00:00:11.390
Today, I will be talking about 'Resilient by Design'. I think the previous talk on microservices mentioned the CAP theorem and everything. This talk is like a sequel to that discussion.
00:00:19.380
Now that we want to build systems that don't go down, let me introduce myself. My name is Smit Shah, and I am part of the Bundler core team and a member of the Wondergole team. Until very recently, I maintained the dependency resolver and occasionally contributed to JRuby.
00:00:33.660
I currently work at Flipkart, an e-commerce website in India. We deal with a lot of scale and have numerous scaling problems. I am very thankful to them for sponsoring my trip here.
00:00:51.930
So, why do we actually care about resilience? Companies have increasingly depended on software over the years, and at this stage, any downtime can result in significant business losses.
00:01:02.190
For example, Flipkart makes over 1 billion dollars in sales. Even a single minute of downtime results in a loss of approximately two thousand dollars. Interestingly, downtime is not evenly distributed.
00:01:13.290
Twenty percent of the time may account for eighty percent of the total revenue. During those peak times, systems are most vulnerable. Consequently, experiencing downtime for just one minute could cost close to eight thousand dollars.
00:01:30.120
As such, companies cannot afford any downtime in their systems. What they do is rely heavily on developers and support engineers.
00:01:40.830
This is where the infamous on-call responsibilities come into play. It's up to the developers to respond to on-calls whenever necessary, be it late at night or otherwise, ensuring that systems are running smoothly.
00:01:54.990
Another reason we must consider resilience is that even the simplest systems today depend on other services. At the very least, they will rely on a database located on another server. As mentioned in the previous talk, networks are not entirely reliable.
00:02:21.720
In such scenarios, focusing on resilience is essential. I don’t think any of us enjoy handling on-calls over the weekend; that tends to be quite frustrating.
00:02:39.300
So, how do we actually build a resilient system? In the 90s, resilience testing was often an implicit requirement. The expectation was that your code should run and function correctly, but specific requirements, like maintainability, were not explicitly stated.
00:03:02.720
In the Ruby community, however, there is a significant focus on testing, code quality, and maintainability. With resilience, today's expectations have become more elusive. Management expects systems to be up all the time.
00:03:18.740
Developers assume that if they've built a system using a certain data store, it will remain operational. But if there is no thought put into resilience while designing the system, developers will be quite fortunate to identify and address bugs before going into production.
00:03:44.700
Most instances revealing system resilience issues occur under peak load conditions, which means if resilience has not been considered, problems can arise at the worst possible time.
00:04:06.710
In addition to thinking about code resilience, there's also human bias to consider. We often focus only on positive outcomes, where everything is functioning correctly, like caching servers and databases responding properly.
00:04:23.810
Yet, we fail to adequately prepare for scenarios where these components do not work as expected. To combat this, we must think about resilience from the outset.
00:04:47.720
Every time we design a system, we need to consider what will happen if something goes wrong. For instance, do we have a plan for what happens if the caching servers fail? Are they highly available?
00:05:06.710
These considerations should be integrated from the outset. This talk focuses on resilient design patterns, but I want to clarify that these are not silver bullets. Using all these patterns does not guarantee that your system will never go down.
00:05:32.060
Many factors influence system resilience, including the specific domain of the system being built. For instance, on the Flipkart website, our primary goal is to ensure that customers can view product pages and that they receive their orders after clicking to buy.
00:05:58.240
If our recommendation system encounters issues, we can still load the product page without it. If certain comments or reviews are not displaying due to system downtime, we can choose not to show them. Each service has its own set of trade-offs that must be considered.
00:06:31.740
For example, Netflix, if their bookmarking service goes down, won't allow users to resume playback. They will simply restart the video, as the primary objective is for users to be able to watch videos seamlessly.
00:06:53.440
The key takeaway is that resilience depends on your domain and system design. There are no free lunches when designing a system. You must think critically about potential failure scenarios.
00:07:09.100
Now, let's discuss some essential patterns. I believe the most crucial pattern in building resilient systems is the concept of failing fast. This is why I am presenting it first.
00:07:27.940
The most significant waste of resources occurs when processes are slow, and other services do not respond timely. Failing fast is the best course of action when another service you are interacting with fails.
00:07:40.000
The rationale behind failing fast has roots in queueing theory. John Little's law indicates that the length of a queue, that is, the number of pending messages, depends on two factors: the arrival rate and the time taken to process those messages.
00:08:03.950
If the response time of a service increases, the time those requests spend in the system also increases, leading to a larger queue size. In this context, if you're communicating with a service that isn't responsive, and you leave the default timeout of 60 seconds set, it will take your system 60 seconds to realize it's failed.
00:08:23.170
This extended response time will cause your queue size to grow, negatively impacting your system's overall performance.
00:08:40.000
Once you've optimized your code to minimize response times, if the utilization exceeds eighty percent, it can lead to significant performance degradation in your system.
00:08:49.500
At this point, capacity planning becomes crucial, based on your utilization statistics. This understanding illustrates the direct link between responsiveness and resource management.
00:09:05.370
When analyzing an eBook download service, consider the scenario where customers expect an SLA of five minutes to receive a download link after purchase. Every service involved must communicate seamlessly.
00:09:23.490
Assuming an external service begins failing, each payment call to that external service experiences a timeout, resulting in backlogged messages piling up in the queue.
00:09:33.900
Once the external service comes back online, a flood of queued messages will overwhelm the system, making it impossible to meet SLAs for both new and old orders.
00:09:54.580
This is where utilizing a circuit breaker pattern comes into play. By anticipating failures, we can queue problematic messages for later processing and maintain steady response times without increasing our reliance on failing services.
00:10:11.720
With proper circuit breaking and fallback mechanisms, newly placed orders can still meet the SLA, while old messages are processed later based on availability.
00:10:36.720
Now, let's talk about resource bounding, which is vital to maintaining the efficiency of your system. If there are unbounded resource accesses anywhere in your systems, that can lead to several issues.
00:10:55.719
For instance, using timeouts is essential, as the default library timeouts can sometimes be inadequate. An example is a library that defaults to a 60-second timeout, causing significant delays.
00:11:09.050
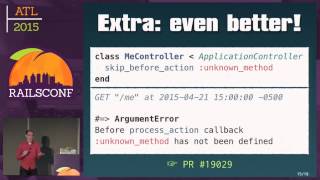
Some services never even timeout, which can lead to hanging or unresponsive states. It's crucial to analyze whether your application has appropriate timeouts in place to avoid such failures.
00:11:25.590
Timeouts are essential for fault isolation, helping shield your systems from external failures. Implementing retries in conjunction with circuit breakers can offer valuable safeguards in case of issues.
00:11:40.780
In addition to timeouts, consider limiting memory usage. Too often, developers overlook memory limits in shared caching services. For instance, services like Redis must have properly set limits to avoid resource exhaustion.
00:12:05.050
A real-world scenario involved a system where memory usage continuously climbed, driving it to start utilizing swap space, which severely impacted performance.
00:12:23.760
In this case, it turned out that one part of the code dealt with unique symbols, which filled memory continuously without proper clean-up. Implementing worker monitoring helped manage memory spikes effectively.
00:12:41.750
For CPU usage, limit processes like health checks that can unexpectedly consume resources. Utilizing control groups allows you to isolate poorly behaving processes without negatively affecting your core services.
00:12:55.890
Implicit queues or locks can lead to resource dead ends. Instead, use bounded queues like messaging systems that can help apply back pressure when nearing capacity.
00:13:26.300
Following up on patterns, one of the most powerful is the circuit breaker pattern. It acts as a safeguard between clients and servers.
00:13:45.590
Under optimal conditions, requests flow through without any issues. However, when requests time out, the circuit breaker monitors error rates, ultimately tripping when failures exceed a certain threshold.
00:14:02.110
In the case of a circuit tripped, future calls to the service are cut off entirely, allowing the service to recover without extensive load. After a recovery period, the circuit attempts to reconnect, determining if the service is still available.
00:14:15.490
If successful, the circuit closes, restoring normal operations. However, persistent failures keep the circuit open, requiring a continuous evaluation of the service.
00:14:23.950
The circuit breaker pattern is well-implemented in libraries like Semyon for Ruby or Hystrix for JRuby. Look into these frameworks for effective integration into your systems.
00:14:49.850
Next, let's examine the bulkhead pattern, which finds its origins in maritime practices. Bulkheads are watertight compartments in ships designed to contain water in case of hull damage, preventing total sinkage.
00:15:06.620
This concept translates well to services where ensuring a single service failure does not cascade and affect the entire system's stability. For example, a logistics service using product information should remain functional, even if the website experiences a surge in traffic.
00:15:24.830
Applying the bulkhead pattern effectively separates system components so that failures in one location do not lead to widespread service outages, mitigating the risk of cascading failures.
00:15:37.290
Lastly, it's essential to maintain a steady state in your systems. Achieving this requires minimal human intervention to keep things running smoothly.
00:16:05.050
Automating processes like log rotation is vital to avoid running out of disk space, which can halt all operations. Moreover, an unwritten archiving strategy should be established early on when designing your system.
00:16:23.370
Data archiving must be part of your design strategy to avoid challenges later on. Determining when to archive will greatly depend on the operational context of the data.
00:16:42.480
To conclude, I’d like to leave you with a thought from Michael T. Nygard's book, 'Release It', which offers insight into building resilient systems. He emphasizes the importance of understanding what your system should never do just as much as what it should do.
00:17:06.130
To build resilient systems, it's essential to proactively strive to fail fast, bound resources, implement timeouts, and integrate circuit breakers for reliability.
00:17:27.150
Consider employing bulkheads to isolate failures effectively and ensure that a single service failing doesn’t compromise overall system integrity. Thank you for your attention!