00:00:21.750
Hello everyone! Hi, or howdy, I guess. I got the hat on.
00:00:27.210
My name is Richard Schneeman, and you are in the talk for "The Life-Changing Magic of Tidying Up Active Record Applications" on the internet. I go by Eames just about everywhere: Eames.com, Eames on Twitter, Eames on GitHub. It's not a really common name.
00:00:34.800
So, some people who know me know that I love Ruby. Some people who really know me know that I am actually married to Ruby.
00:00:41.220
This is my wife. We have two beautiful children, and we also have a couple of dogs.
00:00:47.070
This is one of my dogs. His full name is Hans Peter von Wolf the Fifth. He is actually the fifth Hans Peter von Wolf. My family has had this tradition, and they're not all genetically related, but they all are black and tan wiener dogs.
00:00:57.559
It's a bit of a mouthful, so whenever we are screaming out the door, we don't say that full name. Instead, we just call him Cinco. He likes sleeping with his tongue hanging out.
00:01:03.930
I work for a small startup based out of San Francisco called Heroku, and we have a booth at RailsConf.
00:01:10.259
In fact, we've had a booth at RailsConf for the past seven years since I first joined.
00:01:17.340
Since you like performance, or you probably wouldn't be here, there's a talk given by another engineer, Gabe, on multi-database in Rails.
00:01:24.300
Unfortunately, it was yesterday, so you're going to have to check that out on Confreaks, but I highly recommend it. I got to see a sneak preview, and it was pretty good.
00:01:40.110
You might be wondering what's up with these fancy gloves. I've got fancy gloves not because it's cold here, but because I heard that a lot of companies are really interested in ninja developers.
00:01:46.590
In actuality, I hurt my hands, and you might want to ask how I hurt my hands. I will tell you: extreme programming. Just too agile, y'all, okay?
00:02:04.259
It was actually regular programming, just a lot of it. My physical therapist says it’s going to take a couple of months to heal up. In the meantime, I've actually learned how to completely drive my computer using my voice and my eyes.
00:02:29.450
Here's a semi-old video showing the process; if you're kind of interested, I am a little bit faster now. Each, it works a little better. I’ve got a microphone and all that.
00:03:07.700
So, you might be wondering how I was able to make such amazing slides and such an amazing presentation without actually being able to touch a keyboard, and the answer is: I wasn't.
00:03:30.620
So, yeah, I'm super grateful. I was originally distraught, thinking I'm going to have to cancel my talk, and then Caleb stepped up, and I think the deck is way better than anything I would have come up with.
00:03:43.310
Okay, all right. Who knows who this is? Okay, this is Marie Kondo. She's a world-famous organizing expert. She has books, and we actually got her manga copy of "Tidying Up." It's actually really good.
00:03:56.890
She's a best-selling author and has a Netflix show. I wanted to show you a clip of Marie that she's currently working on for a new show. So, a lot of people don't know this, but she's actually also a programmer.
00:04:22.600
Object allocations! Object allocations! Yeah, tidying up Active Record allocations, I think it's going to be big. A lot of mass appeal. Better than defenders anyway; I mean, come on.
00:04:36.280
Sadly, Marie couldn't be here with us today, but we have the next best thing. I would like to introduce you to her pet rabbit. I don’t think everybody speaks English, rabbits go really fast.
00:04:56.910
I love colors, so I'm not moody. I also not performance. Today you're here to hear about tidying your Ruby applications.
00:05:02.290
That's great! Can you tell us what that method is? Let's take all your object allocations and put them in a pile where you can see them. Next, consider each one. Finally, keep only the objects that spark joy.
00:05:58.900
Great! How do I know if something sparks joy? An object is very useful and keeps your code clean, and it’s not causing performance problems, then it sparks joy. If an object is absolutely necessary and removing it from your code causes it to crash, then it sparks joy.
00:06:34.180
You know, that allowance is kind of like a technical correction. I hate this object, so it helps to determine which ones we can consider getting rid of.
00:07:06.690
Thank you. Very much, I see where you're going, and that's a great point.
00:07:12.690
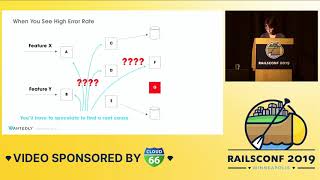
So to put our objects in a pile, we're going to be using two tools: the Memory Profiler and Derailed Benchmarks. First, though, a little quiz time to get you warmed up. Here is a benchmark of two methods that do the exact same thing in two different ways. Both of them determine which is the larger of two inputs.
00:08:25.260
Take a look at this code. One allocates an array in order to perform a comparison on two inputs, while the other simply performs a direct comparison. Now, which of these do you think is faster? Do you think the array version is faster?
00:09:00.220
Okay, I saw a hand go up. What about the comparison version? All right, okay! So, I will tell you: the comparison version is faster. But does anyone know how much faster? Shout out a number!
00:09:26.190
Seventeen times? Anybody else? Three? Okay. Did someone say pie? In fact, it runs about twice as fast as doing it with the array allocation. It’s pretty stark how a dramatic performance difference can occur between the two.
00:09:56.220
In general, touching memory is going to be slower than performing calculations. This isn’t just true in Ruby; it’s true of just about every programming language. Even in C, it’s like a mantra: malloc is slow. Don’t malloc. Only malloc a few times if you have to.
00:10:39.300
Since we know that Ruby allocations are slow, and we've seen at least one case where we can write the exact same logic while performing fewer allocations, we can optimize by removing those allocations at the Ruby level. If a program uses fewer objects, then it's going to run faster. Ruby is also an object-heavy language.
00:11:19.340
In this example, we are returning two outputs as opposed to just one. Even though there's no array involved, the call to the method allocates an array when it runs. Therefore, whenever we're not directly allocating an array, Ruby is still allocating objects behind the scenes.
00:12:18.410
If we can find where we are allocating a ton of objects, that will lead us to potential hotspots for optimization. It's also important to mention that not all object allocations are created equal and some take longer than others.
00:12:57.220
In general, I ignore the number of allocated objects and instead look at memory usage. I've found this technique to be better, as the percentage of objects decreased roughly translates to the performance percentage improvement.
00:13:14.730
If I can decrease the application by about 5% in objects, then roughly it can be made faster by about 5%. It's just back-of-the-napkin math, so you always have to double-check yourself.
00:14:02.370
Because sometimes, to do that, you have to add in additional comparisons, and those comparisons might actually eat up all of that performance you're saving. The neat thing is that bytes reduced is a consistent metric.
00:14:30.000
Typically, whenever you're doing performance work, you constantly have to benchmark — make a change, benchmark, change, benchmark. The problem with traditional benchmarking is inconsistency. You know, you can't just benchmark a method once; you must benchmark it thousands of times.
00:15:09.550
So we have this method: all we have to do is run it once before and once after. If you shave off five object allocations, it’s going to be very consistent. Remember, though, that it is only shorthand.
00:15:54.640
We always have to go back and rerun those actual timing performance benchmarks; we can't just take it at face value. So, okay, got a little off the rails there.
00:16:22.280
The Memory Profiler gem will allow us to take all the applications in our program and view them behind the scenes. This is a nice wrapper for the object space allocation tracing.
00:16:55.300
If you're trying to profile a Rails application, you can use the Derailed Benchmarks gem. This is a gem I wrote, and it will let you hit an endpoint in your application from the CLI. The benefit is that you don't have to start your server, refresh, do all this other stuff.
00:17:23.820
With just one CLI command, you can get benchmark results. It saves me a lot of time, which is why I wrote it. Today, we're going to look at a real-world case study of these tools.
00:18:08.580
I call this section "Inadequate Record." If you pause long enough on stage, people will start clapping and laughing.
00:18:39.410
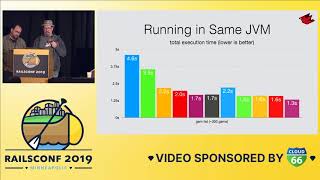
First, we're going to run Derailed against the real-life application, Code Triage. That's going to give us a pile of memory allocations. Okay, that’s a pretty huge pile. Not all of it, actually, because that's just as far as Keynote would let us scroll.
00:19:10.120
The output will show most memory allocations from top to bottom. I start by looking at each file in that order.
00:19:22.720
In this case, we've already looked at several, and I'm going to show you the process of how I go through this. I'm just going to skip to one that's actually interesting for you.
00:19:38.360
Once I pick a file, I need to zoom in and get more information. We can use the exact same command before, but now we need to tell Memory Profiler and Derailed to only focus on a single file.
00:20:02.290
Here's the new output. We are filtering by the single file, and you can see it looks much cleaner now.
00:20:11.160
The majority of allocations are coming from line 270 of the attributes.rb file in Active Record. Let’s figure out what that does.
00:20:32.320
Open that file and check line number 270. Let’s see what it does and why it exists.
00:20:41.530
It's inside the respond_to method in Active Record. respond_to needs to return whenever we have a method on an object.
00:21:00.270
Because Active Record is backed by a database, it needs to say, "Hey, what columns are in this table?" So that it knows what methods are available on that object.
00:21:15.650
In order to do that, it needs a string. Typically, when you call respond_to, you pass in a symbol. But due to how Active Record stores the column names, it must convert that symbol to a string.
00:21:30.260
This is the allocation it’s causing, and since we call respond_to a lot, it results in many string allocations.
00:21:50.660
Once we have that string, we iterate over each of the column names to see if one of them matches the string passed in, and then we check if the actual object we’re using has that attribute. It’s a separate API.
00:22:07.820
Does this object allocation spark joy? How do you feel about it?
00:22:23.460
All right, okay. It’s in use, so it's useful. But it’s allocating a lot, so not very performant.
00:22:30.490
Does it help our code? Or does it help our code to be cleaner? Well, I don't know if it’s absolutely necessary. Okay, good question. We don’t really know yet; let’s find out and see if we can refactor this code while maintaining correctness.
00:23:07.420
Looking at the code, the name variable must be a string because the database columns are stored as strings; therefore, we have to make a conversion. But maybe we can do it somewhere else.
00:23:36.960
My hypothesis is that we can find a way to perform the column check with a symbol directly. To me, this allocation does not spark joy, so let's just throw it away, throw it in the trash, stomp on it, get rid of it. We never want to allocate a string.
00:23:59.610
Let’s get rid of that code. And okay, that is true. This code has been in hundreds of thousands of production applications. It has served us very, very well.
00:24:19.780
Even though it doesn't bring joy right at this moment, I think we should respect it.
00:24:38.410
Unfortunately, if we just do that, then all our applications would break, so we also have to figure out a way to convert our symbol to a string without allocating.
00:25:18.850
To do that, we can introduce a hash. The column names are the keys of this hash, as symbols, and the return value can be the column names as strings.
00:25:41.640
This is our old code we can replace it with this. We can use the hash to check if the column exists and it returns a string, which we then use for has_attribute.
00:26:07.880
We also get a little bonus performance bump because a hash lookup is faster than iterating over every column in the table.
00:26:38.410
One other thing to note is that calling to_underscore generally means an allocation or a type conversion. In this case, the most common thing we’re going to do is pass in a symbol.
00:27:03.562
Therefore, calling to_sim on a symbol just returns that symbol without allocating. Now let's see how much this helps. The patch reduces overall allocations at the web request level.
00:27:28.400
So, a request is coming in; stuff is happening, and it’s being served. It ends up being about 1% of total memory for Code Triage. But is it faster?
00:28:06.490
On average, it caused render times to be about 1.01 times faster, which roughly matches the 1% savings we saw. So, I think we're pretty much done and ready to move on.
00:28:34.560
And you've shown that it’s faster, but you haven’t shown that these results are statistically significant.
00:29:16.520
All right! So who knows what this is? If you said this is a t-test, congratulations, you passed the t-test!
00:29:32.390
So here’s some example code and an example of how numbers can lie. We’ve got two objects, an array and a string. We can take a look at Memory Profiler, and it will tell us that if we duplicate each object, both are the same size in memory: 40 bytes.
00:30:09.990
Pop quiz: which is going to be faster, duplicating that array or duplicating the string? That was actually more of a rhetorical question; you don’t have to answer. So let’s see: duplicating the array is actually faster.
00:30:52.810
No, wait! Duplicating the string is actually faster. Scratch what I said about the array! So, with this information, I could lie and cherry-pick the benchmark results.
00:31:26.785
Instead, we can use a Student's t-test to determine if our numbers are statistically significant or not! Whether this benchmark is showing us a difference or if the difference is just caused by randomness.
00:32:10.670
T-test was introduced in 1908 by William Sealy Gosset, who worked for Guinness. Dramatic pause—why is it called the t-test, if Gosset created it?
00:32:51.990
Well, Guinness wouldn’t allow any of its employees to publish their findings because they were worried that if they said, ‘Oh, this is how this is what Guinness is using, then we’ll use it, too,’ they were very concerned about that.
00:33:24.830
Instead, Gosset published under the pseudonym 'student,' which is a bit uncreative in my opinion. What exactly was Guinness doing with this information? Well, the quality of their product depends on the quality of their ingredients.
00:34:22.590
Different suppliers' quality might vary, and while they could take samples and compare these samples, they needed to ensure they weren’t just comparing randomness.
00:35:06.390
That’s where Student's t-test comes in! In my work, I used a very advanced statistical programming tool. It helps you with Excel and generates a t-test for you.
00:35:38.690
If the result is under a certain threshold, it means the change likely wasn’t a result of random chance.
00:36:06.010
That said, it is a 1.01 times speedup at the total web request level. It’s not just a micro benchmark. Theoretically, if you needed 100 servers to serve your application, now you only need 99. So, you know, that’s something, right?
00:37:03.710
Still, it's just one pull request that shows these good people another example of using my world-changing tidying methods.
00:37:50.480
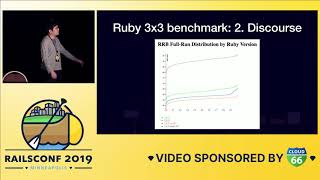
That is the type of enthusiasm I’m looking for! Okay, what’s our first step? We’re going to use Derailed again. Here’s our pile of memory, and like before, I started from the top and worked my way down.
00:38:30.964
Let’s zoom into this file and see if we can make anything faster. This time, we’ll be taking a look at active models.”time_value.rb” When we rerun again, we see that a lot of objects are being allocated on line 72. So let’s go right there.
00:39:00.764
You’ll notice that this method is named fast_str_to_time. Contrary to popular belief, just because you name a method ‘fast,’ it does not mean it’s optimized!
00:39:29.360
On line 72, which I've highlighted here, we are matching our input string with a regular expression. The reason this allocates memory is that there are a lot of groupings to match against.
00:40:05.940
In that process, the major allocation occurs when we’re passing those matches to a new time method. So can we optimize that? Let’s check what it does.
00:40:40.760
When the string comes in, we’re going to return a time object based on this other method called new_time. Can we make it faster? Possibly!
00:41:33.900
The issue is that creating lots of regex matches can be avoided. So with our string that looks like this, we are essentially doing: how do we go from here to a time object in the least amount.
00:42:08.640
We can simplify this by simply checking for that period. A lot of unnecessary type conversions and floating-point calculations can be avoided.
00:42:40.520
Let’s optimize this. In our new method, we introduce guard checks to ensure it starts with a period and has the correct length.
00:43:23.420
Now that we’ve stripped out the period, we directly call to_i on it, and we’ve successfully simplified it without causing additional allocations.
00:43:51.690
Is it faster? Yes, in fact, it was! But we still want to see what else we could do with this method. Let's dig deeper.
00:44:15.420
We can track down the source where this method is being used, which helps explore optimizations there.
00:44:42.410
After looking through the method chain, we find that we generate a cache key for Active Record objects.
00:45:09.520
In our observations, Active Record is converting strings from the database into time objects when they’re needed.
00:45:30.690
The original code creates lots of allocations which slows us down. However, if we strip out all the special characters from the database string, we achieve the same format.
00:46:00.220
So could we possibly convert from the database string directly to that cache key?
00:46:23.410
Yes, we can directly convert the string to a cache key without the expensive allocations.
00:46:42.700
Here’s the revised version of the method where we handle the necessary string format conversion.
00:47:02.220
One thing is important: we need to maintain cleanliness in the code. The original way was straightforward.
00:47:29.440
That said, my method is not cleaner by any means. In fact, it’s more complex! But it achieves a performance reduction of around 5%.
00:48:05.290
Our previous patch only reduced memory allocations by about 1%. So, this approach is quite significant.
00:48:45.910
Every time conversion is CPU intensive, and when I turned this on for my target application, it improved performance by about 1.23x faster.
00:49:23.920
That’s pretty good! It’s statistically significant regarding memory decreases. Remember, the goal is fewer servers required to serve requests.
00:50:08.450
Now, we must thank this old code that we have used for many years. It served its purpose well, and we should respect that.
00:50:48.250
That said, it’s vital to consider how our optimizations impact different database adapters.
00:51:03.070
Not all adaptations return values as strings—some are pre-optimized at the driver level. MySQL, for example, automatically converts the string to a time object.
00:51:37.270
So that optimization will make MySQL slower, while for others, it significantly accelerates performance.
00:52:15.870
Moreover, Benoît from the RSpec core team used my same patch on their application that heavily utilizes Draper, which resulted in performance improvements of 1.53x.
00:52:52.880
So you’re not just optimizing your code for one specific case; it influences multiple outcomes.
00:53:28.860
So, I am sure you’re all excited to try this out and drive it for yourself! Let’s take a second; thank you.
00:54:08.420
This isn’t just about me! Thank you for being my hands. I am pretty comfortable digging around in backtraces, yet it requires ability to navigate the project.
00:54:50.740
It’s more difficult when you can’t type, but Caleb here is a fellow Heroku employee and great handyman.
00:55:19.780
You've taken a lot of time looking through each of these lines, involving comparing dozens or hundreds of call stacks manually.
00:55:34.060
What if there’s a tool that could help streamline that process? Here’s where the debugging tool called Wentz comes into play.
00:56:08.080
It organizes call stacks into a tree structure, counting invocations for each line. It helps visually navigate callers and see the paths taken.
00:56:38.320
This is useful for tracking where a method is called most often, providing valuable insight when investigating.
00:57:08.440
For example, if you have a piece of code you’re not sure about, this approach lets you track down where it’s being used.
00:57:33.480
Wentz collects an array of for every invocation, creating a tree that makes the call stack easier to navigate. Though it's still in early development, you can try it out for yourself!
00:58:03.520
To recap: first, we want to take all of our object allocations and put them in one pile where we can see them. Then we consider each one: does it spark joy?
00:58:33.400
Finally, keep only the objects that spark joy. Hopefully, I’ve convinced you that object allocation hotspots are excellent indicators of potential performance optimization locations.
00:59:06.250
And I think you’re potentially ready to try these techniques in your code or your own library.