00:00:16.560
Um, let’s see. My name is Chris Maddox, and I work at ZenPayroll, where we handle payroll.
00:00:22.720
Failure is something that we think about a lot, especially since we transfer hundreds of millions of dollars every year, soon to be billions.
00:00:28.960
Our growth team gets really excited about this, saying, 'Oh, billions of dollars!' But honestly, I just want to focus on doing my job well.
00:00:34.480
Today, we're going to talk about failure and some ways we've preemptively addressed it. We have an agenda like a business meeting, which I think is great.
00:00:45.760
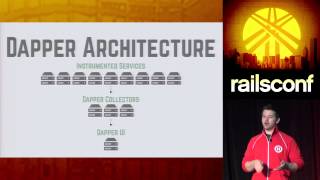
We’ll discuss predicting failures, approaches we’ve implemented to avoid mistakes, particularly regarding database validations and user models. Then, we’ll cover recovering from failure, which is critical for us.
00:00:57.280
While preventing failure is important, making sure that if something goes wrong, we don’t lose sensitive user information is our top priority.
00:01:14.240
Finally, we’ll talk about embracing failure, which might sound odd, but I'm a philosophy major—so I'm excited to dive into this topic.
00:01:19.759
Chapter one: changes. DHH, I’m a writer now, so we’re organizing this into chapters. My predictions, however, have been notably inaccurate.
00:01:37.439
Robert Caro, a biographer, has been writing a four-part series on Lyndon B. Johnson for 30 years. I’m only 23, so I can’t fathom that length of time, but I wish him the best.
00:01:56.479
I’ve encountered issues on the internet several times where errors aren't communicated well.
00:02:02.719
For example, you might receive a message saying, 'There were some problems with your form; please fix the errors before submitting again,' yet the system fails to show what’s actually wrong.
00:02:20.959
I'm certain many of you have faced situations where you try to submit your information, only to be confronted with vague error messages that lead to frustration.
00:02:38.080
In the case of a payroll platform, incorrect validations can lead users to believe they’re on track, while the issues lie elsewhere.
00:02:43.120
Unfortunately, this leads to confusion and frustration, not just for the users but also for the support team who may be unable to provide clear answers.
00:02:50.400
This issue worsens as your application grows in complexity. Payroll is intricate, with a lot of information to process.
00:03:02.959
For instance, I mistakenly misconfigured Mr. Vonnegut’s bank account, which means he won’t get paid the way he expects.
00:03:28.159
Yet, the user is unaware of this mistake because they are editing a different section. They will face validations that don’t make sense to them.
00:03:39.599
This ultimately frustrates users when they need support, leading to a snowballing effect of problems.
00:03:52.080
As a result, users are prevented from fixing or even perceiving the real issue, which can lead to cascading errors across processes.
00:04:09.920
Two main culprits behind these failures include using update_column and update_attributes with validate: false, which, while often necessary, can be detrimental.
00:04:51.120
When certain situations arise, like needing to save information despite an error, these functions can be useful. However, they can also result in losing sensitive information.
00:05:03.600
Preserving user information is critical for us, especially since losses could amount to tens of millions of dollars per single transaction. Getting this right is absolutely essential.
00:05:25.440
From this, we’ve devised solutions to validate data upfront rather than relying on user input alone—this is achieved through Rails validations.
00:05:31.760
I learned from a colleague, Nick Drivassi, that we could run validations for every model in the database every few hours. Initially, I thought it was a terrible idea.
00:05:53.440
However, it turned out to be a game-changer, and we now validate every model in the database every three hours.
00:06:00.880
This entails pulling production data to validate it against our merged but undeployed code, allowing us to catch future errors before they become problems for users.
00:06:35.520
This proactive approach has been incredibly beneficial, providing us with the lead time necessary to address issues more calmly, rather than in the moment when users often feel frantic.
00:07:11.680
Shifting gears a bit—this concept reminds me of the pre-cogs from the movie 'Minority Report.' In the film, these genetically modified individuals predict murders.
00:07:38.560
While their ability to forecast rather grim events may raise ethical questions, it provokes thought about how we can foresee errors in our own systems.
00:08:02.159
We’ve begun to create long-running jobs to understand the eventualities of errors in our applications, especially with complex transactions that involve multiple parties like the IRS.
00:08:21.680
Managing financial transactions can be a convoluted process, especially considering the communication barrier with banks after a transaction has been initiated.
00:08:50.560
After the transaction begins, responses regarding success are limited. You only know it’s complete if there isn't a failure notice days later.
00:09:16.960
This means we must ensure that everything within our control operates smoothly prior to going live with any updates.
00:09:39.760
Now let’s pivot to recovery from failure, which is actually a fascinating topic.
00:10:02.080
Predictions about errors are interesting and beneficial, yet how we recover once an event occurs is something I believe requires more focus.
00:10:25.679
Every other day in practice, I see that what makes you better is how you respond to failure, including ones caused by you!
00:10:50.800
Mia Hamm once shared that failure happens to everyone, and it’s how you address it afterward that defines growth.
00:11:12.640
Reflecting on the inception of our Rails app, it’s inspiring to remember the early excitement while also recognizing the intricacies involved in payroll systems.
00:11:43.440
Managing a system of maintenance was overwhelming, with one very large method running for a long time, which sometimes led to unexpected errors.
00:12:05.520
When the state becomes uncertain due to an error, regaining stability is challenging and often feels reminiscent of brain surgery.
00:12:34.960
Many underlying dependencies can cause issues, leading us to confront situations we never anticipated with banks, the IRS, and various other integrations.
00:12:51.120
As we developed our API-driven services, it seemed easy to demystify responsibility on components, but once they went wrong, chaos ensued.
00:13:07.360
One particular pain point with the IRS came when the government shut down unexpectedly, leading to delayed faxes—an edge-case we hadn't accounted for.
00:13:23.760
The struggles surrounding the possible failures we face continues to highlight the complexities present in our operations.
00:13:43.760
To reduce the likelihood of complete system failure, we began dissecting existing processes into smaller, manageable pieces.
00:14:01.120
By localizing issues, we can continue payments for users while fixing others, like syncing with external APIs.
00:14:15.960
Our approach led to several new libraries we developed, like Ultramarathon, which helped understand connections and dependencies more clearly.
00:14:35.360
The philosophy guiding various processes is about minimizing interruptions and focusing on granularity, where possible.
00:14:49.920
We also incorporated infrastructure that allows us to recover from partial failures instead of completely snowballing an operation.
00:15:05.920
Now, even if a job fails, we’re able to run other pieces without hassle or halting everything.
00:15:18.080
Additionally, we implemented detailed instrumentation to better understand where issues arise.
00:15:28.560
All this contributes to a more resilient system designed not just to handle growth but to accommodate errors as part of the lifecycle.
00:16:03.440
Accepting that failure is a natural process in software development is critical, and I learned this lesson from my dad.
00:16:33.600
Recognizing that we handle serious matters, the stakes can lead to unnecessary panic; people rely on us to manage their payroll effectively.
00:17:09.440
While we started with a philosophy where failure is unacceptable, it became evident that such pressure isn’t conducive to a healthy work environment.
00:17:38.880
Ultimately, I believe it’s our responsibility to not only avoid failure but also to mitigate its impacts when it does occur.
00:18:06.880
Reflecting on experiences, I feel it’s crucial for our growth and learning to accept failure as part of our evolution.
00:18:43.440
The philosophy to embrace failure allows us to nurture resilience and a culture of learning within the team.
00:19:15.840
If there’s one takeaway today, it’s to recognize that failure is a part of the journey—something we can learn from, rather than fear.
00:19:42.560
So, if your company is sponsoring you for this talk, take that advice with caution!