00:00:12.480
My talk is about scaling Rails at Shopify. This is a quick story of how we survived Black Friday and Cyber Monday last year and for the past few years. My name is Christian, and you can find me as cgrd on Twitter. If you haven't followed me, there's no point. I'm from Montreal, where for three months of the year, this is what my city looks like: cars buried in snow, people pushing buses, and occasional maple syrup heists.
00:00:55.840
There is probably the best reason to come to Montreal. I work at Shopify, a company that's trying to make commerce better for everyone. Our platform allows merchants to sell on multiple channels, primarily on what we call the web channel, which consists of websites. We give our merchants the ability to customize the HTML and CSS of their websites, and they also have access to Liquid, enabling them to fully customize the look and feel of their sites. We also have a point of sale system for brick-and-mortar stores and a mobile app for people on the go who want to accept payments.
00:01:30.960
Our stack is a pretty traditional Rails app. If you've seen John Duff's talk earlier, I might repeat a lot of things, but we're running Nginx, Unicorn, Rails 4, and Ruby 2.1. We're on the latest versions of everything except Ruby. We use MySQL and have around 100 app servers running in production, which accounts for roughly 2,000 Unicorn workers. We also have 20 job servers with around 1,500 Rescue workers.
00:02:24.640
So, what kind of scale are we talking about? While discussing scaling, I need to throw some big numbers at you; otherwise, this talk would be kind of useless. We have about 150,000 merchants on Shopify, as of last night's check, and these merchants account for around 400,000 requests per minute on average. However, we have seen peaks of up to a million requests per minute during flash sales. Last year, this amounted to processing approximately four billion dollars during those sales.
00:03:09.120
If you do the math, that’s around $7,000 per minute. So, any minute we are down, we are effectively burning money, and someone somewhere is losing money. Being in the commerce industry, we have to deal with really intense days that we call Black Friday and Cyber Monday. Black Friday is crazy, but we actually refer to Cyber Monday as 'Cyber Fun Day,' because when Black Friday goes well, we can just kick back and relax on Cyber Monday, believing it won't be any worse.
00:04:10.640
Last year, we saw around 600,000 requests per minute, almost double our average traffic on a normal day. We processed three times more money during those four days than on average, making it a crucial time for us where we can't afford any downtime. Everything has to go perfectly.
00:04:57.600
To understand better the decisions we make around scaling Shopify, it's important to recognize that each request occupies a Unicorn worker. To scale Shopify, we either need to reduce our response time or increase the number of workers available. I'm going to go through the various techniques we've implemented to reduce response times, and hopefully, you'll be able to apply some of this to your own applications.
00:05:34.720
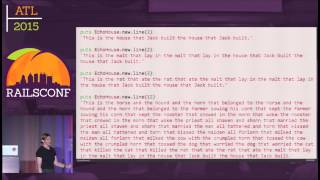
Our first line of defense is what we call page caching. The basic idea is that if 10,000 people hit the same page at the same time, chances are we are going to respond with the same content. It’s inefficient to perform all this computation 10,000 times for 10,000 requests to the same page. Instead, it would be efficient if we could do the computation once and serve the same data to everyone.
00:06:10.160
The challenge is that certain aspects of a page can vary—the number of items in a user's cart or whether a user is logged in, for example—so the page content won't always be identical. To address this, we created a gem called Cacheable, which is a generational caching system. This means we don’t have to manually clear the cache, which is notoriously difficult in computer science. The cache key is generated based on the data being cached.
00:06:51.440
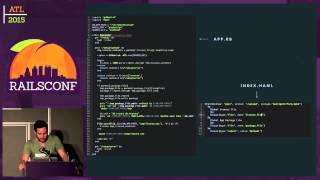
Here's a typical example using Cacheable: in this post controller with a simple index action, we scope the posts per shop because we are a multi-tenant application. We also implement pagination, wrapping the action in a method called response_cache that does the caching magic. We use a method called cache_key_data, which returns a string that we then hash to create the key for the cache, and we store the response as the value.
00:07:47.360
In a typical request, the shop ID is included along with other parameters, ensuring that cache keys vary according to the page being accessed. We also maintain a 'shop version' counter that increments whenever a post is updated, created, or deleted. If there’s a change, all cache entries with that shop version become invalid, prompting us to fill new cache keys.
00:08:30.320
Additionally, the library supports gzip compression for HTML cached in Memcache. When a request comes in, if we find a cache key in Memcache, we directly serve the resulting gzip data to the browser. This not only saves on bandwidth but allows for efficient data retrieval, minimizing load times. We also implement ETags and 304 Not Modified responses, ensuring that cached data remains accessible without unwarranted server requests.
00:09:22.640
In terms of performance metrics, we track cache hits versus misses and maintain a hit rate of about 60% with page caching, which is significant considering we handle up to 400,000 requests per minute. A downside to caching arises during sales when we frequently update inventory, which can render the cache less effective since modifications affect the shop version.
00:10:40.880
Our second line of defense is query caching. We process around 60,000 queries per second, generating considerable stress on our databases. To alleviate this, we utilize the Identity Cache gem, which marshals ActiveRecords and caches them directly into Memcache. When used effectively, we can avoid direct hits on MySQL for frequently accessed records.
00:11:36.480
Using Identity Cache is often by design, particularly in mission-critical areas like checkout processes where accuracy is paramount. Unlike generational caching, manual cache busting is necessary, and we employ an after-save callback to clean up cache keys. While rare, race conditions can occur, but we accept this trade-off for overall efficiency.
00:12:22.560
The implementation of identity cache allows us to create secondary indexes as well. Instead of solely relying on the product ID for lookups, we can also search by handles—efficiently mapping products within our database.
00:13:12.880
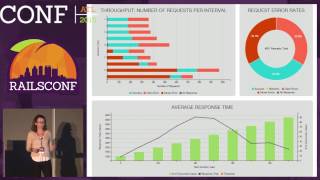
Let's look at some performance graphs illustrating cache hits and misses for identity cache. The hits are visibly dominant, indicating effective caching strategies. During flash sales, we experience no dips in cache performance, which is crucial for maintaining user engagement.
00:13:55.200
Another critical strategy we employ involves offloading tasks to background processes, particularly with payment gateways. Payment gateways can exhibit significant latency; if our Unicorn workers were to wait for long responses, it could severely hinder our service.
00:14:40.560
To tackle this, we background various tasks: webhooks, email sending, payment processing, and fraud analysis, allowing us to free up Unicorn workers and continue processing other requests. Furthermore, utilizing background jobs allows us to implement throttling, managing the number of concurrent jobs to optimize resources.
00:15:30.000
While we prepare to handle 600,000 requests per minute, regressions can occur. Monitoring is key; we utilize a tool called Shopify to measure performance across various metrics, which is crucial for our operational integrity. We rely on StatsD to collect and aggregate these metrics over time.
00:16:45.200
With StatsD, we can graph various performance indicators—this includes the 95th percentile render times for our Liquid templates. This understanding allows us to quickly identify regressions and operational bottlenecks through our health dashboard.
00:17:46.960
Despite all safeguards, regressions can still occur when we least expect them. Therefore, we conduct rigorous load testing using a tool called Genghis Khan, simulating high traffic conditions to evaluate our system's resilience. This tool mimics user behavior during peak traffic, effectively stress-testing our systems.
00:18:22.720
We conduct these tests several times a week, assuring us that we are ready to handle Black Friday and Cyber Monday traffic. Following this, it's essential to discuss how we employ MySQL effectively, particularly with slow queries that can arise.
00:19:04.960
Whether utilizing Nginx, which exposes unique request identifiers, or using Rails’ log process action to enrich request logs, we ensure to accurately track slow queries. This process has distinct steps that greatly enhance our capacity to diagnose issues.
00:19:40.240
To illustrate, by employing a gem called Marginalia, we can include controller and action names in our slow query logs. This additional context makes troubleshooting significantly more manageable by connecting slow query occurrences back to user requests.
00:20:27.680
As we build a Rails app, we need to understand the concept of resilience—how our application can continue operating even if individual components fail or slow down. Initially, we may have fragile dependencies through components like session stores or caching systems that we assume will always be available, but we must proactively build in fallbacks to ensure a robust architecture.
00:21:51.040
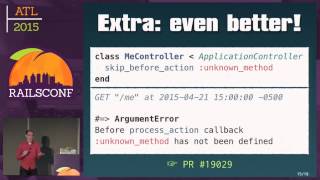
This can be achieved through rescue constructs in our code, handling instances where a component might not be available. Implementing these principles can help our application recover gracefully from dependency failures when properly orchestrated.
00:22:33.840
We have also developed a tool named ToxyProxy, which simulates service disruptions, optimizing our routing logic to ensure graceful degradation. By doing this within our testing environments, we can validate that our code will handle outages in an expected manner while preventing users from experiencing extensive downtimes.
00:23:27.040
In summary, we have taken strides to enhance our application resilience, ensuring that our users have an uninterrupted experience even when third-party services experience outages. The data-driven alerts we set up help uncover and address such situations in real time.
00:24:11.440
We are conscious of the various third-party dependencies we rely on and continuously aspire to develop failover mechanisms to safeguard our performance. This includes manual circuit breakers that we can engage during high traffic days, like Black Friday, ensuring smooth service for those merchants not using affected systems.
00:25:10.880
As one final point, while we achieve strong performance metrics, unforeseen complications can arise that we constantly mitigate through monitoring tools and proactive approaches to scaling.
00:26:09.760
To summarize our strategies, we implement thorough testing protocols, careful monitoring, and resilient coding practices to maintain high availability even during massive influxes of traffic. We must remain vigilant in our approach to scaled systems, adopting new tools and processes that anticipate potential failure points.
00:30:01.520
As I conclude, I hope my insights on scaling our Rails app during peak periods—such as Black Friday and Cyber Monday—have been informative. Thank you for your time!