00:00:12.080
Thank you for sticking around to the end here. As the slide says, we're going to be talking about processing threads today, taking a look at Resque and Sidekiq.
00:00:19.039
I am James Dabbs, and you can follow me on Twitter, talk to me afterwards, or do those sorts of things.
00:00:25.640
Before we dive into these topics, I want to emphasize one point that I hope you take away from today.
00:00:32.960
I think we're all here because we want to improve our craft; we want to be better at writing code.
00:00:38.600
So, I want to start with a quote from one of the great writers in all of Southern history, William Faulkner, with a little advice on how to be a better writer: "Read, read, read, read everything—trash, classics, good and bad—and see how they do it."
00:00:44.559
So, my goal today is to help you understand a bit more about processes and threads, providing a general introduction to those concepts. But I want to do this by examining a couple of what I consider classics: the source code from Resque and Sidekiq, examining how they function, and why they are designed the way they are.
00:01:02.719
Let's jump right in. How many people in the room have used Resque or Sidekiq for something? Most people? Good.
00:01:08.080
For those of you who have, how many of you have actually looked at the source code? Relatively few? Awesome!
00:01:14.159
Okay, great. Really quickly, for folks unfamiliar with Resque and Sidekiq, here’s a rough idea: they're both background worker systems. The purpose of background worker systems is to offload some work from your Rails application into a background process that can run independently.
00:01:25.159
For example, when a user signs up for your website, you don’t want them to wait for you to send a welcome email before they see their welcome page. Instead, you send the welcome page back, and then throw a job into a queue that represents the task of sending that email.
00:01:37.960
Your worker processes will then handle that task.
00:01:43.000
In terms of architecture, you have a Rails app or a job or whatever that throws some work into a queuing system, while workers continuously pull from that queue and perform the tasks.
00:01:51.159
Resque and Sidekiq are two very popular solutions in this space. They both use Redis for their queuing system; in fact, they use the same compatible Redis interfaces, meaning you can queue jobs with Resque and Sidekiq interchangeably.
00:02:00.560
The key difference between them lies in how they manage processes and threads. That’s what we’ll be looking into today. Let’s start by talking about Resque. It was first developed at GitHub around 2009.
00:02:20.440
The problem they faced was that they had a ton of background jobs doing all sorts of tasks, and they were pushing every solution they tried to its breaking point.
00:02:31.799
At one point, they realized they needed to look at existing options. Essentially, there were a couple of hard problems. One was handling queuing, but Redis is a wonderful solution for that, so they decided to use it. This allowed them to focus on other things that mattered to them, particularly reliability and responsiveness.
00:02:56.840
This raises the big question: how are they going to achieve that? The answer was through the use of forking.
00:03:10.159
(My bad pun aside, please laugh.) Forking is a Unix system call that allows you to split off a currently running process.
00:03:16.879
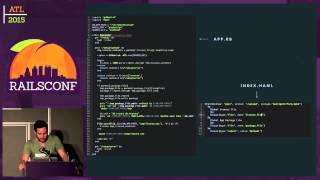
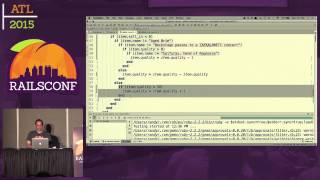
Let’s take a look at that. It’s easiest understood through an example. I will show you a simple log function.
00:03:31.799
Our script starts by assigning a variable, setting it to one, and then we fork.
00:03:38.560
Fork is interesting because it’s a call that is made once but returns twice: once in the existing process (the parent) and once in the newly created process (the child). In the parent process, it returns the ID of the child process, whereas in the child process, it returns zero.
00:03:51.519
So, the way to read this is the first block: we fork, inspect the return value of the fork, and assign it to P. If we got something back, then we’re in the parent process. The parent will print out that it’s waiting for the child to finish.
00:04:08.680
Once the child is done, the parent will print out that it's done with the fork and the value of variable A.
00:04:17.359
On the other hand, if we're in the child process, we print out the child's work, sleep for a second, increment A, and then exit.
00:04:30.760
If I run that and check the output, we'll see something interesting. The parent process waits for the child to finish executing before it exits.
00:04:47.199
The key takeaway here is that when the parent exits, it prints out that A is 1, even though the child process had access to the original version.
00:04:54.600
This is because the child process gets its own copy of the variable at the time of the fork, and updates made in the child do not propagate back to the parent.
00:05:06.680
That's an important distinction, and it’s crucial for understanding how Resque operates. Is this making sense? Feel free to ask questions anytime.
00:05:24.920
In this model, the process springs up, does its specific task, and then dies. Now, let’s dig into some actual code.
00:05:38.160
I've prepared a quick example for exploration. When I say 'read,' I mean 'explore'—we have much better tools for reading code than just opening a file and going line by line.
00:05:51.919
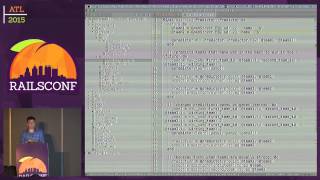
So, let's dive into the source. I’ve got a Pry job here that serves as a debugging tool. Our goal is to understand how a job, once queued, gets executed.
00:06:06.160
I’ll queue up a Pry job into Resque, and from there, I'll launch Resque to see what happens.
00:06:20.400
At some point during this Resque processing, a job gets pulled off the queue, and we halt execution to examine some internal state.
00:06:36.560
Utilizing Pry stack explorer, I can pinpoint the call stack for further investigation. Accordingly, the first mention relevant to my task is the Resque work task, which initiates a Resque worker.
00:06:52.760
This sets some environment variables and eventually invokes the worker's work method with a specific interval, which leads us to the most essential component of Resque.
00:07:04.960
The work function for a Resque worker operates in a long loop, checking whether it should shut down or continue processing.
00:07:16.560
If not shutting down, it reserves a job from the queue. This is a straightforward process that retrieves a job object from Redis.
00:07:25.160
Once a job is reserved, we fork. If we’re in the child process, we set up signal handlers, reconnect to Redis, and perform the job.
00:07:36.440
In the parent process, we just sit, wait for the child to finish its task, and do not perform any additional operations.
00:07:52.240
This loop continues, and ultimately, we get back to the performance of the job itself, which is where the core functionality lies.
00:08:09.680
As we step through, we see that the job represents the task retrieved from Redis, unpacking its payload and executing the required actions.
00:08:22.360
This perform method dictates how the job operates, allowing for execution and error handling as necessary.
00:08:34.920
This general structure explains how Resque accomplishes its task, facilitating straightforward processing for its jobs.
00:08:47.040
Now, with Resque, it has essentially a long loop that initializes signal handlers, grabs work, forks a child process, and that child process takes on the task, keeping the parent responsive.
00:09:04.760
One important question to consider is why we would want this architecture. Why choose this model over others?
00:09:20.440
The answer relates to process reloading. When a job misbehaves, forking allows it to run independently, and when it's done, it exits and cleans up the resources allocated during execution.
00:09:35.440
This architecture minimizes the risk of memory leaks, especially if jobs perform erratically; the child process handles this and keeps the parent from hanging, maintaining responsiveness.
00:09:55.320
In summary, Resque embodies the adaptability of forking for background job processing, offering a robust solution for handling tasks efficiently.
00:10:12.680
Now, onto Sidekiq. Why is Sidekiq a competing solution? It emerged explicitly as a reaction to challenges seen in Resque, with a primary concern being resource utilization.
00:10:30.600
Running multiple workers in Resque means potentially needing memory that scales with the number of processes launched.
00:10:46.240
In contrast, Sidekiq was designed to be memory-efficient while still robust, with multi-threading as its keystone.
00:11:02.000
However, the challenge with threads is that they share memory, leading to potential race conditions, which are quite tricky to debug.
00:11:20.080
For example, imagine a simple bank operation tracked by wallets: if you split processing between threads, two threads might act on the wallet balance simultaneously, leading to incorrect totals.
00:11:34.080
This non-deterministic behavior can create hard-to-track-down bugs, which makes thread safety a critical consideration.
00:11:46.080
To address these concerns, Sidekiq utilizes the Actor pattern, providing a more straightforward means to handle synchronization safely and effectively.
00:12:09.280
In this pattern, concepts like mutable state are encapsulated within actors, allowing separate threads to communicate without exposing shared state.
00:12:29.520
To illustrate this, consider a simple wallet class defined with properties controlled by Celluloid. The flexible use of this pattern allows sidekiq to handle concurrent connections.
00:12:46.960
Back on Sidekiq’s employment of its threading strategy, jobs are sourced and executed via an asynchronous task model utilizing the principles of the actor model.
00:13:05.760
As with Resque, Sidekiq processes jobs from a Redis queue, relying on worker classes tasked with data collection and execution in multi-threaded settings.
00:13:21.680
Once a job gets assigned to a processor, execution starts. Each thread interacts independently, pulling workloads and executing concurrently.
00:13:37.200
This parallelization enhances throughput and optimizes resource usage compared to Resque’s process-forking model, directly tackling memory constraints.
00:13:53.000
However, as with any system, care is needed to ensure consistent operation. For example, making synchronous calls from actor-based objects relies on mechanisms that handle message passing and responses.
00:14:08.520
To maintain integrity, when invoking operations, Sidekiq facilitates message-passing logic that allows threads to reliably exchange messages and data.
00:14:24.360
For example, a wallet object created with Celluloid allows for concurrent adjustments while avoiding race conditions.
00:14:39.560
This efficacious handling leads to efficient execution in multi-thread contexts, delivering upon performance expectations.
00:14:56.080
To view how jobs arrive at Sidekiq, we can inspect the source code closely, seeing processes initiated by their origins in Redis.
00:15:13.920
Every worker orchestrates its threading model thoughtfully, creating landscape and monitoring redundancies for each asynchronous job.
00:15:36.040
In conclusion, if you are memory-constrained and want a solution that efficiently performs without the increased load of additional processes, you should turn to Sidekiq.
00:15:54.880
If you need isolation for job execution with less focus on multi-threading, Resque remains an excellent option.
00:16:11.680
Ultimately, the choice between these two systems hinges on considerations of memory use, concurrency, and performance based on your unique application requirements.
00:16:27.360
Thank you for your time, and I hope you found this comparison between Resque and Sidekiq insightful!