS aliases for our database services. By using an alias in our database configuration, all the applications will reference the same alias, allowing us to change the target machine seamlessly without redeploying.
00:15:37.620
This DNS-driven approach greatly simplifies our operations. It allows for flexible configurations regarding Redis, Memcache, and any other services we use, thereby minimizing the need for multiple database.yaml updates across numerous applications during server transitions.
00:16:07.259
For offline processing, we utilize Rescue for task management effectively. Our Rails recipe is tailored to support this, allowing configuration of queue management based on our application's demands.
00:16:31.740
We have set different processing intervals for the queues, adjusting them according to workload requirements. Each worker runs as a distinct service within the OS, ensuring independent operation, and they are automatically restarted if they fail.
00:17:03.420
Deployment tasks are handled through Capistrano, and I often get questions about our RVM (Ruby Version Manager) configuration regarding gem isolation. We use gem sets for applications to avoid dependency issues across projects.
00:17:31.920
Capistrano plays a crucial role in deploying our apps. To avoid redundancy across various applications, we package common deployment procedures into a reusable gem, which eliminates repetitive configurations.
00:18:17.640
Our deploy.rb script maintains simplicity while including necessary elements such as error tracking, notifications, and task configurations. The goal is to keep it as homogeneous as possible across 16 applications.
00:19:02.520
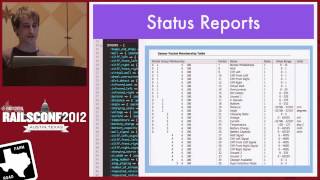
We also monitor our applications, emphasizing the importance of having visual representations of application performance metrics. It is crucial for teams to analyze request rates and server health over time.
00:19:48.000
This visibility allows teams to identify trends and assess application performance under varying loads. Timely detection of slowdowns empowers engineers to troubleshoot before issues escalate.
00:20:26.760
At our company, we use Munin as a monitoring tool. Each server regularly checks into a central Munin server, which facilitated categorizing machines based on running services.
00:21:04.620
Some of our metrics include performance tracking of application deployments, NGINX response rates, and Redis operations. Generally, we maintain historical data comparisons to ensure everything runs smoothly.
00:21:41.580
In addition to monitoring application performance, we’ve implemented behavior-driven development (BDD) practices for our infrastructure. This systematic approach enhances our ability to validate service configurations.
00:22:25.080
Using step definitions, we validate the operational status of machines, running commands on different servers, performing DNS lookups to verify proper aliasing, and ensuring backups are timely.
00:23:09.240
This practice helps us continuously validate that our systems operate as expected, maintaining reliability in services such as MongoDB, Redis, and others across our stack.
00:23:56.160
For continuous integration and deployment, we rely on Jenkins to automatically verify developers’ code. It builds our internal gems, ensuring they remain up to date and functional throughout multiple projects.
00:24:40.680
We also implement GitHub Flow for our development process, making sure that all changes merge seamlessly into the master branch, which is always deployable. This approach involves utilizing pull requests to facilitate code reviews before merging back into the master.
00:25:39.960
Upon successful merging, our post-build script triggers automatic deployments of the applications. Notifications via email or chat help the team stay informed about deployment statuses.
00:26:07.080
To summarize, here are some key takeaways identified throughout this project. Simplify your infrastructure as much as possible. Regularly revisit the roles of your servers, ensuring team familiarity with the infrastructure.
00:27:06.000
When you perform upgrades, maintain awareness of the patterns you discover through repetition. A simple, straightforward comprehension of your services facilitates speedy recovery from failures.
00:27:51.600
Implement DRY (Don't Repeat Yourself) principles in your Codebase, especially while integrating Capistrano. Our organization has consolidated this information into a single gem, allowing for clear, consistent deployment processes across multiple applications.
00:28:24.480
Establish comprehensive monitoring solutions that offer accessible visualizations. Different stakeholders in the company should comprehend performance metrics and engage in discussions around the application's health.
00:29:05.760
Adopt BDD practices for your infrastructure, just as you would for your applications. This structured approach verifies that services run correctly, adding another level of assurance to deployments.
00:29:39.960
Integrate all your systems, ensuring continuous integration processes are standard practice. This will help catch discrepancies between local development and the CI environment.
00:30:56.820
Lastly, I encourage everyone to explore the slides available at speakerdeck.com, featuring both cornflower blue and ruby red themes.
00:31:38.160
Thank you for your attention today and for attending this session.
00:32:41.460
Thank you.