00:00:16.320
Hello, my name is Carl Lerche, and I'm going to be talking about Apache Storm.
00:00:21.920
I am shooting for 40 minutes. It's going to be a long talk; I'm going to try to cram everything in. I've already got a late start. There probably won't be time for questions. I'm also going to gloss over a few things that might seem a bit hand-wavy.
00:00:34.640
If something comes up or if you have a question, just send me a tweet directly, and I will respond to it after the talk, or just come and talk to me afterward. So, I work for Tilde, and our product is Skylight.
00:00:48.480
We're building a smart profiler for your Rails application, and I've actually built the entire backend using Storm. If you want to talk about how that works and how I've ended up using Storm in the real world, I'd be happy to discuss it.
00:00:59.760
So, what is Storm? Let's start with how it describes itself on the website. It calls itself a distributed real-time computation system, and that sounds really fancy.
00:01:13.360
The first time I thought about using it, I was hesitant and thought it was too serious for me. I needed something simpler. It took me another six months to finally take the time to learn it, and as I got to know it, I really came to understand that it can be used for many, many other use cases. I'm going to try to get into the nitty-gritty sooner than later.
00:01:30.320
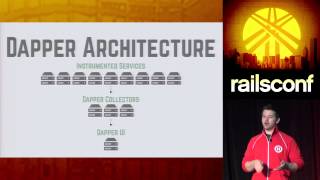
But for now, I'm just going to say Storm is a really powerful worker system. Some things about it: it is distributed, very very distributed, which is both good and bad. The good thing is you can spread your load across many servers. The bad thing is your operations system is going to look something like this, which can turn out to be somewhat of an operational headache.
00:02:03.360
You'll end up running a Zookeeper cluster, having to run the Storm Nimbus process somewhere, and there are going to be a number of other Storm coordination processes. Every server is going to have the worker process, and while you're at it, if you've gone this far, let's throw in a distributed database and some distributed queues. The main point is there is going to be operational overhead, so don't just do it for fun. There needs to be a good reason. If you can get your job done on a single server, go for that.
00:02:38.239
Storm is fault-tolerant, meaning it is able to recover and continue making progress in the event of a failure. Many existing systems claim to do this, but the reality is that handling faults is really hard. This does not make it seamless; the reality is it can't be seamless. However, I think the way it handles faults is about as easy as it can get.
00:03:20.960
It's really fast with very low overhead. Some completely useless benchmark numbers: it's been clocked at processing over a million messages per second on a single server. This number is completely useless, but it sounds good.
00:03:32.560
Storm is supposedly language agnostic, meaning you can use almost any language to build your data processing pipeline. There are examples on the website where they use Bash, but I don't know why—it's probably for novelty. I've personally only used it on the JVM; it's a JVM-based project written in Java and Clojure. It uses many Java libraries.
00:03:51.599
I recommend trying it on the JVM, and the good news is we have JRuby, which has done an extremely good job at integrating with Java. This means you can use Java libraries while writing Ruby. I also want to gloss over the details of getting it running on JRuby, but there is a GitHub project called RedStorm. You could probably just Google 'GitHub RedStorm.' I realized I didn't actually include any links, but I can provide them later. RedStorm does a JRuby binding for Storm and provides Ruby DSLs for everything related to Storm, allowing you to define all your data transformations in terms of Ruby DSL.
00:04:34.400
I'm going to build up a straw man to show how one might implement trending topics on Twitter. We all hopefully know what a trending topic is; it's when everybody tweets and can include hashtags like #RailsConf or anything else. As the rates of specific hashtags increase, the hashtags that occur at the highest rates get bubbled up, indicating the topics that are trending. This helps everyone see what's going on.
00:05:06.240
For example, around here, you might see #RailsConf trending. Another good reason to pick this topic is that it is very time-sensitive and ties into the real-time aspect of Storm. To implement this, I'm going to calculate the rate of how often a tweet is happening using an exponentially weighted moving average, which sounds fancy.
00:05:30.720
As we process the tweets, I want to count the number of occurrences of each hashtag every five seconds. The interval doesn't really matter, but then we're going to average them. Instead of doing a normal average, we'll do a weighted average, which will cause older occurrences to drop in weight exponentially. This is similar to how Linux calculates one-minute, five-minute, and fifteen-minute load averages. It's a nice way to smooth out the curves, and you can tune how you want the curves to look.
00:06:07.440
First, I want to build up some context. Let's look at how one might implement this with Sidekiq, Rescue, or any other simpler system that pops off of a queue with workers. In a Rails app, the process might involve pushing data into Redis, where each worker pops a message from Redis, reads state from the database, processes the message, and writes state back out to the database. The Rails app can then query the result by reading straight from the database.
00:06:38.560
This example isn't perfect, and I know it's naive, but the important part is that we have an entry method that takes in a tweet as an argument. The first step is to extract the hashtags from the body, creating an array of tags. I loop through each tag and check if there is already an existing record in the database. If so, I update the moving average for it and save it back.
00:07:10.560
The way I want to implement the moving average function is to keep track of how often we see certain hashtags. The first thing to do in the updates is to catch any updates, and I didn't pass it now, but in theory, it should update the rate for every bucket we decide we're going to smooth.
00:08:06.560
However, this poses a problem in our worker. If we do not receive any tweets with a specific hashtag, how do we handle that? We need to still update the record to lower the weight of that hashtag because we're not receiving any data. We have to implement a regularly scheduled task, possibly using cron, to run every bucket interval.
00:08:36.240
The first step in that task would be to delete all existing tags that are too old to clear the database and then load up all the tags to update the rates, making sure they are caught up. This points out a challenge: we now have to schedule a task that will read literally every record from the database at every tick.
00:09:06.480
Is it web-scale yet? Well, not yet, but we can start scaling out our workers. Let's spawn up three workers—now we're ready to handle 50,000 tweets per second! Or, maybe not quite yet, but there are more tricks we can employ.
00:09:30.080
As I mentioned, we know that the database will be a significant bottleneck because every single tweet will force us to read state, process it, and write it back. What if we could optimize by caching in memory? We can create a simple in-memory cache of hashtags such that every time we get a tweet that comes in, we check our cache before reading the database. If it’s not there, we create a new record.
00:10:03.760
Then, when the next tweet comes in, we check the cache again instead of querying the database. For instance, when we receive our next tweet, it could be something like 'What's for lunch at #RailsConf?' The worker processes that, increments our cache, and saves it back to the database.
00:10:32.160
While caching in this system is not trivial, there are multiple things we could do, such as pushing our cache externally to something like Memcached. But this comes at the expense of needing an additional process to preserve coordination. The main takeaway, even though we have many workers, is there will always be a high amount of coordination required.
00:11:02.079
Now, enter Storm. As you'd expect, all these problems can magically go away when we use Storm—though I wish it were that simple. First, let's discuss some abstractions. The core abstractions in Storm are streams and tuples. A stream is essentially a series of tubes through which data flows.
00:11:39.840
What they call streams, I think tubes might be a better term. Tuples are just like a list of values and can be anything—messages, strings, integers, any objects you want as long as you can serialize them. You're allowed to specify custom serialization, so as long as it can be serialized into JSON or any other format, it can be a tuple.
00:12:11.200
The rest of Storm consists of a series of primitives used to take these streams and tuples and transform the data from one representation to another. Let's discuss spouts and states: spouts are the sources of the streams.
00:12:39.040
This is how you get data into Storm; it's the starting point of the streams. You could read data from Redis, SQS, or even directly from the Twitter API. States, on the other hand, are how you get the results of the transformations out of Storm.
00:13:07.360
Thus far, we've established that the spout starts the stream and data flows through it to the states. Transformations are purely functional operations on the data—given one input, they will output the same values—so let's add some transformations.
00:13:45.760
For example, we have a spout that sends data, which we might filter and then aggregate. The data flows through to the state to get persisted. After this, we can perform more transformations.
00:14:18.360
The goal here is to model our data in terms of data flow to reach the endpoint. There is no limitation in terms of adding as many spouts as you wish, so long as you don’t end up with a convoluted understanding of the code.
00:14:50.160
Now, let's break down how these components connect together. The spout emits tuples to a filter. Generally, the spouts are standard, so if you are pulling data from Redis, you would use a Redis spout that already exists. Similarly, filters and transforms can often be abstracted into higher-level concepts.
00:15:29.440
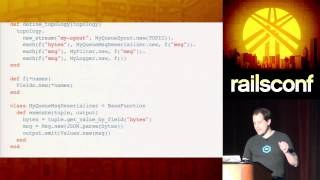
For example, you might implement the filter function or transformation for Storm by extending the base function provided as part of the Storm API. The requirement here is to define a single method that takes the input tuple and produces the output stream of tuples. You get the message out of the tuple and process it.
00:15:54.960
The next step is to define the topology, which connects all the different transforms, spouts, and everything together. The important parts start at the topology object, where you define how data flows together. You typically start by defining the streams by naming them as your spout. For example, with my Queue Spout, you would specify the server details and parameters.
00:17:10.080
The spouts will output tuples as raw bytes, so the next step is to deserialize those raw bytes. Here, you would create a message deserializer, eventually chaining to the filter, which will filter based on predicates, and finally output the transformed tuples.
00:18:09.120
To get started with running this locally, you would simply initialize a new cluster object, define the topology, initialize the config, pass the topology, and submit it to the cluster—all while your local machine runs the entire process.
00:18:58.160
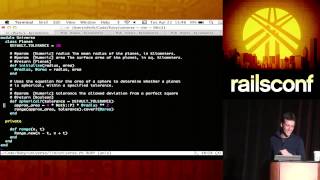
The next step is to persist the results. There are already existing libraries to store tuples entirely in Redis, which require no additional code. But I want to show you how to implement a state from scratch.
00:19:48.000
First, you create a class that inherits from state—this is part of the Storm API. You define the methods 'begin,' 'commit,' and 'commit.' The state updater also needs to define the method that will update the state with input tuples and allow for output tuples in case you need to emit more.
00:20:48.400
To hook this into the topology, you replace the logger with persisting the data to the state. The goal on the implementation side is to ensure you're expecting a tuple that contains the relevant message or data and that you use a basic updater.
00:21:38.640
Now, let's return to the initial Twitter hashtag example. The Storm topology might start with a tweet spout that gets tweets from a specified source. It would pass the tweets to the transform, which extracts hashtags and outputs them as tuples. An aggregating function will track counts and send that information to the state.
00:22:27.760
This is conceptual work where you define an extract function to process tweets, extract hashtags, and emit them as tuples. The aggregator then collects all hashtags and the state computes the moving average of the counts.
00:22:56.160
The aggregate function works similarly to Ruby’s 'inject' on 'Enumerable': it takes an initial state and iterates over the incoming tuples, updating the state and eventually outputting the aggregation as tuples down the stream.
00:23:36.000
Now, when implementing our state, it will inherit from 'state.' That piece will handle moving averages, which takes hashtags and counts for record-keeping. The key here is ensuring that the function allows us to find records by name, update them, and save them accordingly.
00:24:17.440
However, even though streams sound like unbounded sequences of tuples, we do need to determine when calls to certain operations will be made. Storm operates in batches: the coordinator assigns batch IDs for processing to organize workflow.
00:25:02.960
The ability for Storm to re-emit and hit the spout again means we can keep issueing tuples according to the processing batch. In effect, it creates a reliably managed data flow and emphasizes the importance of deterministic functions that do not alter states based on external actions.
00:25:50.640
The transformation functions must be purely functional. That means never using time.now; otherwise, they become non-deterministic. If you need the current time for a batch, it’s often better to have a spout emit the current time separately and capture it. Many spouts don’t engage in this deterministic process, so it’s worth considering that Kafka is an outstanding option for a queue that does maintain these guarantees.
00:26:55.680
Summarizing this all, Storm is a powerful platform for writing workers, especially those that are stateful. It's excellent for complex data processing flows—allowing for scalability and operational efficiency when dealing with high volumes of data.
00:27:45.440
The final challenge is ensuring we can recover from failures. We need to build resilience into our systems because failures will happen; that’s a matter of certainty in distributed systems.
00:28:26.960
When thinking about persistence and data loss, we need to analyze what guarantees are made when processing messages—like whether they're processed at least once or at most once. The best way to handle spikes in errors or fluctuations is to ensure proper bookkeeping while still balancing available resources.
00:29:23.360
Storm’s methodology indicates that each batch will be processed only after the previous one is fully committed, which helps prevent duplicate processing without significant downsides. As I mentioned earlier, returning current transaction IDs allows teams to establish consistency across messages.
00:30:22.720
Through the management of batch IDs and outputs, we can operate in a more predictable environment with fewer inconsistencies. Knowing how to handle failures forces you to build robust systems that can endure pressure in their operations.
00:31:20.240
In conclusion, understanding how to efficiently manage partitions and threads in your Storm processes can lead to a more distributed workload. This scalability, combined with proper error handling, will help ensure the integrity of your event processing.
00:32:06.080
Ultimately, whether you are processing tweets or anything else, the essential part is designing systems that work with concurrency in mind to prevent collapse under load while maintaining reactive responsiveness.
00:32:58.720
Thank you for your attention. I hope this session has helped you understand how to supercharge your workers with Storm and provided some ground to explore further.
00:33:55.520
Thank you all!
00:34:06.600
Thank you!