00:00:11.960
I'm Colin Kelley, CTO and co-founder of OFA. And I'm Dan Kozlowski, a software engineer.
00:00:17.359
Over the last two years, I've spent my time working on highly performant APIs in Ruby. High performance and Ruby typically aren't phrases you often hear in the same sentence.
00:00:24.359
However, we've had enormous success using Ruby without sacrificing the ease of coding with that language.
00:00:31.039
Before we dive deeper into the details, I'd like to provide some background on the API we needed to scale. It's called the ROL API.
00:00:42.520
The ROL API allows you to track calls in a manner similar to how you track a web click. You pass us a unique set of parameters, and we provide you with a unique phone number.
00:00:55.600
If that phone number gets called, it shows up in our recording, allowing you to make more intelligent decisions about where to allocate your marketing budget.
00:01:07.400
A ring pool is a collection of phone numbers. Customers can have multiple ring pools, usually tied to specific marketing campaigns, with each pool containing between two and five hundred numbers.
00:01:19.720
To protect the validity of call attribution, we reserve a phone number for a preset period after each allocation. This requires careful architectural consideration.
00:01:31.040
There are times when a customer requests a number against a ring pool that doesn't have any available numbers, as they may all be locked out.
00:01:42.119
To ensure that we always have a number available, each ring pool has an overflow number that we can provide if no other numbers are available. We do not track call attribution data with this number.
00:01:54.000
In extreme situations, we've seen these overflow numbers handed out several hundred times a second, making correlation nearly impossible.
00:02:06.039
About two years ago, a client approached us with a need for the ROL API, but with much higher throughput requirements than our existing Rails stack could support.
00:02:20.439
Our old Rails API could manage about five requests per second per connection, providing one phone number for each request.
00:02:31.280
The round trip 90th percentile response time was about 350 milliseconds. In contrast, the client wanted to handle at least thirty requests per second per connection.
00:02:44.879
They required at least forty phone number allocations per request, and aimed for a total round trip response time of less than 200 milliseconds at the 90th percentile.
00:02:56.760
This translates to an 8,000-fold increase in throughput just for a single customer.
00:03:10.440
The requirements were clear: we needed predictable low latency and elastic scalability as we added more users to the network. Additionally, we wanted to leverage our existing API.
00:03:24.200
We knew that the new system had to communicate with the old system synchronously, and eventually, we aimed to share business logic from our main app with this new API.
00:03:42.760
Bonus points if we could find a solution that was built in Ruby. Ruby has a lot of advantages, but there are considerations to address for highly performant applications.
00:03:56.760
One major concern we faced was due to the Global Interpreter Lock (GIL) since we were using the MRI interpreter. For most dynamic languages, this is like an elephant in the room.
00:04:05.959
It's worth noting that neither JRuby nor Rubinius interpreters implement a GIL, and therefore do not have this issue. However, GIL is still a challenge for most of us.
00:04:19.680
In short, the GIL is a wrapper placed around every Ruby statement that prevents a process from using more than one CPU. While this simplifies the interpreter's design and avoids data consistency issues, it also means we can't run truly parallel applications.
00:04:32.320
In an ideal world, your CPU usage would be evenly distributed across all available CPUs. However, with the GIL, one process can peg a core while others are idle.
00:04:42.560
To overcome this in MRI, we could run multiple cooperative Ruby processes, effectively sharding our API across cores.
00:04:56.400
The second issue we needed to tackle was known as the C10K problem: how can we efficiently handle 10,000 synchronous incoming requests?
00:05:10.880
We could write highly threaded Ruby code to address this, but that approach is complex and difficult to implement correctly.
00:05:25.280
Instead, we chose to use the reactor pattern to avoid that complexity. The gist of the reactor pattern is that whenever we write code that may block the main thread—like an HTTP request or database insert—we place an asynchronous call on the bottom of a queue.
00:05:39.400
The application then pulls the next action off the top of the queue and begins working on it. This allows us to select for events where blocking I/O has completed and run the relevant callbacks.
00:05:55.400
This method provides an optimal level of concurrency without the challenges of complex threading.
00:06:07.360
If you've seen Node.js, that's an example of the reactor pattern in action. In Python, the equivalent would be the Twisted library, and in Ruby, the reactor pattern library we're using is EventMachine.
00:06:17.119
This is an example of what a call to a remote API would look like in EventMachine. For any action we expect to block—like queries to Facebook—we define a callback for when the request succeeds and an error callback for when it fails.
00:06:29.240
One challenge we faced was that in many cases, callbacks and error callbacks were 80% similar, which complicated readability, writing, and testing of the code.
00:06:43.520
Unfortunately, this made our code incredibly brittle and nearly unintelligible. You can easily end up with a messy, spaghetti-like code structure.
00:06:54.280
Fortunately, because we were using Ruby, a better approach exists. Synchrony is a gem that runs on top of EventMachine, utilizing fibers introduced in Ruby 1.9 to simplify writing asynchronous code.
00:07:06.319
Instead of relying heavily on callbacks, when a method blocks, the reactor’s state is stored in the fiber. The reactor can then move on to the next event.
00:07:19.320
When the method unblocks, the reactor resumes the process from the saved state. Synchrony handles all the complex backend processes, allowing us to code linearly without the risk of arbitrary interruptions.
00:07:35.560
This pattern of scheduling applications using fibers is familiar to those who have worked with goroutines in Go.
00:07:48.720
So, instead of potential confusion, our code becomes clearer and more manageable by wrapping blocking code in fibers, with Synchrony handling the rest.
00:08:00.680
Our Goliath API is a Ruby web server that leverages EventMachine and Synchrony. It handles each incoming request as a separate fiber.
00:08:13.680
All asynchronous I/O operations will transparently suspend and later resume, relieving us of the heavy lifting.
00:08:24.520
You define a response method that takes a single argument, through which Goliath provides all the request data. You perform the necessary actions and return the result to the client as an HTTP response.
00:08:37.120
In this response, position zero is the status code, which in this case is 200, position one is the headers (if any), and position two is the body of the response.
00:08:46.720
By utilizing EventMachine and Synchrony, we were able to construct a high-performing system. Now, Colin will illustrate the differences between threaded and reactive pattern Ruby code, and discuss the effective software design decisions we made in Synchrony.
00:09:04.600
Are you all ready to see some code?
00:09:20.840
We named all of our conference rooms after fish—our fish bowl conference room has all glass walls, so it's quite interesting.
00:09:31.950
At the base level, I have a very simple web app that counts— it just counts. Here’s the threaded version of the code. I’ve written thread code to recognize increments, with a state variable tracking the counter.
00:09:49.080
The increment method runs inside a mutex, and there's a special case to handle shutdown. Here’s the counter itself; when you want to retrieve it, you also grab the mutex to get a safe copy.
00:10:04.960
When I kick off the run method, it creates a thread that increments the counter until stopped.
00:10:17.120
Now comparing the threaded version; I effectively deleted a quarter of the code, as you won’t be interrupted asynchronously.
00:10:26.640
Therefore, the code becomes significantly simpler to reason about. The only difference is using Fiber.new instead of Thread.new.
00:10:35.720
This modification enables asynchronous processing while being easier to manage since fibers run immediately when called.
00:10:47.680
However, because this is a CPU-bound application, I needed to yield periodically. It is rare to handle large CPU chunks, but with cooperative code, you do need to cooperate.
00:10:59.840
So, I decided to yield every 100,000 increments. Below is the actual Goliath app code, which will also be available on GitHub.
00:11:08.480
This server inherits from Goliath's API. We set up the counter object, run the counter, and this is the core of the web server.
00:11:18.640
Every request lands here, where we handle various URL paths. The SL counter returns a JSON response.
00:11:27.640
If you're connected to a load balancer, we have a way to check if we're active, and we also have a simple 404 handler.
00:11:39.840
For more complex tasks, we could also use Async Sinatra. There's a bit of boilerplate to get Goliath up and running; let's fire this thing up.
00:11:51.200
In one terminal window, I will run the threaded version.
00:11:59.280
In another terminal window, I’ll run the evented version and give the threaded app a head start. Both applications started at zero.
00:12:18.080
You can see the speed; the evented one is more than twice as fast because it is not dealing with mutexes or asynchronous interruptions.
00:12:31.280
If you look closely, you may notice that the numbers always increment in multiples of 100,000. This is expected behavior due to cooperative multi-threading.
00:12:42.560
It can only serve my SL counter action whenever the fiber yields. The demo illustrates that the performance of the evented version exceeds the threaded one.
00:12:54.720
I estimate a more typical performance would yield around 1.5 times better than a standard threaded application.
00:13:07.000
Now, let's discuss some of the software design decisions that significantly contributed to our API's success.
00:13:16.400
To start with, Synchrony supports many popular Active Record stores, including MySQL, MySQL2, and Postgres.
00:13:30.399
There are also many third-party drivers available. Typically, integration is simple, although the biggest issue we encountered was managing dependencies.
00:13:37.240
When we integrated Active Record, the autoloader and Rails encouraged dependencies between models. For instance, if I referenced the user model, it would pull in that model along with its dependencies.
00:13:56.160
To manage this, we spent considerable time reducing dependencies, and ultimately disabled the autoloader to only pull in the necessary models.
00:14:10.400
Active Record can be quite slow, as loading objects and handling validations or callbacks can become costly.
00:14:23.680
As a short summary, we found that using thin models with few dependencies and validations was the best approach.
00:14:32.960
We also realized the importance of encapsulating exception handling. So we developed a gem called Exceptional Synchrony to handle exceptions more systematically.
00:14:47.240
This gem consists of a couple of features, with the most crucial one being the ability to propagate exceptions across calls.
00:14:53.999
We created a proxy that sits in front of the event machine methods, which helps ensure that exceptions do not escape the fiber.
00:15:05.920
Here's how we manage callback exceptions. This is a straight EventMachine example—a callback and an error callback share the same connection closure code.
00:15:18.480
Although this code structure is common, it leads to redundancy, which is not ideal. Ruby provides a useful method for out-of-band exception handling through raise and rescue.
00:15:31.000
Synchrony provides a cleaner approach; it allows you to manage results without defining separate callbacks for success or failure.
00:15:41.360
We realized we could tunnel exceptions through calls, avoiding the need for separate error handling. The insure callback method was designed to streamline this process.
00:15:57.360
The method calls a simple private method that retrieves either the return value or the exception, handling both gracefully during execution.
00:16:09.680
With this change in our design, we returned to a more straightforward implementation without compromising on functionality.
00:16:23.320
During testing, we found that we could unit test these functionalities without reliance on the complex machinery behind the scenes, further simplifying our development process.
00:16:39.360
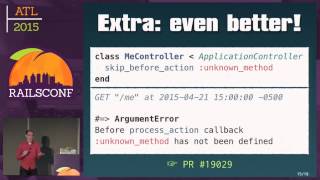
To highlight exception handling during fiber calls, if an exception occurs while a fiber is executing, it can cause the process to exit, which certainly presents challenges.
00:16:53.760
We learned this the hard way, as some processes would crash due to unhandled exceptions, leading to unstable server performance.
00:17:07.760
To combat this, we developed a simple layer that rescues errors in the EventMachine methods and logs them instead of propagating them.
00:17:20.760
This approach secures our application while providing meaningful diagnostic logging.
00:17:30.720
We also took care to prevent rescuing critical errors that would lead to server instability while also protecting against minor issues that could cause a stop.
00:17:46.080
The EventMachine proxy wraps these calls elegantly, allowing fine-grained control over error handling.
00:17:58.720
One of the final considerations I want to address is parallelism. While EventMachine simplifies writing concurrent serial code, it can become challenging to deal with parallelism.
00:18:10.000
We needed to be particular about how we coded our parallel tasks. Here’s the core of our API's scatter-gather mechanism—it begins with some parallelism.
00:18:25.040
The responses are stored as we kick off a parallel process to handle interactions with other shards. Once that block finishes, you gather all results to form your response.
00:18:39.040
This functionality should ideally follow the future promises pattern. We are currently exploring approaches to enhance this further.
00:18:51.440
Regarding the last line of code here, it's a simple Ruby object we can utilize. These are called immutable value classes—simple Ruby objects replacing the use of strings or hashes.
00:19:06.080
We've found it particularly useful to enforce design contracts without allowing for mutations aimed towards external interactions.
00:19:20.160
These immutable classes lend themselves well to rigorous testing as they do not internalize state changes and are predictable in their behavior.
00:19:34.080
These constructs fostered better organization since the majority of our code now exists in these immutable objects, easing the coding process.
00:19:48.080
Additionally, we established guidelines steering us toward plain old Ruby objects that naturally facilitated smaller, modular units of code.
00:20:02.080
Thus, we avoided cluttering our models with complexities, resulting in cleaner and more maintainable code.
00:20:14.960
The last piece I want to cover is related to Singleton implementations. I don’t refer to the typical class-based method but rather focus on the global variable style.
00:20:28.240
In summary, global variables are challenging—they cannot control their lifecycle, cannot accept constructor parameters, and are difficult to test.
00:20:39.679
Singletons may proliferate, compounding the complexity. We adopted a modified singleton pattern. This design allows specific dependencies to be made explicit.
00:20:52.639
After developing the code with this approach, we found ourselves needing two secrets files, which the modified pattern accommodated seamlessly.
00:21:05.440
The class also includes methods to set a global instance and retrieve it, combining convenience while ensuring flexibility in usage.
00:21:19.840
Heading back to our earlier discussion, we learned essential lessons about architecting large concurrent systems in the cloud.
00:21:36.480
The first lesson involved TCP connection establishment. Each time a TCP connection is formed, a handshake determines bandwidth.
00:21:50.720
Typically, this handshake takes about 20 milliseconds. Under HTTP 1.0, every request requires a new connection, thus repeatedly incurring latency.
00:22:05.360
This was detrimental to our SLAs as the delays would accumulate for each request. Fortunately, HTTP 1.1 introduced persistent connections, allowing requests to be pipelined.
00:22:19.040
In this setup, the handshake is executed only once and the connection is maintained as needed, substantially reducing latency.
00:22:35.040
We utilized HTTP 1.1 persistent connections for efficient communication within our shards. Furthermore, by utilizing domain sockets, we enhanced communication on the same server.
00:22:48.720
However, we encountered challenges with Amazon's Elastic Load Balancers (ELB), which could only forward requests to a single port per server.
00:23:04.360
To resolve this, we deployed a proxy instance on each API server to handle round robin requests to the individual shard processes.
00:23:18.679
Our EC2 setup consisted of an ELB that distributed requests to the API proxy instances, which also managed local shard distribution.
00:23:34.240
Each shard can send requests to other shards for ring pools they don’t own, consolidating responses into a single JSON body.
00:23:50.720
The API sharding method helps balance load and allows for flexible adjustments when traffic deviates.
00:24:03.439
What happens when a shard fails to respond? Initially, we set up a watchdog system to react quickly when shards stop responding.
00:24:15.680
However, monitoring the watchdog became cumbersome. Instead, we taught each shard to know the overflow number for every ring pool.
00:24:28.479
If a shard is slow to respond, we can simply return the overflow number while also rate limiting shard communications.
00:24:41.600
Over time, shards that observe another shard's slow response can gradually allow more requests while handing out overflow numbers.
00:24:56.840
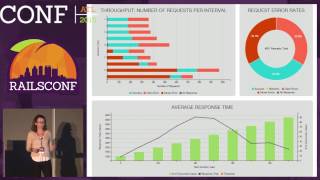
We leveraged JMeter for thorough load testing, using three JMeter instances to hammer our API repeatedly. This setup led to impressive results.
00:25:12.679
At one point, we recorded a median response time of 93 milliseconds, reaching 400 requests per second, showing our throughput had improved.
00:25:30.080
With four JMeter instances, we were able to achieve a median of 102 milliseconds for 1,700 requests per second. Our throughput peaked at 2,000 requests per second.
00:25:47.600
Interestingly, our bottleneck wasn't the number of requests hitting the API but rather JMeter's capacity itself.
00:26:01.000
We discovered that using AWS's Direct Connect could have significantly improved performance by ensuring that data traverses a private backbone.
00:26:14.800
Ultimately, the performance far exceeded our Service Level Agreements (SLAs). It's worth noting that there are 5.5 billion phone numbers in North America.
00:26:27.280
At our throughput rate, we could allocate every North American phone number in under 12 hours.
00:26:38.480
This accomplishment was a tremendous success, and we were very pleased with the results.
00:26:48.640
Some other tools we utilized include Minitest for testing and FactoryGirl for test object creation. Our entire test suite runs in under 10 seconds.
00:27:01.840
Our code coverage is at a staggering 99.96%, ensuring we are thorough with our tests.
00:27:15.440
As mentioned earlier, we utilized Apache JMeter for load testing, which proved exceptionally convenient for creating complex test scenarios.
00:27:31.440
We are grateful for the maintainers of EventMachine and Synchrony. A big shoutout to the communities on IRC who supported us.
00:27:45.679
We appreciate the efforts from GitHub collaborators and the contributions from Sandy Metz, whose best practices influenced our project.
00:28:01.679
As a call to action, I encourage you all to explore Goliath as a stack for your next mixed API server. If you have questions, please reach out on Twitter. I'm excited to help you.
00:28:14.480
I believe this stack holds tremendous potential, and I'd love to see a version integrated into Rails itself.
00:28:27.679
It was proposed as an idea back in 2011, although it didn’t materialize. Given the recent discussions around EventMachine being included in Rails 5, I would love to see Synchrony added as well.
00:28:42.000
I intend to contribute to that project and help guide it in that direction. The combination of these technologies could greatly increase performance.
00:28:53.080
Let's take advantage of shared advances in technology so we can build applications more efficiently and take latitude away from competing stacks, like Node.js.
00:29:05.440
Thank you for attending. That brings us to the end of this presentation.