00:00:11.880
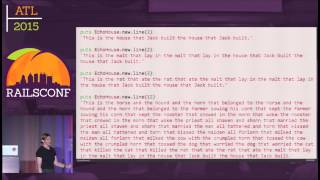
Hey everybody! Welcome! I want to say I'm really happy to be starting off the crafting code track of the conference. So let's just dive right into it. Here's an example of how a Rails app starts. It's a typical example you see in a design talk, but I'm not interested in this example. I want to turn this into the real-world schema that I saw at a client, which is a little more complicated.
00:00:30.359
It's not a mistake or a joke; this is a mature domain model for a complex real-world problem. This isn't even close to the full thing. You don't even see a user model in there. This is what those pretty little examples look like after a year or two, or five, of exposure to reality.
00:00:50.039
I think Rails has succeeded by promoting design conventions like organizing your code into specific folders, connecting your models with ActiveRecord, and using the MVC pattern. However, as our apps have grown bigger and older, this structure hasn't been sufficient to support them. Microservices, engines, and gems can break up our code, but I think they hurt most apps more than they help. I believe monoliths are great, and I want to help you create good ones today.
00:01:13.600
I want to talk to you about what happens next after you've used Rails to generate a few dozen times. What happens after you have a migration that only reverses a previous migration because a feature changed and then changed back? What happens when your test suite creeps above one minute, then ten, then twenty, with no end in sight? What happens when a small feature doesn't seem possible or when a small refactoring turns half your test suite red? What happens when MVC isn't enough to organize your code?
00:01:46.560
So, welcome! I'm Peter Harkins, a senior consultant at DevMind, which is a small consultancy in Chicago. I've worked with dozens of Rails apps in the last couple of years, and I have previously worked with Django and PHP. I've seen a broad range of experiences, from one place with 100 small sites to others with huge Rails apps that are not aging well.
00:02:11.440
As I mentioned on the title slide, I’m a bit camera shy, so please don’t post pictures of me online—it's an uninteresting personal situation. Just do me a little favor, thanks! You don’t even need to take photos of the screen; I’ll share all of the slides with verbatim speaker notes in case I get stage fright, which you can refer to after the talk.
00:02:21.840
So here’s the plan: we’re going to talk about the code we have now. I'm going to give you two rules for breaking it down in different ways, and we’ll explore what these rules imply for our code. I’ll end with some resources and tools you can use, and I’ll share links to more places where you can see good code.
00:02:39.640
The techniques we’re going to discuss apply to all of our code, but almost all the examples will come from the model layer. That’s where I see most of the problems with code quality. We have skinny controllers, which are great, but the models just keep growing, leading to this 'big ball of mud' in our models. This can have some tests, but they are unreliable, and this frustrates our efforts to add features or write good code.
00:03:02.280
I think ActiveRecord is a really well-written gem with many benefits for making apps. We have an ORM, a query builder, a factory for creating objects, and we can easily retrieve any model we need from the database. Validations are right there in our models, making them easy to find and change. Models are the obvious home for related code, but all these early benefits are mirrored by long-term drawbacks.
00:03:43.440
Those amazing tools allow us to put off painful design decisions until we've painted ourselves into a corner. Without hierarchy, we can have cyclic dependencies, leading to situations where we must create objects in an invalid state. Sometimes, these issues are hard to spot. Our models being always accessible means any part of our code can create, retrieve, and destroy models, which causes functionality to drift off into hooks and triggers. This is acceptable initially, but later, you may lose track of what other code might modify that model.
00:04:29.120
The easily accessible database acts like a global variable. This variable isn’t just shared between processes; it’s shared over time, and possibly even with different apps entirely. If you're integrating with a legacy system, you run into issues where validations in your code can easily allow invalid data to sneak in, leading to odd situations where previously valid records are retroactively marked as invalid. This scenario can create some real fun bugs.
00:05:19.560
Models continue to grow as we add new functionality, leading to accumulated business logic, validations, triggers, and ORM mappings. Over time, this behavior can make models feel like junk drawers for any vaguely related code. I want to clarify: I’m not saying ActiveRecord is a bad design; I think it’s good code. However, the advantages of ActiveRecord make it easy for us to write bad code, and we end up with no vocabulary to fix it.
00:05:41.199
So why does everything feel painful after a year or two, and can we resolve this without some overly complicated scheme that leaves our code looking weird and overdesigned? Today, I want to discuss how to escape this trap. We’ll begin with some really bad real-world code—I’ll take responsibility for that—and we will decompose it according to two explicit rules while discussing how to test the pieces.
00:06:29.720
The improvements we make will be incremental, can be partially applied, and can be reversed if you decide they are a bad idea. If a new developer joins and starts writing code without knowing the rules, it’s not like your codebase is going to instantly burst into flames. Let’s get into that example project. The project is called Shy, which is a website that archives mailing lists. The name is a portmanteau of Chicago and Library, as I’m from one and love the other.
00:07:33.080
Here’s an overview of a mailing list about game design and development. You don’t need to read it; I know it’s tiny, but you can see the structure. Up top, there’s a table of numbers showing each month’s count of how many threads and messages there are. Below, there’s a big text description of the list. I really enjoy reading mailing list discussions because there’s a lot of insightful information out there. I started Shy to facilitate this and also as an excuse to experiment with different databases and Ruby.
00:08:21.640
I’ll admit that when I started, I had no clue what I was doing with object-oriented design—this was some of the first OOP code I wrote. Looking back at the Git repo after the talk will make this obvious. However, it doesn’t look much worse than what I see at clients. I used Shy as a proving ground to experiment with OOP design for a year, and today I’ll share the successful results with you.
00:09:07.440
Clicking into one of those individual months reveals a list of discussion threads. You can see two of them expanded with the tree of individuals replying below. Within an individual thread, there's the tree repeated at the top alongside all of the messages. A significant feature for me is reading one discussion thread per page. I don’t want to view a keyhole version; I want to see everything. This required a lot of fun coding to sort and reparent the messages together while also dealing with bad data.
00:10:00.240
Now, let’s jump into the code for messages. I know you can’t read it, but this is the god object of the system. I’m not too embarrassed, as it’s only 300 lines long. I’ve seen models that are four or five times that size. Let’s zoom in at the top: it doesn’t inherit from ActiveRecord::Base because ActiveRecord was the only pattern I knew for database access.
00:10:28.040
This is a fine example of what ActiveRecord classes can turn into over time and how to decompose them. It starts off with a bunch of accessors, carrying all the fields you’d expect. There’s a regex and a method for normalizing data by removing extraneous junk when your uncle forwards you, that email about Obama fluoridating our water. Additionally, there’s a factory method for instantiating messages from a hash, among other complexities.
00:11:34.639
The constructor is complicated and confusing. A message can be fetched from the database by passing its database key, or it might be passed in as a large string, or even from another message object. It's a bit chaotic and should ideally have at least three factory methods to handle instantiation. A distracting element in the code is the call number variable, which serves as the unique ID for each message, but it's optional towards the end of the arguments.
00:12:07.360
As a workaround, I have an exception that prevents the message from existing in an unusable state for too long. There’s a nice idea here: objects shouldn’t be visible to the outside world in an invalid state. We’ll find a better expression for that later. At the end, the code extracts some metadata, like the subject, into instance variables.
00:12:30.679
Next, the program extracts the metadata by pulling in the subject, and if that fails, it falls back to a placeholder. Alongside this logic, it checks if the subject resembles a reply using the defined regex. There’s also an instance-level method calling a class method, and the sequence continues.
00:12:59.999
We’ve already encountered sufficient examples for the remaining talk, and we’ll extract those clusters of related code working on the same variables into objects, which we’ll call values. I promised you two rules, so let’s discuss them and apply them to this code. The first rule is that values should be immutable. When we call a method, we want to be assured it will return the same answer each time.
00:13:24.360
Unlike the message object, which might return different subjects after yielding to other code, values should provide referential transparency. For example, integers are immutable: when you add one to three, you get a new four without altering three itself. Similarly, while we may have mutable date variables, the date itself doesn’t change.
00:14:00.559
Code that’s immutable cannot invoke mutable code, for if it did, it couldn't guarantee consistency. The second rule is that values should not have side effects. They should only return results without interacting with external systems, such as databases or APIs. If a method calls code with side effects, then we’d consider it mutable as well.
00:14:42.159
So let’s make those two rules concrete by extracting some values from that message code. The call number is now a proper class since it serves as the unique key for each message in Shy. It’s critical for these values to be valid and correct, and this class enforces that validity. An immutable value must never occupy an invalid state as it could never switch to one that is valid.
00:15:00.799
If an object can exist in an invalid state, every method utilizing that object must determine which it’s receiving—valid or invalid—therefore behaving differently based on that. This violates the Liskov Substitution Principle since methods can’t depend on the behavior of a reusable component if it might change.
00:15:32.079
Finally, the call number utilizes a little gem called 'adamantium'; after the initializer method, the object is frozen, causing any attempts to mutate a call number to raise exceptions. If you’ve used the freeze method in Ruby, there might be a few quirks, but adamantium handles immutability well.
00:16:03.440
Next, let’s look at the second value we’ll extract from messages: the subject. This starts simply, wrapping a string, and like call number, it uses adamantium to maintain immutability. It employs the standard library’s forwardable module to delegate some methods, enabling the subject to report attributes like its length or act as a sortable entity.
00:16:41.560
It also utilizes Equalizer, another fantastic gem that takes a set of attributes to generate methods for equality comparison and hashing, should we need to use it as a hash key. It’s odd to me how few of our default Rails classes implement basic Ruby interfaces regarding equality and hashing. I wonder if this suggests we might be too reliant on the framework.
00:17:20.440
We double-check the back half of the subject, which includes several methods, including the regex and relevant code. Now, all code related to the subject lives in the Subject object. You can directly ask a Subject if it has been normalized without calling a class method on the message. We started breaking down our ActiveRecord models into less complex components by identifying and isolating related methods.
00:18:05.920
This design pattern is called Extract Class Refactoring. There’s nothing inherently special about making these classes values; we want to make them immutable and remove their side effects. It doesn’t imply that a method can’t possess a local variable as those often serve as manageable placeholders, yet externally they should remain inconspicuous.
00:19:03.040
Extracting values means we want to also implement common Ruby methods on these subjects, not to mention any lesser-known methods if the values can substitute for other primitive types, like turning a subject into a string. Initially, you may be tempted to have values return ActiveRecord objects, but it's crucial to avoid that. A value can’t confidently declare it’s immutable, nor can it guard against side effects if it accesses methods on another mutable object.
00:19:43.600
The simplest method for a value residing within an ActiveRecord model is to establish its own getter and setter. A subject, for instance, can save itself to a varchar column by using either Rails' 'composed_of' or the new attributes API with Rails 5.
00:20:18.040
For more complex values made up of multiple components—like a street address value that might consist of a country—you could either save it to multiple columns or have it stored in its own table reached through a foreign key. You simply continue modeling your tables in the most intuitive manner possible. Nothing changes at the database layer; this is simply object-oriented design.
00:20:52.200
When testing these values, we can proceed without depending on many conditions. Since they are small and predictable, if a value is constructed from other values, it becomes trivial for our tests to integrate through them. We avoid mocks and stubs since there’s no need to verify that side effects will and won’t occur; we only write assertions on the method returns.
00:21:35.680
Additionally, we can engage in fascinating tasks like automatically generating property-based tests, although I don’t have time to elaborate on that right now. In essence, values are immutable and devoid of side effects; they’re often quite small. I’m sure you’ve deduced that we’ll fill in the remainder of this chart later, but it will go much quicker since we are only relaxing those two rules.
00:22:08.000
This brings us to the halfway point of the talk. I realize I threw a lot at you all at once—like my cat after bath time! Generally, though, most attendees seem undeterred. This is a good moment to take a breath. If you have questions, feel free to wave at me now.
00:22:41.200
Okay, we will continue. Next, we’ll discuss email as another value object. Here’s an example that dissects the raw string of an email into component values. We can see three strategies in action: first, the message ID extracts the message ID header, constructing a value. That’s quite straightforward.
00:23:26.320
Second, the subject pulls from the subject header or defaults to a placeholder if missing. It’ll also build its own value. Lastly, the from fields will extract an address string—I glanced through the code and determined that there isn't much to do with the address, so it remains a simple string. Not every element has to be treated as a value; we extract values because they mitigate complexity; this is practical design, not dogma.
00:24:23.040
These values don’t possess identities. If you have two subjects that are equal, it doesn’t matter which variable you employ; they’ll return the same value. This stands in contrast to physical entities. If you discover another Peter Harkins, it matters that we hold individual identities, even if we share names, addresses, or other attributes. The reverse remains true as well: irrespective of changing my name, address, or phone number, identity remains constant.
00:25:05.680
This leads to a distinction: we need something separate from values—a concept I’ll call entities. Entities are mutable objects with identity, yet like values, entities don’t exhibit side effects. Let’s examine two examples. First, we’ll have the new message class, which now excludes those value objects and thinly comprises the message ID.
00:25:50.080
Message gets thin; it's initialized with the call number unique ID we've extracted. Email, meanwhile, is mutable since it might gain an updated copy of itself from a different archive. Additionally, the slug represents the ID for the mailing list and requires mutability since it could be associated with two lists at once. For clarity, while email can change, the email itself doesn’t; this highlights the difference between a variable and its stored value.
00:26:39.640
Next, we’ll discuss the list entity, which shares a similar format. The slug and mutable fields are defined, employing Equalizer for utility. Entities usually contain little code—primarily identity and value wrapping—hoping it avoids duplication of business rule decisions.
00:27:19.040
You may be pondering that the concept of an entity sounds very close to an ActiveRecord model. While the two are similar, the principal difference is that ActiveRecord models are rife with side effects. Call a model, and we can’t be sure if it will trigger a save, reload an association, or enter some new web of models with unknown results. This talk focuses on extraction of entities from existing models to improve maintainability.
00:27:54.960
To extract entities from models or refurbish existing ones to resemble entities, we can follow steps we’ve already detailed: identify their identities, extract mutable values, and push side effects down to adapters and shells. If we plan to use ActiveRecord models as entities, we need to navigate the side effects appropriately. This segment of the talk might sound counterintuitive.
00:28:39.840
I propose avoiding direct calls to ActiveRecord or its lifecycle methods that might introduce side effects. This might deviate from the typical ActiveRecord design pattern, but it cultivates a cleaner structure by raising side effects into adapters and separating them from our model layer. If our methods exhibit side effects, we quickly lose clarity about what’s occurring.
00:29:19.800
It’s acceptable to use direct calls to the database, but we want to avoid placing all the logic in one messy area. Testing methods belonging to entities means applying several additional tools, such as factories and stubs. If you find yourself depending on them excessively, it’s a signal your code may be poorly structured. FactoryGirl is commonly used, and we might see it saving ten records to test a single small method due to the model's numerous side effects.
00:30:07.360
We tend to validate the outcomes post-method-call instead of validating return values, ensuring an entity is in the correct state afterward. They’re mutable, possessing no side effects, and the immutable values cannot invoke mutable entities without risking their own integrity. This reinforces a natural hierarchy among our objects.
00:30:59.600
On a final note, I want to introduce the term 'adapters.' Adapters are essentially immutable objects that have side effects. For instance, we have our Run ID service, required to generate unique call numbers in the system, which isn't stored in an SQL database.
00:31:26.960
Despite having side effects, applying some flexibility within the rules can lead to advantageous designs.
00:31:38.240
These adapters typically wrap around external services and can be tested using stubs to produce outcomes for external service calls. Recall that values and entities can’t invoke adapters; only adapters can engage with them.
00:32:00.640
Lastly, I’ll summarize our discussion of shells. These coordinate specialized objects to conduct meaningful work and manage dependencies. In terms of testing shells, we utilize all our available tools, including fixtures for real-world scenario testing—especially focusing on invalid scenarios.
00:32:29.760
I’ll craft end-to-end tests—one predictable success test—and as needed, regression tests during bug fixes. However, I’ll focus on breaking things down to write isolated code, particularly emphasizing contract and collaboration tests.
00:33:03.920
One pressing thought remains on your mind: how does this integrate with existing Rails applications? Almost all code tends to be mutable, which results in side effects especially concerning database access. It’s an unruly codebase where tracking execution paths becomes cumbersome.
00:33:34.640
This disorganized environment compels us to apply testing methodologies to all layers effectively, hence why I've noted many great references digesting concepts.
00:34:08.560
I’ve gathered these experiments and insights to sculpt rules for decomposing code throughout my career. I feel privileged to share these regulations, which can aid you in simplifying your code into reliable, manageable components. They’ve proven instrumental in non-trivial projects and among client codes.
00:34:50.560
Here are some valuable tools I’ve employed through this learning curve, but I wish I had time to demonstrate each one thoroughly. You can explore the Shy app on my GitHub, which showcases these principles even if they aren’t applied either overtly or rigorously.
00:35:29.120
In conclusion, if you're eager to delve deeper into this subject, I welcome you to reach out with your own experiments—whether they turn out successfully or not. My name is Peter Harkins, and I appreciate your time and kind attention today.
00:36:09.760
Let’s open the floor for any questions!