00:00:16.710
Welcome to my talk. I'm Jeremy, and we're going to talk about systems design.
00:00:21.720
I don't think we do enough of this. Cool, the URL to my slides is apparently up there.
00:00:29.310
For the past three years, I've worked at Kenna Security. Our application has changed a lot in that time.
00:00:34.410
It has had to evolve and become more distributed as our organization has grown. We've been processing a larger volume of data and have learned a lot from that process of migrating and refactoring our system.
00:00:39.989
However, it’s hard to find resources on how other companies have managed through similar transformations.
00:00:45.030
I'm leading one of these efforts to dismantle some pieces of our application and, while this effort isn't always straightforward, I'm constantly afraid we're creating these separated but interconnected towers of responsibility. We think they are encapsulated, but they just aren't. A couple of years back, I read this book that amazes me with how much it translates to my design challenges and many other problems. However, all the examples in the book are about code—how to rearrange it and how to make it resilient to change, which is great—but I want to know how that relates to the bigger picture.
00:01:15.650
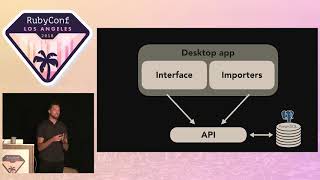
Let's start off with some code. For example, we have this library application, a cataloger. I'm glad the syntax highlighting is visible up here. What it's doing is taking a list of books from the internet and creating a record of them in our system. It's a promising start, but we have a lot going on here.
00:01:28.080
There's a lot of behavior packed into this code, and if we want to improve it, identifying the roles and responsibilities isn't too difficult because there are great tools and advice from the community. People like Sandi Metz and Katrina Owen have made talks that have turned these concepts into common knowledge.
00:01:39.660
For instance, we can apply the squint test to see the shape and color of the code to identify where something reaches into another class or where it knows too much about its behavior. We have this API client that contains some configurations, a parser that probably shouldn’t be there, and we do a lot of validation in this code as well. All of these behaviors can be extracted and separated into smaller classes with better designs that encapsulate roles. But what about this?
00:02:00.820
We’ve taken that code and put it into a worker—a background job DSL. It’s not immediately clear where we’ve abstracted away a lot of the configuration and how we are queuing work and how everything relates.
00:02:06.920
It’s difficult to figure out how to apply many of these design patterns or tools I’ve learned, and that dilemma feels frustrating. In the broader context, where do I even start translating that knowledge of designing these things? If my system has a worker that is constantly having load issues, dropping due to disk space, or being overwhelmed, how can I begin to improve that? Where do I even start thinking about refactoring it?
00:02:43.360
My first instinct, when I encounter such problems, is to consult my good friend Tony. His cat probably can attest to the numerous dumb questions I've asked over the years. This has become a point of emphasis for us; we've developed a vocabulary to discuss these things.
00:03:06.060
We talk about testing, mocks, dependency injection, and interfaces, which enables us to identify good patterns from bad ones. But why is there a discrepancy when we discuss our systems outside of the code? Why do we suddenly abandon our design tools? Is this really such a different problem? We are still passing messages, which is fundamentally similar.
00:03:34.350
This question has fascinated me for the past year. Design is fundamentally about managing dependencies within your application and the people working on it. It's about being flexible and adaptable to changes, having small simple pieces that compose together. For example, if I wanted to change the data store that my reporting service queries, how easy would that be? It's actually quite challenging, given that these data stores are typically intertwined across the organization. Often, the original person who set it up may no longer work there.
00:04:07.850
As a new hire, I lack breadcrumbs to follow, and organizationally, I believe we could improve in this area. I’ve encountered some anti-patterns because that is what I should address. These revolve mostly around communication. Discuss these issues—if you’re new, don't hesitate to ask questions. Keep these topics alive in discussions and, if you're established, be open to change. Even if you don't think you have a problem, sharing knowledge is vital.
00:04:46.299
Maybe documentation could help—it’s best to have a few brains on the architecture of the system. We’re all in this together. There are various ways to reach workable solutions. The social issues within an organization primarily arise from having someone exclusively make these decisions, which can hinder productivity. Newer team members should have the opportunity to learn and possibly make mistakes just as established engineers do.
00:05:16.170
This is essential for growth. Not providing this chance leads to engineers hesitating to make changes because they feel unqualified in certain parts of the system. Be aware of operational and monetary trade-offs; discuss your decisions' costs and benefits comprehensively.
00:05:37.060
We all make assumptions about the network's behavior. These aren't merely operation or system problems; we must remain conscious of them while reading and writing code. Code is directly in front of us, and we can interact with it, but these underlying issues can be actively abstracted away from our awareness, even though they have real implications.
00:06:02.400
It’s essential to recognize that a lot of things in our code depend on numerous non-deterministic elements of the network and the service responses we get back. Now, what can we change? Not much; at its core, it’s a simple method of passing arguments. There's not a lot we can do from the code perspective to make this more fault-tolerant, more resilient to change, or more flexible. Instead, we need to broaden our toolkit beyond the code.
00:06:56.009
The two best resources that I recommend are as follows: the left is authored by Steen and Tannenbaum. It covers the academic aspects of distributed systems. It’s frankly quite dry but packed with details, focusing on making a single service, like Elasticsearch, highly available and resilient to faults across various nodes and over the network. The other book by Martin Kleppmann goes into the intricacies and trade-offs of many modern tools offered by various cloud providers.
00:07:26.289
Here are the main takeaways from this literature, at least as I see it: we want to hide communication as asynchronously as possible. You might not realize how much nodes talk to each other. They frequently health-check to see whether they are available, and that communication is substantial. Effective load balancing is essential, especially when using queues.
00:07:56.150
Performance monitoring and queuing theory are vital aspects of the picture. Don’t be afraid to replicate data; cache it locally in your client process. Whenever we call outside the network, it's slow, expensive, and vulnerable to failures in the network. Instead, we can store it as a variable in our application, which represents a form of caching.
00:08:14.840
This technique is common, and we can also utilize a read-through cache. However, what's often overlooked is the expiration of these caches— determining when they should be invalidated. Variables persist for the duration of the entire processing, which means if we’re managing a long-running job, we might be operating off stale data.
00:08:43.349
Database entries may have lifespans that stretch for years without updates. The only predictable cache is the read-through cache because we explicitly decide when it expires. This leads us to consider the consistency costs and primary trade-offs we need to determine.
00:09:03.450
Meanwhile, in Clements' book, there are dense notes to consider. It covers a lot of content, addressing encoding messages, protocols between services, and RPC protocols like gRPC and JSON. We're not really discussing this here, so let me move on to how you partition your databases. The book also provides many algorithms you'd want to use.
00:09:51.560
One easy suggestion is to find a cardinal value—something unique to a set of data—and use that. It is perfectly acceptable to use data stores that are tailored for particular purposes. In fact, specializing in this manner can yield better performance than trying to create a one-size-fits-all solution in traditional SQL databases.
00:10:37.650
Your I/O work should be made thread-safe, and if something does change, you can stream your updates smoothly. Now, let's take a moment to focus on the topic of events. There exist many misconceptions regarding stream processing in relation to event sourcing; they are not the same. There are two primary methods for transferring information: by function, which denotes how it's operationally presented.
00:11:09.980
Alternatively, you can transfer by result. When inserting into certain logs or queues, they have distinct properties that are advantageous or detrimental depending on your use case. The latter is order-dependent, making it difficult to distribute work as different computers have varied clock synchronization issues—a problem academics tend to enjoy.
00:11:59.390
Despite these challenges, there’s an exciting property: if you ensure that the last write wins, you can disregard the rest of the operations. You simply need to agree that your progress should be preserved, processing the queue in a last-in-first-out manner, which can be quite effective.
00:12:26.420
On the left is the associative property; we don't need to maintain sequential integrity.
00:12:43.140
The only necessity is to ensure that everything is processed. Concurrently, if we wish to recreate the state, we would need to replay all operations in the system.
00:12:52.370
This is about identifying design patterns; it’s all about making informed choices, which aren’t silver bullets. The most significant takeaway from this process is pinpointing systems of record versus derived data within your application. This may be poorly illustrated by the example where Function F relies on G, which relies on H, and so on.
00:13:29.459
We need to process each function sequentially to process the final output. If I modify how Function H operates, I must rethink and re-process everything that follows it. Alternatively, if we manage to distribute the functions relative to a single source of truth or a comprehensive system of record, we can pioneer changes that don't result in others being dependent on them.
00:14:09.689
This establishes a significant difference between having close-knit, coupling violations and a composable object—a design flaw, indeed, but one from which we can build optimism moving forward.
00:14:33.680
Returning full circle, comprehending our entire system in this manner allows us to decipher where dependencies lie and design accordingly based on what they require—primarily, the data.
00:15:00.750
As a rule of thumb, utilize the actor model for communication and implement message queues for asynchronous work. Ensure that the actions performed are idempotent. There’s a significant reason these principles are included in the Twelve-Factor App methodology.
00:15:37.880
Pre-compute as much work as you can. If you know what will be exhibited to the user, strive to perform that work out of band from actual display requirements.
00:15:55.820
Identify where data is derived within your application; this provides more insight into how to manage data effectively. Ascertain consistency costs, and recognize limitations within your system. Pay for aspects that need to be real-time and ease constraints wherever possible.
00:16:11.390
This approach aims to maintain simplicity within interactions between services operating within your system. Now, let's revisit our library example and build some blocks, demonstrating how our system has evolved at Kenna.
00:16:55.800
The first crucial component here is the worker. This is how we handle asynchronous processing.
00:17:05.621
If we maintain transparency with failures and ensure that these processes are idempotent, we can simply terminate the process if it faults and retrace the work back to the queue for reprocessing. Workers pick up tasks from queues. Choose a format for messages, being mindful of optimizing the queuing behavior.
00:17:52.290
This strategy helps to avoid redundant work, materializing your data into a view. Precompute what can be reused, and invalidate caches in a predictable manner.
00:18:02.290
Create artifacts derived from costly computations, allowing you to implement a circuit breaker system that defaults to last-known values if your current job fails.
00:18:26.640
Such methodologies promote simple interfaces across the application. Let’s discuss some universal behaviors that most applications have, such as interfacing with external APIs or maintaining relational models over a network, deriving data points through business rules, and performing computations on our datasets.
00:18:53.420
Now, it is essential to equip ourselves with the right tools. For example, when considering displaying reviews from Goodreads or other services, how do we integrate them into our application for users?
00:19:18.470
We could embed this directly onto the front-end, granting as strong a consistency as possible since we display what exists in the external service. However, each render requires network validation.
00:19:39.190
Alternatively, we could transfer this interaction to the backend and implement read-through caching, still allowing for real-time rendering while batching requests to ensure fewer calls.
00:20:05.170
If we anticipate the information needed, we can utilize a worker to process this in the background, making queries asynchronous while also being idempotent if discrepancies arise.
00:20:27.210
However, keep in mind that identifying changes is often tricky; not all APIs provide a comprehensive change set detailing every modification over time.
00:20:58.680
What if we want to allow users to add reviews back to the external service? This creates a challenging scenario since maintaining the consistency of what we have can be somewhat elusive.
00:21:11.610
One option is to implement a client consistency model where new content is only displayed to the user's session, leading them to believe they’ve updated the Goodreads system while we manage the processing at our discretion. This could enable us to batch requests and comply with API limits.
00:21:53.000
There are several advantages to this model, although it complicates handling authentication and can mislead users about the accuracy of their input, which isn't always ideal.
00:22:24.390
Another approach is to update our internal state and invalidate our caches using priority queues. This has proven effective in about 90% of use cases, allowing for continued asynchronous processing with retry mechanisms.
00:23:05.940
However, this method also involves trade-offs that must be balanced in order to maximize benefits. For relational models, maintaining records across distinct repositories introduces complexity.
00:23:41.396
For instance, if we want to add a book and author and display that to the user through a background job like our cataloger, how can we ensure transactions and joins across multiple tables?
00:24:17.940
This becomes increasingly complicated when working in service-oriented architectures, whereas in a monolithic setting, wrapping each insertion into a single transaction works seamlessly.
00:24:53.331
In other words, you have set guarantees from your data store if you follow relational database principles. However, a service-oriented approach can impose an upper limit on how much data can be held in simpler locations, which may affect performance.
00:25:15.200
In our case, we partitioned our databases by cardinal value, allowing for client-specific processing and aligning with our role-based access schemes.
00:25:43.170
But when it comes to connections, it can be challenging to retrofit existing systems like Active Record when database connections aren't managed effectively across several sources.
00:26:10.309
Such limitations hinder query capabilities and lead to hotspots, especially with clients managing numerous vulnerabilities, which isn't perfect.
00:26:37.300
The common advice seems to be wrapping everything within an API, ensuring that foreign keys are managed under a RESTful structure, simplifying how we store data in tables.
00:27:03.390
Nonetheless, this method lacks support for transactions between separate tables and many services are often needed to access information.
00:27:29.110
The consensus seems to favor maintaining transactions working in sync, using an event stream, and leveraging those logs to conduct transactional updates and rolling back operations if any fail.
00:27:51.890
This provides better consistency, although the need for distributed processing with tied stores means one depend on another before finishing, which can limit the overall effectiveness.
00:28:11.230
But what if we simply didn’t care? Expecting perfect data in your system is unrealistic, so prepare for it to be flawed.
00:28:31.890
Choose decisions wisely, invalidate irrelevant relationships, and conveniently version those that depend on actual transactions.
00:28:54.880
Have workers serialize those changes into readable formats and facilitate computations to optimize ongoing calculations.
00:29:12.430
This summarizes the evolution of our system as we encounter limits within our data stores. Always plan for the size of issues you’re addressing; refrain from premature optimization.
00:29:52.704
Use the simplest approach as a guide; however, remain intuitive about future nuances and potential complexities.
00:30:12.832
How do we describe the operational rules in our system?
00:30:34.920
Let’s say that we want to source new records from various social media platforms. The simplistic method would consist of a find or create process where records and transactional creations are locked.
00:31:11.230
This could eliminate some race conditions, yet hypocrisy remains, as we'd lose track of the sources when making updates.
00:31:28.557
CRDTs are a fascinating perspective on this problem, though I won't dive into that here. In general, we should attempt to save data as close to its source as possible.
00:31:50.950
Cleaning and normalizing the data in accordance with the system’s requirements is critical. Such models do not always have to exist as separate services, although they often are. Using versions can help you troubleshoot inconsistencies without being reliant on external APIs.
00:32:49.810
Ultimately, in terms of what we are accomplishing with this information, if the model generates an event log, this is predominantly an aggregated view. We're embedding different records and being able to capture variations in our algorithms, making it powerful to evaluate performance.
00:33:48.420
Let's also address how we can query, compute, and conceptualize our data in ways that create value for customers. First and foremost, whenever you update an attribute on a record, you are likely doing it wrong. This impacts derived data from costly computations.
00:34:11.820
Having distinct artifacts strengthens our operation, allows us to seamlessly manage circuit breaks for existing data, and helps identify anomalies by running sanity checks prior to going live.
00:34:53.430
By utilizing artifacts, you can compare the changes and regressions in computations over time, facilitating a more organized approach. The first enhancement over an entire table scan is to batch processes effectively.
00:35:18.850
Finding segmentations helps in making this task memory-efficient. Even if partying data achieves greater efficiencies, we still contend with common challenges.
00:35:46.180
In essence, throughout these workflows, connecting datasets properly and composing them meaningfully are key components of an effective architecture.
00:36:13.510
If you'd like additional information, I encourage you to attend the talk by my colleague Molly Strube; she'll be covering the topic extensively.
00:36:30.520
Ultimately, simplicity guides our reasoning regarding systems and enhances how we collaborate with one another. Thank you all for your time.
00:36:51.780
Here’s some contact information and resources for further reading.