00:00:19.489
My name is Yoshinori Kawasaki, and here are my Twitter handles. Please follow me if you can read Japanese; the one on the second line is where I'm more active. You can reach out to me with any questions after the talk. I work at a company named What a Tree in Tokyo, which provides web services and mobile apps that help people meet exciting companies and find future teammates who share their interests and passions.
00:00:44.699
To start, let’s do a quick poll. Please raise your hand if you work on a microservices architecture. Okay, thank you. I assume you are experiencing challenges when trying to debug or fix issues whenever problems arise. This talk is for you. Now, how many of you are working with a monolithic Rails architecture? Raise your hands. Great! For those of you working with a monolith, you may feel productive in developing your codebase, which can be quite large and complex.
00:01:20.310
However, if your product is successful, your system and engineering team will likely grow rapidly. So whether you are in a microservice environment or still using a monolithic architecture, this talk has something for you. I posted a poll on Twitter this morning, and I would appreciate it if you could vote before the end of the presentation.
00:01:54.390
In this talk, I will explain why you need distributed tracing, what it is, and how it helps in microservice architectures. In the second part, I will introduce OpenCensus, a set of libraries for distributed tracing and other observability features. Finally, I will show you how you can use OpenCensus in your Rails applications.
00:03:19.740
Let’s first talk about microservices. Everyone seems to be excited about microservices, right? At first, it sounds like a productive way to scale your system and team. However, as you start implementing microservices, you quickly realize that it can become quite difficult to manage.
00:03:39.180
Let me show you how our system used to look back in 2012. It was straightforward. We had a single monolithic Ruby on Rails app with a tiny database, so the only programming language we used was Ruby. Fast forward seven years, and we have grown significantly, going public and opening offices in four countries. Our system now consists of more than 100 services and 20 databases, built with five different programming languages including Ruby, Go, and Python. This exponential growth complicates things.
00:04:25.169
The challenge with microservices architecture lies in understanding the interactions between various services, especially when there’s an end-user request. You need to pinpoint which microservices are involved when a problem occurs. For instance, we have an app that scans business cards. When you scan a card, it detects text and sends the image to the backend. It extracts the text, categorizes it into various fields, retrieves company information, and sends that back to the user. This is a lot of work happening under the hood.
00:05:06.590
On the right-hand side, you can see a diagram that illustrates the microservices and databases involved, as well as the sequence of calls being made. This chart was created manually by sifting through the source code of different microservices. While this was crucial for new engineers on the team to understand how the endpoint worked, it is impractical to do this for every API endpoint.
00:05:52.760
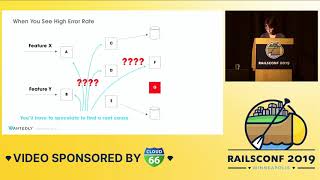
Now, let’s take a hypothetical scenario with several microservices and two databases serving two features, X and Y. If a user reports that service G is throwing a lot of errors, you would usually speculate about which microservices might be affecting this feature. You try to determine recent changes to those services without any clear visibility into how they are interconnected.
00:06:40.000
This lack of insight makes debugging incredibly challenging. With distributed tracing, you can capture the causal links and understand how components cooperate in a single request. It shows you which components were involved, in what order they were called, and how long each operation took. This way, you can identify if an operation is failing or taking longer than usual.
00:07:45.070
A trace is a collection of operations performed within a single end-to-end request. Each operation is represented as a 'span,' and this structure allows for a tree of spans showing the relationship among operations. Each span contains information like start and end times, along with other contextual details.
00:08:56.840
Let me show you how distributed tracing looks in practice. Here’s an example from DataDog, where each color represents a different service involved in a request. You can see how long each service took to handle the request and the relationships between them. DataDog also offers a service map, which effectively acts as a dependency graph for your microservices.
00:09:48.920
This service map is created automatically from tracing data, providing dynamic insights into your system without needing manual intervention. If you click on any component, you can get more information about upstream and downstream dependencies.
00:10:35.230
Another similar tool is Stackdriver from Google Cloud, which offers similar functionality. For example, you can filter traces based on latency and drill down into more contextual information. Now, let’s discuss OpenCensus, which is a set of vendor-neutral libraries for collecting and exporting traces and metrics.
00:12:08.320
OpenCensus was originally developed at Google, and is designed to work across various programming languages, including Ruby, Java, Python, and more. It focuses on capturing telemetry data and allows you to send this data to whichever backend you prefer.
00:12:53.070
This flexibility means you can test different backends without being locked into one option. In OpenCensus, the data model leverages protocol buffers to define what fields are captured, such as trace ID, span ID, duration, etc.
00:14:08.370
When using OpenCensus, you can create spans on both the server and client sides when making remote procedure calls or HTTP requests. Spans contain vital data, including start time and end time, and they help in tracking performance across different components of your system.
00:15:55.760
Let’s break down how to integrate OpenCensus into a Ruby on Rails application. Each application should include a collection and exporter module provided by OpenCensus. When making an HTTP request, you pass trace context like trace ID and span ID through HTTP headers.
00:17:35.520
The OpenCensus middleware extracts this trace context from incoming requests and creates a new span for the process. It can also capture common events in Rails, such as database queries and rendering view templates.
00:18:15.700
By leveraging ActiveSupport notifications, you can subscribe to specific events and track them effectively in your traces. For outbound requests, the middleware wraps HTTP calls to create spans and populate them based on the response.
00:19:50.750
Overall, using OpenCensus makes tracing straightforward and productive. If you want to implement distributed tracing in your Rails app, you can do so by configuring the middleware to auto-inject tracing capabilities.
00:21:10.030
This flexibility allows you to send traces to multiple backends without being constrained to one solution. If your required exporter isn’t available, you can create your own, and the process is simple.
00:22:55.740
As we wrap up, I want to emphasize that OpenTracing, similar to OpenCensus, provides support for various programming languages and tracing backends. They are in the process of merging, benefiting the community as they combine their efforts.
00:24:30.850
In conclusion, distributed tracing is instrumental in understanding and troubleshooting your microservices architecture. It provides you with valuable insights into your system’s performance and interactions.
00:25:54.820
You can start implementing distributed tracing easily with OpenCensus today. Thank you very much, and I would appreciate your feedback!