00:00:24.630
The name of this talk is "Use the Source, Luke: High-Fidelity History with Event-Sourced Data." The first part took me the better part of a night to come up with it. I hope you all like the title. My name is Keith Gaddis, and as of last week, I work for Spiceworks, which is one of the sponsors of RailsConf. This talk is not affiliated with them in any way, shape, or form, so don't hold them responsible for it. My contact information is on the screen; it may be hard to read, as it's quite tiny.
00:01:09.399
Before I get started, let’s see a show of hands. How many of you here hate Active Record? Raise your hand. Okay. If you have a love-hate relationship with Active Record, put your hand up. Alright, the five of you left are excused; you can go ahead and leave if you think Active Record is the be-all and end-all of ORM. God bless you, but this is probably not the talk for you. I’ll talk a bit more about my adventures with Active Record later.
00:01:48.390
Let’s talk for a second about event sourcing and event-sourced data. Martin Fowler defines event sourcing as capturing all changes to application state as a sequence of events. What does this mean? Application state changes are encapsulated as events, so whenever your application state changes—like a counter incrementing—that's an event, and there's some data associated with that event. An event encapsulates that change and keeps it all in one place. What this allows you to do is serialize and store these events, creating a history of changes to your data.
00:02:54.709
A lot of benefits come from this. One of them is that you can later recreate application state for any point in time. As you might imagine, there may be some performance penalties from trying to create application state this way, so we generally store snapshots of the data. This comes out of domain-driven design (DDD) and is commonly used with a domain model. We often think of Active Record models as our domain models. For years, we’ve talked about the philosophy of the fat model and skinny controller, pushing all the domain logic into our Active Record models. However, Active Record models are not domain models; they are structural models. There's nothing particularly wrong with that, until you get into really complicated domains where structural models become an anti-pattern due to their limiting factors.
00:03:40.250
Event sourcing holds the data we need to mutate our application state, and we refer to the process of applying the event as "applying." Changes are made to the state in your application, and listeners are other objects that can listen to these events and make changes based on them. These changes are not application state changes and may involve talking to an external service or persisting the events in other forms or fashions. So, what are some of the benefits of this approach? The events represent the history of your data. If you only change state through events, then by persisting those events, you essentially version control your data.
00:04:06.859
That can, at times, seem to result in a really large dataset. However, you are not persisting the entire database for every single change along the way. Instead, using these fine-grained events, you can recreate the application state for any point in time—it’s like time traveling through good data. For example, take account history. Has anyone ever heard of the phrase "closing the books" on accounts? You’ve probably dealt with the issue of having to get your receipts in by the last day of the month or you may not get reimbursed, as they close the books on that day.
00:04:58.479
So, what typically happens when closing the books is they make a copy of the database on that date, and then they cannot make any more changes after that point. Anything that happens afterward happens in another month's "book." The reason for this is that they need to know what accounts looked like at the end of that day. With event sourcing, one use case might be the ability to replay events up to that book date—essentially up to the end of the month—which can be done at any point in time. Therefore, closing the books is no longer a finite action; while we may still refer to it, you can close the books at any point in time.
00:06:05.389
Another key benefit of event sourcing is that you will rarely have to say "I’m sorry" to your business people. Bug fixes become a matter of identifying the issue in your domain logic and replaying events so that the bug fix never happened. You can pinpoint where the bug was an issue and add new events to correct state, similar to account transactions. For instance, if a bank accidentally deposits too much money into your account, they will eventually make a corrective transaction to withdraw the excess funds. You can do much the same when there are bugs or errors in data entry with event sourcing.
00:06:50.100
The history allows you to look at what happened and automate corrections where possible. Has anyone had to fix migration errors or use migrations to correct data errors from a bad upgrade cycle? I bet there are more than a couple of you in here. Alright, there we go, honesty comes out. Such challenges become simplified with event sourcing. Another compelling use case that brought me to this domain is the use of heavy and complex analytics on your data. I used to be the CTO for a medical billing startup. Anyone who has ever been to a hospital in the United States knows this is an incredibly complicated area; straightforward medical billing systems are quite rare.
00:08:01.370
There are some kinds of reports that all industry players know about, but we were a startup without particular expertise in that area and didn’t know about them. As we went through the typical Rails evolution, we started off with highly normalized Active Record models, as we didn't want to repeat ourselves and preferred to ensure only one point of truth in the system. While it's all important stuff, it led to situations where some of the reports we needed couldn’t be generated off of normalized data. We had to create additional processes in our application to reflect or project that data into different structures.
00:09:01.850
This means that for some reports, if they weren’t generated in the process of creating the data, you couldn’t access them later. There was no do-over; if you didn’t get it right the first time, you were kind of stuck. For these scenarios, event sourcing is something you’re going to have to implement eventually. However, we don't call it event sourcing because the event is not the primary driver of the mutation; it's not the source of the data.
00:09:56.390
Sorry, I have my screen saver set to paranoid mode. The events are not the source of data, but you still use those events—Active Record observers, for instance, are all about reacting to some event in the system. By using the event as the source of change and the source of truth, we can create a system that allows us to echo these events out to different other systems and not muddy up our domain area with the extra changes we need to track data in this table versus that table just for one report.
00:10:48.120
Another benefit is that it helps you prepare for the future. In our case, we were unaware of the future needs we would have; had we known, we could have better prepared. Yet, in any application you start with, there will be unknowns. Has anyone had a business stakeholder come to you and say, 'Oh, we need this now. Well, we needed it last week, but you need to do it right now'? It happens to me all the time. In many cases, event sourcing will require you to model your domain, meaning you need to truly understand what you are doing. This leads us to dedicate time to thinking about our Active Record models.
00:11:39.000
Instead of mixing behavior and data within the models, event sourcing pushes you down a road where a clear distinction is made between domain logic and other functional concerns, decoupling the two. By pushing all the domain logic into a set of strictly Ruby models, we separate business behavior from non-business logic, which introduces cleaner architecture. For example, if you were talking to healthcare clearinghouses about billing, this is not part of your business logic; it is a business requirement from another area. We can decouple that through event sourcing.
00:12:39.800
However, there are drawbacks to consider, particularly around whether this approach is overkill. If you are in the early stages of product development or a startup, this might complicated things more than necessary. While I have employed this approach in multiple instances, it does come at a cost, particularly in analyzing your business demands and truly understanding the problem. It's not always clear what you are dealing with; startups might frequently create new demands and problems, creating a scenario where pre-analysis may not always be possible.
00:13:53.990
As mentioned, the domain may be unclear. There’s also a trade-off with agility; early-stage companies want to move quickly, and implementing event sourcing could impose constraints that may limit rapid movement. This isn't a reason to avoid the practice altogether, but it's essential to weigh these trade-offs. Event sourcing can enable you to handle complex analytics well into the future, even on datasets that reach far back in time, which can indeed be an overriding concern depending on your project.
00:14:54.620
Another drawback is performance. In some cases, it's common to have large event logs; think of a stock trading domain, for instance, where millions of trades happen in a single day. Replay all those events to reach the end state could be performance-intensive. To mitigate this, we store snapshots of the domain models, which can be done in various ways during the snapshot process. The end result is that we don’t have to play through all the events in a snapshot fully. We might snapshot every time a new event comes in since it’s done offline without performance impact.
00:15:50.470
Active Model is beneficial in this regard; it's a robust tool that has emerged from Rails. Active Model provides easy-to-use hooks and functionalities for serialization and property definitions for models. There are also common use cases for event sourcing. One is source control. Many of you use source control systems. Every commit serves as an event, allowing you to jump back and forth through the history of a project by checking out different commits.
00:16:28.280
Another common use case appears in financial and accounting systems, which are domains where you absolutely must maintain a fail-proof audit trail. It's vital to prove how you arrived at any number. Federal regulators will want to talk to you, and it won't be a friendly chat. Moreover, things can get complicated in various fields, and if your area requires higher education to navigate, it might be complex enough to consider utilizing event sourcing. Industries like engineering and medical applications frequently involve intricate domains where clarity is essential.
00:17:54.580
Let’s look at a code example. This one is simple and focuses on an ordering system where orders have line items. Line items have SKUs and prices. In domain-driven development, we often speak of aggregates; an aggregate root is like an Active Record model. Any aggregates under that root often do not make sense on their own, creating a tree-like structure. For example, an order cannot exist without the line items tied to it.
00:19:10.380
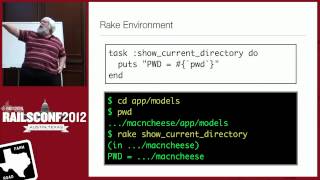
Below, we initialize an order with an order ID. It's essential to do this because, when you're playing back events, all these need tying back to an aggregate root ID. You cannot allow the database to generate your IDs; that needs to be managed at your end. Many people utilize grid systems for that purpose. The line items, similarly related to the order, have SKUs and prices.
00:20:49.180
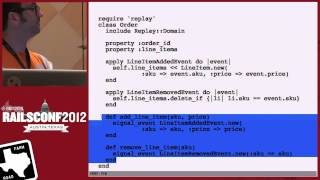
Regarding events, we have several plain Ruby objects. For example, the line item added event takes an SKU, a price, and the time added. The same applies to the initializer for those items, while the line item removed event only needs the SKU. This allows the system to remove the line item matching the SKU provided. The application of events is crucial. We take an event, store it, and serialize it, which is a significant process in event sourcing.
00:21:20.890
In this case, we're utilizing Redis as a storage mechanism. While the initialization code isn't included, it's fairly straightforward. We push it to a key based on the order ID, storing the serialized event as a string. We simplify the naive application of events by using a series of if-else statements to take action based on those events.
00:22:46.190
The fascinating aspect of rebuilding is that if I have an object and wish to reconstruct it, I’ll retrieve the entire history of events. This forms an ordered list in Redis—the events are captured in the order they arrived. I simply map these back to their event objects and reapply each object one after the other. Notably, there is no decision-making here; the event simply occurred, representing a point of truth. We are not permitted to alter history.
00:23:36.610
This simplicity allows for quick cycling through the events to reconstitute the object, as we don’t need to save the object in between applications.
00:24:09.700
Now, when we implement this into action, we create an order and add three line items, calculating the order total. Then we remove an item and print the total again before rebuilding the object. In this way, the first time with three items yields an order total of six, with two items reducing it to four after we’ve removed the second item. When we rebuild it, we again see the final four dollar total. The logic remains straightforward.
00:25:37.300
Replay is a gem I’ve been developing for some time that streamlines the event-sourcing process. It handles event storage and how those events are applied back to your domain models. Additionally, it offers a straightforward way for other objects to listen for those events. This is useful whether you engage in event sourcing or simply utilize events.
00:26:42.700
Replay is also beneficial in a CQRS architecture, which we haven’t yet discussed; I will touch on it briefly in a few slides. Using Replay is simple: you just require the gem and include the replay module within your pure Ruby object. Notice that it neither inherits from Active Record nor uses Sequel. There’s no Active Record involvement; this is only plain Ruby. Where we previously utilized if-else processing, we can now work with application blocks, specifying which class we are interested in applying with respect to certain events.
00:27:54.170
In our code, we continue to have commands that make a create action for the new line item event, applying it directly to itself. The event applications become enshrined as inherent points of truth—essentially the crux of rebuilding work. To break it down, when I signal an event, it allows the storage of that event and prompts the listeners for the events in the aggregate.
00:28:52.220
The notion of DCI stands for data context interaction. Has anyone here heard of DCI before? That's good to see. Some ideas originate more from the enterprise world and have recently made their way into the Ruby landscape, which we weren’t exposed to before. DCI still hasn’t gained significant traction, but notions like domain-driven design and CQRS have been discussed more frequently of late.
00:29:47.090
The new approach separates data models from the contexts in which they are used—allowing data to be utilized in a specific context via defined roles that dictate the actions or commands. For example, an order has its line items and identifies as an order ID. The respective role defines the methods for completing that order, which effectively segments domain behavior from domain data. In Ruby, we customarily mix these two, either through instance segmentation or employing a composition method to integrate roles at runtime.
00:31:53.580
The CQRS design pattern promotes command/query separation. Its main premise holds that a method should either return a value, thus acting as a query, or it should mutate state, functioning as a command. It’s a matter of not mixing the two, keeping the single responsibility principle in the forefront. CQRS, in particular, stands for Command Query Responsibility Segregation. This concept helps further conceptual development within our event sourcing discussions.
00:32:58.110
In a CQRS architecture, we maintain application state through our main models, integrating event sourcing, while distinct read models serve pivotal use cases or reporting needs. Various command objects may also be utilized to streamline command functionality away from direct call instances, facilitating event generation that influences state while providing similar advantages in asynchronous distributed systems. These events serve to manage the commands, akin to delivering nuanced system responsiveness.
00:34:43.610
Eventually, the concern over event sourcing becomes prominent; practicality flattens complications and better enables compositional construction. Migration fluidity connects the two through the facilitated interactions, ensuring robust functionality while instilling confidence in maintenance practices. Problems regarding migration are prevalent, yet the clarity of actions perpetuates structural integrity, reinforcing the enduring benefits of event sourcing's purity. More frequently, deeper dives into event sourcing literature can expose fundamental mechanics that produce favorable outcomes.
00:37:53.650
In the practical context of development, it becomes salient to persist essential structural design over the multiplicity of code versions, permitting easy access to foundational building blocks with proven histories. Event sourcing becomes hard when understanding contextual interactions between varied read/write states retains pivotal importance in application architectures, further exposing significant performance gains.
00:38:08.460
Overall, event sourcing provides a structured methodology that not only enhances the methodological foundations of data complexity but even resituates the behaviors that dictate application environments. Engaging those structures works toward goal-oriented practices concerning major development points and internal data management, driving ambition through multidimensional analyses tailored for domain-driven success.
00:50:00.000
Thank you for listening. Any questions at this time? Sure, let’s continue with the discussion regarding systems I've engaged in for event sourcing and whether I've utilized databases tailored to specific query requirements. The answer is mixed; I have explored those pathways, and it indeed has simplified things in many capacities. As you can see, event sourcing requires in-depth structural analysis for comprehensibility.