00:00:11.599
Alrighty, so welcome to the Data and Analytics track here at RailsConf. I'm Barrett Clark, and we're going to talk about making data dance.
00:00:25.140
You might think of this as hard-hitting, heretical anti-patterns for fun and profit. I'm excited to see so many people here in the audience who also want to play with data or are excited about data. I'm super excited about data, and I promise you this is a bold claim: there will be at least one nugget in this whole mess that you'll be able to take and use.
00:01:05.030
A little bit about me: this is essentially my resume over the last 15 or so years. I started my journey long ago, but I spent quite some time at AOL in a market research group. In production, we used Berkeley DB—yes, really—Informix, Sybase, two versions of Sybase, MySQL, PostgreSQL, and SQL Server. We did most of the last four with Rails, which was super exciting.
00:01:21.560
Then I went to GeoForce, an asset tracking company that primarily operates within the oil and gas sector, dealing a lot with geo data. It’s really interesting stuff, as we used PostgreSQL, PostGIS, and Redis there. Right now, I'm at Saber Labs, where I've been for two and a half years. We’re an emerging tech incubator within Saber.
00:02:02.700
Many of you might not have heard of Saber, but if you know the brand Travelocity, we just sold that, so I no longer have anything to do with it. We use PostgreSQL for GIS work, PostGIS, usually Redis, and occasionally MySQL. What do all these things have in common? Well, I've seen a lot of data—really interesting data—and a lot of it. Generally, I've played with it using Ruby, and usually, I've worked with Rails, though not always.
00:02:36.180
This talk is based on a series of blog posts I wrote a while back, and Postgres Weekly, the weekly newsletter, picked up some of them. I'm super excited about data! Active Record is great; it handles most of your data access needs and is a fantastic place to start. However, I maintain that you're going to eventually outgrow it, and you may even outgrow Rails—at least in its monolithic form—whatever we’re calling that now.
00:03:38.940
That said, Rails is still our go-to tool in the lab, especially when we need to build a back-end. But this isn't a talk about Active Record; it's about raw SQL. When it comes to raw SQL, we can build complicated joins, and while you can perform joins in Active Record with scopes, it can get kind of messy. Often, rather than figuring out how all these pieces fit together, I prefer to just write the query.
00:04:31.320
Active Record maps all your CRUD operations and that’s great, but if I want to use something in the database that’s a bit more powerful or complex, I’ll dig into SQL. If I'm going to do PostGIS work, the RGeo gem is fantastic, but I already know PostGIS functions, and I would rather write the queries directly than learn a new API.
00:05:09.000
Now, I know you’re thinking: 'What about database portability?' Raise your hand if you’ve ever changed databases in an established project. Fantastic! How about in the last year? Some of you know, it doesn’t work like that. Database portability is often a pipe dream. I’ve done it a handful of times, and it really sucks. It’s not just the queries; even the data types differ. Even with a really cool Postgres script, you often have to do a lot of work to migrate the data. That takes a considerable amount of effort.
00:06:07.620
We switched versions of Sybase once—within the same database—and even that was a lot of work; we prepared, migrated the data, tested everything, and it was fine, but we still spent a month fighting fires. So I say, if you've chosen the PostgreSQL database for a reason, let’s use it.
00:06:30.540
The more you put on the database, the more it can become a single point of failure. Pay attention to your connections, your connection pool, and concurrent connections. If you have a query that takes longer than 500 milliseconds, you’re doing it wrong; something is amiss. A half a second is a significant amount of time in the database, and we will discuss strategies for improvement. Also, be sure to benchmark your queries against production data because they will operate quite differently in your local dev setup with a couple hundred records compared to your production database with millions of records.
00:07:44.289
Now, let’s get our hands dirty with window functions, which will serve as the foundation for today's discussion. Has anybody here played with window functions in PostgreSQL or Oracle? Great! A few of you know that this is really cool stuff. The documentation states that a window function performs a calculation across a set of table rows that are somehow related to the current row.
00:08:08.139
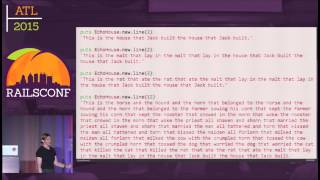
Let’s simplify that: you’re going to fold data from other rows into the current row. There are probably a dozen, maybe more, window functions, but the five I like most are lead, lag, first value, last value, and row number. Let’s look at some sampled data to illustrate these functions.
00:08:51.670
We'll begin with lead and lag, where we take the lead ID and the lag ID for fruits. Note that the parentheses define the window. We are simply saying the table is the window, allowing us to retrieve the next ID and the previous ID for the given row. For the first row, the next ID is 2, and there is no previous ID, so it returns as null. For the last row, there is no next ID.
00:09:49.399
Now, we need to define a partition for fruit. We’ll partition by the value of the fruit and order it by ID so that all occurrences of similar fruits are gathered together. The first value of the ID across the fruits will yield different results for Apple, Banana, and Pear.
00:10:17.329
When we check the last value, we see similar variations. Now we can enhance our dataset by rounding out the list with a row number, which shows each row's position within its window. Each window function gets its own defined partition, allowing you to treat them differently.
00:10:51.700
Let’s look at a practical example: we’re going to make a chat app. Here, you see we have some messages and a couple of different rooms. We want to make this app behave like your messaging app on your phone. We won’t call out the person’s name with every message, so we need a way to manage the display of that.
00:11:40.510
We could extract all the data and loop through it in the client, but that’s a lot of work; instead, we let the database tell us what the next ID is, breaking the data down by room and ordering it by message ID. This helps us avoid redundantly displaying the sender's name when a user sends multiple consecutive messages in a chat.
00:12:54.880
As a nifty pro tip, you can use positional field numbers in your order-by clause, especially when you have a calculated field like a window function or a count. This allows for cleaner and more efficient queries.
00:13:59.650
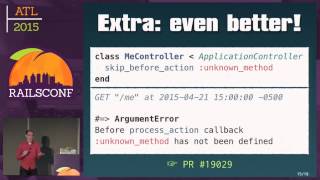
Now, let’s discuss how to execute this raw SQL in Rails. One approach is to use Active Record, where you dynamically execute raw SQL using base connection. In doing this, you can have a calculated field in your query that may not show up when you inspect the object, as the class isn't aware of it.
00:14:22.640
Some might find this approach a bit odd or uncomfortable, as it comes off as an anti-pattern; however, you don’t have to use Active Record if you're uncomfortable. You can employ the PG gem directly, or even interact with a database using plain Ruby.
00:14:55.480
You can address queries to databases with plain Ruby, which might look something like this: with Active Record, you get an array of message objects, but with PG gem, you'll receive an array of field values, providing you with a more straightforward structure.
00:15:44.520
Models don’t need to rely on Active Record, and you don’t have to inherit from it. You can simply implement business logic in a class and call it a model. This allows you to answer specific questions, such as when did something change, or how long certain events lasted.
00:16:10.760
We can capture entering and exiting events and fill out all transactional data. However, to effectively answer these questions, we require more sophisticated queries, which is where sub-queries play a critical role.
00:17:35.230
Sub-queries allow you to filter and group queries. You can wrap a query with an outer query to filter it and gain additional insights. For instance, we are looking at data collected from Bluetooth beacons to see how a phone moves within the monitored area.
00:18:19.350
We will partition the data by phone, ensuring each phone's readings are in order by timestamp. Subsequently, we can ask when certain readings change based on this data. The results will help us visualize how people move around in a given environment.
00:19:17.700
To simplify our queries and make them easier to manage, we can use common table expressions (CTEs). CTEs allow us to create a name variable for the query, making it more readable and organized. With a proper CTE, we can build complex queries in a more manageable way.
00:19:58.290
Moreover, if you have a frequently used query, you might consider creating a view—this is simply stored queries that act like a read-only table. By defining a view, you avoid repeating yourself, making the code cleaner and easier to maintain.
00:20:46.210
However, it’s essential to understand that embedding business logic within your database can lead to complications. Therefore, it’s crucial to communicate with your team about where the code runs and the rationale behind those decisions.
00:21:24.250
If your query is slow, consider performing the heavy lifting in a separate process. This is where materialized views come into play. A materialized view allows you to store a pre-computed result of the query, which can then be indexed, significantly enhancing performance.
00:21:46.270
Materialized views require an occasional refresh to update the data. The newer versions of Postgres allow for concurrent updates, enabling you to refresh the view without locking the table and ensuring you have reasonably current data.
00:22:06.850
If you’re hosting on Heroku, you can set up simple rake tasks to refresh the materialized view as frequently as necessary. This ensures that you're working with the most up-to-date data, which is crucial for effective benchmarking and performance analysis.
00:22:28.780
Speaking of benchmarking, this is crucial for understanding how your queries perform against actual data. You might have security concerns about downloading production data locally, but if feasible, this can be very helpful for accurate testing.
00:23:41.300
Let's keep pushing forward! Sub-queries for field values allow you to do look-ahead queries, which are incredibly useful. For instance, determining exit events when a specific condition is met adds an interesting layer to data processing, effectively handling those edge scenarios with ease.
00:24:51.199
As we explore data types in PostgreSQL, consider using arrays or range data types, which can simplify various operations. Knowing how to leverage JSON data types can also be beneficial, as can using UUIDs for unique identifiers; these offer enhanced indexing and validation.
00:26:42.260
As for installation, installing PostgreSQL with PostGIS can be done via homebrew on macOS or through repositories on Linux. Alternatives such as Heroku provide a quick start with dependencies included.
00:27:46.670
Database tools are critical in interacting with PostgreSQL. GUI interfaces, especially PG Admin, help manage your database effectively. Learning about 'EXPLAIN ANALYZE' commands is also vital for tracing query performance and identifying hotspots.
00:29:19.530
To recap: it’s perfectly okay to write SQL. Just start writing it, and if it gets messy, consider refactoring through common table expressions or views. Materialized views come in handy for performance enhancement. Just remember—it’s about having the right tools available to you, and expanding your toolbox with these resources.
00:30:06.700
PostgreSQL is remarkable, and I continue to discover its fascinating capabilities. Thank you!